A New Theoretical Perspective on Data Heterogeneity in Federated Optimization

0
📊
Sign in to get full access
Overview
- Federated learning (FL) is a decentralized machine learning approach where data is stored locally on devices instead of a central server.
- Data heterogeneity is the main challenge in FL, as it can negatively impact the convergence rate of many FL algorithms.
- Existing theoretical analyses are pessimistic about the convergence rate, especially when the number of local updates is large.
- However, empirical studies suggest that more local updates can improve convergence, which is inconsistent with theoretical findings.
Plain English Explanation
In traditional machine learning, data is stored and processed on a central server. Federated learning (FL) is a new approach where the data remains on individual devices, and the model is trained collaboratively without sharing the raw data. This is useful for privacy-sensitive applications where the data cannot be centralized.
One of the main challenges in FL is data heterogeneity, which means the data on different devices can be very different. Existing theoretical analyses have suggested that data heterogeneity can significantly slow down the convergence of many FL algorithms, especially when the number of local updates (training steps on each device) is large.
However, empirical studies have shown that performing more local updates can actually improve the convergence rate, even when the data is highly heterogeneous. This discrepancy between theory and practice is the focus of this research paper.
Technical Explanation
The paper proposes a new theoretical framework for analyzing the impact of data heterogeneity on FL convergence. Instead of the standard local Lipschitz gradient assumption, the authors introduce a "heterogeneity-driven pseudo-Lipschitz" assumption, which is a weaker and more realistic constraint.
By deriving a new convergence upper bound for the popular FedAvg algorithm and its extensions, the paper shows that the convergence rate is now primarily dependent on the heterogeneity-driven pseudo-Lipschitz constant, which is typically much smaller than the local Lipschitz constant used in previous analyses.
This allows the convergence upper bound to be significantly reduced, although its overall order remains the same. The paper also provides additional insights when the local objective function is quadratic, identifying a region where FedAvg can outperform mini-batch stochastic gradient descent (SGD) even when the gradient divergence is arbitrarily large.
Critical Analysis
The paper provides a novel theoretical framework for analyzing data heterogeneity in FL, which helps bridge the gap between the pessimistic theoretical predictions and the more optimistic empirical observations. By introducing the heterogeneity-driven pseudo-Lipschitz assumption, the authors have developed a more realistic model of the impact of data heterogeneity.
However, the paper does not address all the potential limitations of this new assumption. For example, it would be valuable to understand the practical implications of this assumption and how it compares to the original local Lipschitz gradient assumption in terms of ease of verification and tightness of the resulting bounds.
Additionally, the paper focuses on the FedAvg algorithm and its extensions, but it would be interesting to see how the proposed framework could be applied to other FL algorithms, such as those that address group bias or improve robustness to heterogeneity.
Conclusion
This paper presents a new theoretical framework for analyzing the impact of data heterogeneity on the convergence of federated learning algorithms. By introducing a weaker "heterogeneity-driven pseudo-Lipschitz" assumption, the authors have been able to derive tighter convergence bounds that better match empirical observations, where more local updates can improve performance even in the presence of significant data heterogeneity.
This work represents an important step towards bridging the gap between theory and practice in federated learning, and the insights provided could help guide the design of more effective and efficient federated learning algorithms for real-world applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
📊
0
A New Theoretical Perspective on Data Heterogeneity in Federated Optimization
Jiayi Wang, Shiqiang Wang, Rong-Rong Chen, Mingyue Ji
In federated learning (FL), data heterogeneity is the main reason that existing theoretical analyses are pessimistic about the convergence rate. In particular, for many FL algorithms, the convergence rate grows dramatically when the number of local updates becomes large, especially when the product of the gradient divergence and local Lipschitz constant is large. However, empirical studies can show that more local updates can improve the convergence rate even when these two parameters are large, which is inconsistent with the theoretical findings. This paper aims to bridge this gap between theoretical understanding and practical performance by providing a theoretical analysis from a new perspective on data heterogeneity. In particular, we propose a new and weaker assumption compared to the local Lipschitz gradient assumption, named the heterogeneity-driven pseudo-Lipschitz assumption. We show that this and the gradient divergence assumptions can jointly characterize the effect of data heterogeneity. By deriving a convergence upper bound for FedAvg and its extensions, we show that, compared to the existing works, local Lipschitz constant is replaced by the much smaller heterogeneity-driven pseudo-Lipschitz constant and the corresponding convergence upper bound can be significantly reduced for the same number of local updates, although its order stays the same. In addition, when the local objective function is quadratic, more insights on the impact of data heterogeneity can be obtained using the heterogeneity-driven pseudo-Lipschitz constant. For example, we can identify a region where FedAvg can outperform mini-batch SGD even when the gradient divergence can be arbitrarily large. Our findings are validated using experiments.
