Binaural Selective Attention Model for Target Speaker Extraction

0
Sign in to get full access
Overview
- This paper proposes a binaural selective attention model for extracting a target speaker's voice from a mixed audio signal.
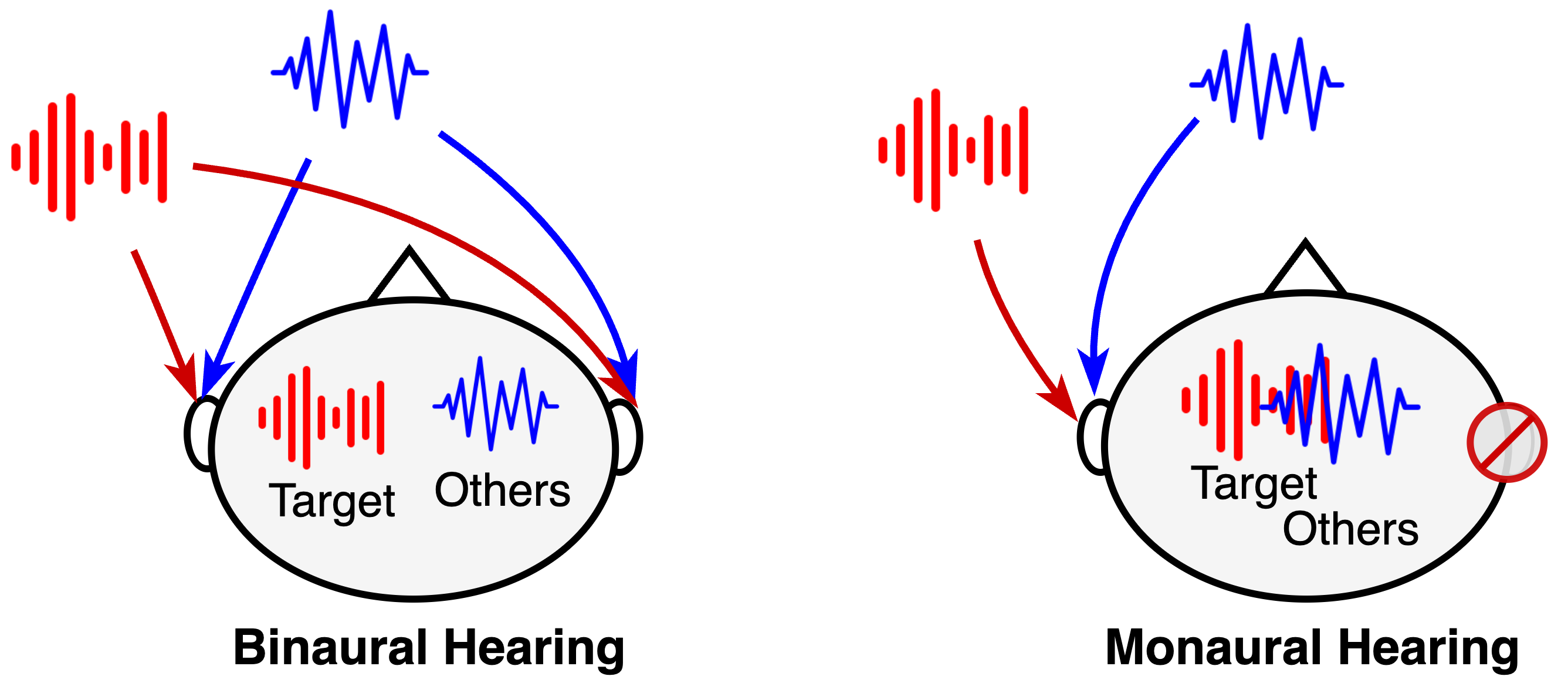
- The model uses binaural cues (differences in sound between the left and right ears) to focus on the target speaker.
- The system is designed to work in real-world scenarios with multiple speakers and background noise.
Plain English Explanation
When we're in a noisy environment with multiple people talking, it can be hard to focus on what one person is saying. This binaural selective attention model aims to solve that problem by extracting the voice of a specific target speaker from the mixed audio signal.
The key insight is that our two ears perceive sounds slightly differently - this is known as binaural cues. The model uses these binaural differences to identify and isolate the target speaker's voice, even when there are other speakers and background noise present.
By leveraging these binaural cues, the system is able to perform "selective attention" and hone in on the target speaker, allowing you to clearly hear what they are saying while tuning out the other voices and ambient noise. This could be very useful in scenarios like meetings, lectures, or noisy public places where you want to focus on a particular conversation.
Technical Explanation
The binaural selective attention model takes a mixed audio signal containing multiple speakers and background noise as input. It then uses a deep neural network architecture to extract the target speaker's voice.
The key components of the system are:
- Binaural feature extraction: The model takes the left and right channel audio signals and extracts features that capture binaural cues like inter-aural time and level differences.
- Attention mechanism: An attention module learns to focus on the regions of the audio that are most relevant to the target speaker based on the binaural features.
- Speaker extraction: The attended features are then used to reconstruct the target speaker's voice, separating it from the other sources in the mixed audio.
The model is trained end-to-end on datasets of mixed audio signals, learning to accurately extract the target speaker even in complex acoustic environments.
Critical Analysis
The binaural selective attention model is a novel and promising approach to the challenging problem of target speaker extraction. By leveraging binaural cues, it is able to focus on a specific speaker in a way that could be very useful in real-world applications.
However, the paper does not address some potential limitations of the approach. For example, the model may struggle if the target speaker's position relative to the microphones changes significantly during the recording. Additionally, the performance of the system could degrade in scenarios with very large numbers of speakers or extremely noisy environments.
Further research would be needed to fully understand the robustness and generalization capabilities of the model. Comparisons to other state-of-the-art techniques for speaker extraction would also help to contextualize the contributions of this work.
Overall, this binaural selective attention model represents an interesting and impactful approach to an important problem in audio processing. With continued development and evaluation, it could lead to significant advancements in areas like speech recognition, teleconferencing, and human-computer interaction.
Conclusion
The binaural selective attention model proposed in this paper offers a novel way to extract a target speaker's voice from a mixed audio signal. By leveraging binaural cues, the model is able to focus on the desired speaker even in the presence of other voices and background noise.
This technique could have broad applications in fields like speech recognition, teleconferencing, and human-computer interaction, where being able to clearly isolate a target speaker is crucial. While the paper highlights the promise of this approach, further research is needed to fully understand its limitations and potential.
Overall, this work represents an important step forward in the ongoing effort to develop robust and practical solutions for target speaker extraction in complex real-world environments.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Binaural Selective Attention Model for Target Speaker Extraction
Hanyu Meng, Qiquan Zhang, Xiangyu Zhang, Vidhyasaharan Sethu, Eliathamby Ambikairajah
The remarkable ability of humans to selectively focus on a target speaker in cocktail party scenarios is facilitated by binaural audio processing. In this paper, we present a binaural time-domain Target Speaker Extraction model based on the Filter-and-Sum Network (FaSNet). Inspired by human selective hearing, our proposed model introduces target speaker embedding into separators using a multi-head attention-based selective attention block. We also compared two binaural interaction approaches -- the cosine similarity of time-domain signals and inter-channel correlation in learned spectral representations. Our experimental results show that our proposed model outperforms monaural configurations and state-of-the-art multi-channel target speaker extraction models, achieving best-in-class performance with 18.52 dB SI-SDR, 19.12 dB SDR, and 3.05 PESQ scores under anechoic two-speaker test configurations.
Read more6/19/2024

