Synthetic data shuffling accelerates the convergence of federated learning under data heterogeneity
2306.13263
0
0

Abstract
In federated learning, data heterogeneity is a critical challenge. A straightforward solution is to shuffle the clients' data to homogenize the distribution. However, this may violate data access rights, and how and when shuffling can accelerate the convergence of a federated optimization algorithm is not theoretically well understood. In this paper, we establish a precise and quantifiable correspondence between data heterogeneity and parameters in the convergence rate when a fraction of data is shuffled across clients. We prove that shuffling can quadratically reduce the gradient dissimilarity with respect to the shuffling percentage, accelerating convergence. Inspired by the theory, we propose a practical approach that addresses the data access rights issue by shuffling locally generated synthetic data. The experimental results show that shuffling synthetic data improves the performance of multiple existing federated learning algorithms by a large margin.
Create account to get full access
Overview
- This paper explores a novel approach to accelerating the convergence of federated learning in the presence of data heterogeneity.
- The key idea is to use synthetic data shuffling to improve the performance of federated learning models.
- The researchers conduct experiments to demonstrate the effectiveness of their approach and provide insights into the benefits it offers.
Plain English Explanation
In federated learning, multiple devices or organizations collaborate to train a machine learning model without sharing their raw data. This is useful when data is sensitive or distributed across different locations. However, when the data on these devices is very different (heterogeneous), it can slow down the training process and make it harder for the model to converge.
The researchers in this paper propose a solution to this problem: synthetic data shuffling. They create artificial, or synthetic, data samples and then use these to "shuffle" the training data across the different devices. This helps to smooth out the differences in the real data and make the training process more efficient.
The key benefit of this approach is that it can accelerate the convergence of the federated learning model, meaning it reaches a high-performing state faster. This is especially useful in scenarios where data is very heterogeneous across devices, such as when different organizations or individuals have vastly different data.
By using synthetic data shuffling, the researchers were able to demonstrate significant improvements in the performance and convergence speed of federated learning models, even in the presence of highly heterogeneous data. This could have important implications for real-world applications of federated learning, where data diversity is often a challenge.
Technical Explanation
The paper presents a novel approach to improving the performance of federated learning in the presence of data heterogeneity. The key idea is to leverage synthetic data shuffling to accelerate the convergence of the federated learning model.
The researchers first generate synthetic data samples using a generative adversarial network (GAN). They then use these synthetic samples to "shuffle" the training data across the different devices participating in the federated learning process. This helps to mitigate the negative effects of data heterogeneity, where each device may have very different data distributions.
Through extensive experiments, the authors demonstrate that their approach of synthetic data shuffling can significantly improve the convergence speed and performance of federated learning models, even in scenarios with highly heterogeneous data across devices.
The core insight is that by introducing synthetic data that bridges the gaps between the real data distributions on different devices, the federated learning algorithm can more effectively learn a global model that generalizes well. This helps to overcome the vanishing variance problem that can occur in federated learning with heterogeneous data.
Critical Analysis
The paper presents a promising approach to addressing a significant challenge in federated learning: data heterogeneity. The researchers demonstrate compelling results and provide valuable insights into the benefits of synthetic data shuffling.
However, it's important to note that the technique relies on the ability to generate high-quality synthetic data that can effectively capture the relevant characteristics of the real data distributions. In practice, this may be non-trivial, especially for complex, high-dimensional data.
Additionally, the paper does not discuss the potential privacy implications of introducing synthetic data into the federated learning process. It would be important to carefully consider any potential risks or trade-offs in this regard.
Further research may also be needed to understand the robustness of the approach to different types of data heterogeneity, as well as its scalability to larger, more complex federated learning scenarios.
Conclusion
This paper presents a novel approach to accelerating the convergence of federated learning models in the presence of data heterogeneity. By leveraging synthetic data shuffling, the researchers demonstrate significant improvements in the performance and convergence speed of federated learning, even when the data is highly diverse across different devices.
The findings of this study have important implications for the real-world deployment of federated learning, where data heterogeneity is often a major challenge. By addressing this issue, the proposed technique could help to unlock the full potential of federated learning in a wide range of applications, from healthcare to finance to edge computing.