Read more7/23/2024

0
Synthetic data shuffling accelerates the convergence of federated learning under data heterogeneity
Bo Li, Yasin Esfandiari, Mikkel N. Schmidt, Tommy S. Alstr{o}m, Sebastian U. Stich
In federated learning, data heterogeneity is a critical challenge. A straightforward solution is to shuffle the clients' data to homogenize the distribution. However, this may violate data access rights, and how and when shuffling can accelerate the convergence of a federated optimization algorithm is not theoretically well understood. In this paper, we establish a precise and quantifiable correspondence between data heterogeneity and parameters in the convergence rate when a fraction of data is shuffled across clients. We prove that shuffling can quadratically reduce the gradient dissimilarity with respect to the shuffling percentage, accelerating convergence. Inspired by the theory, we propose a practical approach that addresses the data access rights issue by shuffling locally generated synthetic data. The experimental results show that shuffling synthetic data improves the performance of multiple existing federated learning algorithms by a large margin.
Read more4/9/2024
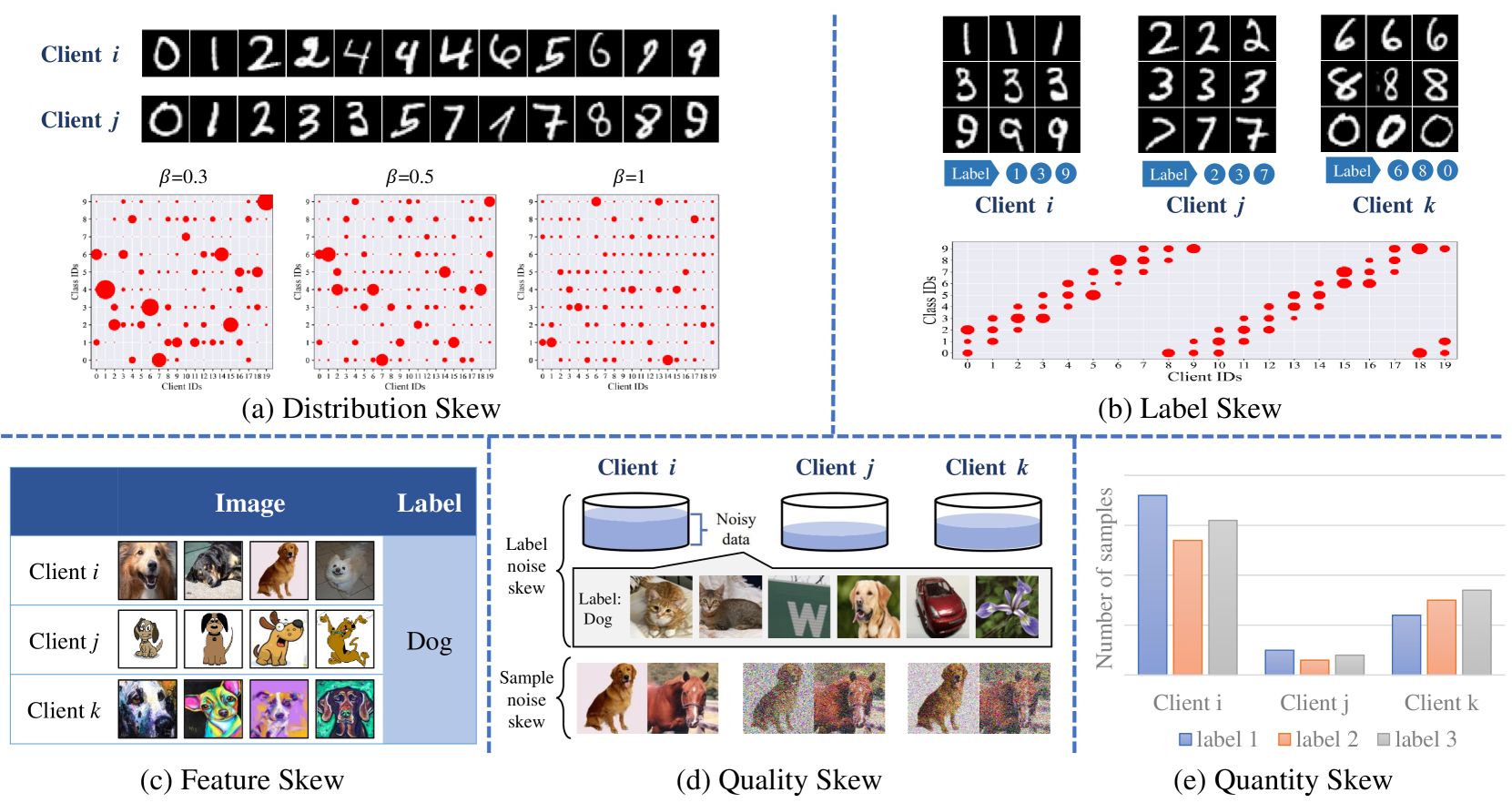
0
Advances in Robust Federated Learning: Heterogeneity Considerations
Chuan Chen, Tianchi Liao, Xiaojun Deng, Zihou Wu, Sheng Huang, Zibin Zheng
In the field of heterogeneous federated learning (FL), the key challenge is to efficiently and collaboratively train models across multiple clients with different data distributions, model structures, task objectives, computational capabilities, and communication resources. This diversity leads to significant heterogeneity, which increases the complexity of model training. In this paper, we first outline the basic concepts of heterogeneous federated learning and summarize the research challenges in federated learning in terms of five aspects: data, model, task, device, and communication. In addition, we explore how existing state-of-the-art approaches cope with the heterogeneity of federated learning, and categorize