0
Audio-Visual Target Speaker Extraction with Reverse Selective Auditory Attention
Ruijie Tao, Xinyuan Qian, Yidi Jiang, Junjie Li, Jiadong Wang, Haizhou Li
Audio-visual target speaker extraction (AV-TSE) aims to extract the specific person's speech from the audio mixture given auxiliary visual cues. Previous methods usually search for the target voice through speech-lip synchronization. However, this strategy mainly focuses on the existence of target speech, while ignoring the variations of the noise characteristics. That may result in extracting noisy signals from the incorrect sound source in challenging acoustic situations. To this end, we propose a novel reverse selective auditory attention mechanism, which can suppress interference speakers and non-speech signals to avoid incorrect speaker extraction. By estimating and utilizing the undesired noisy signal through this mechanism, we design an AV-TSE framework named Subtraction-and-ExtrAction network (SEANet) to suppress the noisy signals. We conduct abundant experiments by re-implementing three popular AV-TSE methods as the baselines and involving nine metrics for evaluation. The experimental results show that our proposed SEANet achieves state-of-the-art results and performs well for all five datasets. We will release the codes, the models and data logs.
Read more5/9/2024

0
NeuroSpex: Neuro-Guided Speaker Extraction with Cross-Modal Attention
Dashanka De Silva, Siqi Cai, Saurav Pahuja, Tanja Schultz, Haizhou Li
In the study of auditory attention, it has been revealed that there exists a robust correlation between attended speech and elicited neural responses, measurable through electroencephalography (EEG). Therefore, it is possible to use the attention information available within EEG signals to guide the extraction of the target speaker in a cocktail party computationally. In this paper, we present a neuro-guided speaker extraction model, i.e. NeuroSpex, using the EEG response of the listener as the sole auxiliary reference cue to extract attended speech from monaural speech mixtures. We propose a novel EEG signal encoder that captures the attention information. Additionally, we propose a cross-attention (CA) mechanism to enhance the speech feature representations, generating a speaker extraction mask. Experimental results on a publicly available dataset demonstrate that our proposed model outperforms two baseline models across various evaluation metrics.
Read more9/17/2024

0
Spectron: Target Speaker Extraction using Conditional Transformer with Adversarial Refinement
Tathagata Bandyopadhyay
Recently, attention-based transformers have become a de facto standard in many deep learning applications including natural language processing, computer vision, signal processing, etc.. In this paper, we propose a transformer-based end-to-end model to extract a target speaker's speech from a monaural multi-speaker mixed audio signal. Unlike existing speaker extraction methods, we introduce two additional objectives to impose speaker embedding consistency and waveform encoder invertibility and jointly train both speaker encoder and speech separator to better capture the speaker conditional embedding. Furthermore, we leverage a multi-scale discriminator to refine the perceptual quality of the extracted speech. Our experiments show that the use of a dual path transformer in the separator backbone along with proposed training paradigm improves the CNN baseline by $3.12$ dB points. Finally, we compare our approach with recent state-of-the-arts and show that our model outperforms existing methods by $4.1$ dB points on an average without creating additional data dependency.
Read more9/4/2024