Overall, this work represents an important contribution to the ongoing research efforts in the field of federated learning, offering a promising solution to a critical problem and paving the way for further advancements in this rapidly evolving area of machine learning.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
Improved Modelling of Federated Datasets using Mixtures-of-Dirichlet-Multinomials
Jonathan Scott, 'Aine Cahill
0
0
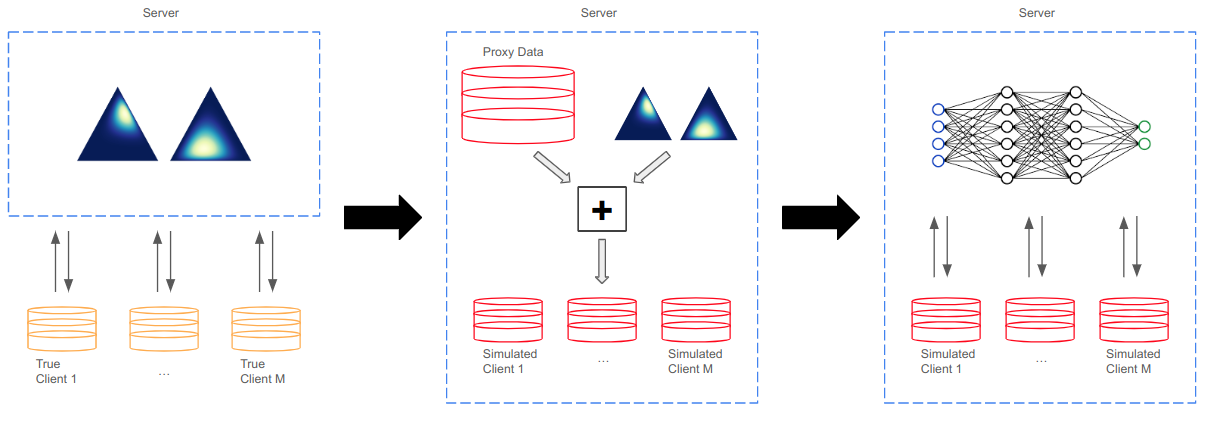
In practice, training using federated learning can be orders of magnitude slower than standard centralized training. This severely limits the amount of experimentation and tuning that can be done, making it challenging to obtain good performance on a given task. Server-side proxy data can be used to run training simulations, for instance for hyperparameter tuning. This can greatly speed up the training pipeline by reducing the number of tuning runs to be performed overall on the true clients. However, it is challenging to ensure that these simulations accurately reflect the dynamics of the real federated training. In particular, the proxy data used for simulations often comes as a single centralized dataset without a partition into distinct clients, and partitioning this data in a naive way can lead to simulations that poorly reflect real federated training. In this paper we address the challenge of how to partition centralized data in a way that reflects the statistical heterogeneity of the true federated clients. We propose a fully federated, theoretically justified, algorithm that efficiently learns the distribution of the true clients and observe improved server-side simulations when using the inferred distribution to create simulated clients from the centralized data.
6/5/2024
Advances in Robust Federated Learning: Heterogeneity Considerations
Chuan Chen, Tianchi Liao, Xiaojun Deng, Zihou Wu, Sheng Huang, Zibin Zheng
0
0
In the field of heterogeneous federated learning (FL), the key challenge is to efficiently and collaboratively train models across multiple clients with different data distributions, model structures, task objectives, computational capabilities, and communication resources. This diversity leads to significant heterogeneity, which increases the complexity of model training. In this paper, we first outline the basic concepts of heterogeneous federated learning and summarize the research challenges in federated learning in terms of five aspects: data, model, task, device, and communication. In addition, we explore how existing state-of-the-art approaches cope with the heterogeneity of federated learning, and categorize and review these approaches at three different levels: data-level, model-level, and architecture-level. Subsequently, the paper extensively discusses privacy-preserving strategies in heterogeneous federated learning environments. Finally, the paper discusses current open issues and directions for future research, aiming to promote the further development of heterogeneous federated learning.
5/17/2024

Navigating High-Degree Heterogeneity: Federated Learning in Aerial and Space Networks
Fan Dong, Henry Leung, Steve Drew
0
0
Federated learning offers a compelling solution to the challenges of networking and data privacy within aerial and space networks by utilizing vast private edge data and computing capabilities accessible through drones, balloons, and satellites. While current research has focused on optimizing the learning process, computing efficiency, and minimizing communication overhead, the issue of heterogeneity and class imbalance remains a significant barrier to rapid model convergence. In our study, we explore the influence of heterogeneity on class imbalance, which diminishes performance in ASN-based federated learning. We illustrate the correlation between heterogeneity and class imbalance within grouped data and show how constraints such as battery life exacerbate the class imbalance challenge. Our findings indicate that ASN-based FL faces heightened class imbalance issues even with similar levels of heterogeneity compared to other scenarios. Finally, we analyze the impact of varying degrees of heterogeneity on FL training and evaluate the efficacy of current state-of-the-art algorithms under these conditions. Our results reveal that the heterogeneity challenge is more pronounced in ASN-based federated learning and that prevailing algorithms often fail to effectively address high levels of heterogeneity.
6/27/2024
🤔
Towards Understanding and Mitigating Dimensional Collapse in Heterogeneous Federated Learning
Yujun Shi, Jian Liang, Wenqing Zhang, Vincent Y. F. Tan, Song Bai
0
0
Federated learning aims to train models collaboratively across different clients without the sharing of data for privacy considerations. However, one major challenge for this learning paradigm is the {em data heterogeneity} problem, which refers to the discrepancies between the local data distributions among various clients. To tackle this problem, we first study how data heterogeneity affects the representations of the globally aggregated models. Interestingly, we find that heterogeneous data results in the global model suffering from severe {em dimensional collapse}, in which representations tend to reside in a lower-dimensional space instead of the ambient space. Moreover, we observe a similar phenomenon on models locally trained on each client and deduce that the dimensional collapse on the global model is inherited from local models. In addition, we theoretically analyze the gradient flow dynamics to shed light on how data heterogeneity result in dimensional collapse for local models. To remedy this problem caused by the data heterogeneity, we propose {sc FedDecorr}, a novel method that can effectively mitigate dimensional collapse in federated learning. Specifically, {sc FedDecorr} applies a regularization term during local training that encourages different dimensions of representations to be uncorrelated. {sc FedDecorr}, which is implementation-friendly and computationally-efficient, yields consistent improvements over baselines on standard benchmark datasets. Code: https://github.com/bytedance/FedDecorr.
4/9/2024