and review these approaches at three different levels: data-level, model-level, and architecture-level. Subsequently, the paper extensively discusses privacy-preserving strategies in heterogeneous federated learning environments. Finally, the paper discusses current open issues and directions for future research, aiming to promote the further development of heterogeneous federated learning.
Read more5/17/2024

0
On the Impact of Data Heterogeneity in Federated Learning Environments with Application to Healthcare Networks
Usevalad Milasheuski, Luca Barbieri, Bernardo Camajori Tedeschini, Monica Nicoli, Stefano Savazzi
Federated Learning (FL) allows multiple privacy-sensitive applications to leverage their dataset for a global model construction without any disclosure of the information. One of those domains is healthcare, where groups of silos collaborate in order to generate a global predictor with improved accuracy and generalization. However, the inherent challenge lies in the high heterogeneity of medical data, necessitating sophisticated techniques for assessment and compensation. This paper presents a comprehensive exploration of the mathematical formalization and taxonomy of heterogeneity within FL environments, focusing on the intricacies of medical data. In particular, we address the evaluation and comparison of the most popular FL algorithms with respect to their ability to cope with quantity-based, feature and label distribution-based heterogeneity. The goal is to provide a quantitative evaluation of the impact of data heterogeneity in FL systems for healthcare networks as well as a guideline on FL algorithm selection. Our research extends beyond existing studies by benchmarking seven of the most common FL algorithms against the unique challenges posed by medical data use cases. The paper targets the prediction of the risk of stroke recurrence through a set of tabular clinical reports collected by different federated hospital silos: data heterogeneity frequently encountered in this scenario and its impact on FL performance are discussed.
Read more9/6/2024