NewsUnfold: Creating a News-Reading Application That Indicates Linguistic Media Bias and Collects Feedback

0
🛠️
Sign in to get full access
Overview
- Media bias is a complex issue that leads to one-sided views and impacts decision-making.
- Detecting and indicating digital media bias automatically using machine learning methods can help address this problem.
- However, effective bias detection is hindered by the difficulty of obtaining reliable training data.
- Human-in-the-loop feedback mechanisms have proven to be an effective way to facilitate the data-gathering process.
Plain English Explanation
The provided paper discusses the problem of media bias, which occurs when news sources present information in a way that favors a particular perspective or narrative. This can lead to people forming one-sided views and making decisions based on incomplete or biased information.
One way to address this issue is to use machine learning to automatically detect and indicate media bias within digital news articles. However, this approach is limited by the difficulty of obtaining reliable training data for the machine learning models.
The paper introduces a solution to this problem: human-in-the-loop feedback mechanisms. These are systems that allow human readers to provide feedback on the machine-generated bias highlights within news articles. This feedback is then used to improve the quality of the training data and the performance of the bias detection models.
The researchers implemented this approach in a news-reading web application called NewsUnfold. They found that the feedback mechanism significantly increased the inter-annotator agreement (a measure of how consistently humans identify bias) by 26.31% and improved the classifier performance by 2.49%.
Overall, the paper demonstrates that a user-centric approach to media bias data collection can provide reliable data while being scalable and easy to use. This suggests that feedback mechanisms are a promising strategy to reduce the costs of data collection and continuously update datasets to reflect changes in the media landscape.
Technical Explanation
The paper introduces a novel approach to address the challenge of obtaining reliable training data for automatic media bias detection systems. The researchers developed a human-in-the-loop feedback mechanism that allows readers to provide feedback on machine-generated bias highlights within online news articles.
The researchers implemented this feedback mechanism in a news-reading web application called NewsUnfold. The application presents users with news articles and machine-generated bias highlights, and allows them to provide feedback on the accuracy and relevance of the highlights.
The researchers then used this feedback to augment the training dataset for their media bias detection models. They found that this approach significantly increased the inter-annotator agreement (a measure of how consistently humans identify bias) by 26.31% and improved the classifier performance by 2.49%.
The paper presents the NewsUnfold system as the first human-in-the-loop application for media bias detection. The researchers evaluated the feedback mechanism and found that it was perceived as easy to use by participants. They conclude that this user-centric approach to data collection is a promising strategy to reduce the expenses associated with obtaining reliable training data and to continuously update datasets as the media landscape evolves.
Critical Analysis
The paper presents a novel and promising approach to addressing the challenge of obtaining reliable training data for media bias detection systems. The use of a human-in-the-loop feedback mechanism is a clever solution that leverages human expertise to improve the quality of the training data.
However, the paper does acknowledge some limitations of the approach. For example, the researchers note that the feedback mechanism may introduce systematic biases if certain types of users (e.g., those with strong political views) are overrepresented in the feedback data. Additionally, the paper does not explore the long-term sustainability of the feedback mechanism or how it might need to be adapted as the media landscape continues to evolve.
Another potential issue is the scalability of the approach. While the researchers claim that the feedback mechanism is scalable, it's unclear how well it would work with a much larger user base or a more diverse set of news sources. The paper also does not discuss the potential privacy and ethical implications of collecting user feedback on media bias.
Despite these limitations, the paper makes a valuable contribution to the field of media bias detection and highlights the importance of involving users in the data collection process. The researchers' approach demonstrates the potential for human-in-the-loop systems to improve the reliability and relevance of machine learning-based solutions in complex, context-dependent domains.
Conclusion
The provided paper addresses the critical problem of media bias and presents a novel solution using a human-in-the-loop feedback mechanism. By allowing readers to provide feedback on machine-generated bias highlights, the researchers were able to significantly improve the quality of the training data and the performance of their bias detection models.
The implementation of this approach in the NewsUnfold web application demonstrates the potential for user-centric data collection strategies to address the challenges of bias detection in digital media. While the paper acknowledges some limitations, it offers a promising direction for future research and development in this important area.
Overall, the paper highlights the value of human-in-the-loop systems and their ability to leverage human expertise to enhance the capabilities of machine learning-based solutions. As the media landscape continues to evolve, approaches like the one presented in this paper may become increasingly important for maintaining the integrity and reliability of news sources.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🛠️
0
NewsUnfold: Creating a News-Reading Application That Indicates Linguistic Media Bias and Collects Feedback
Smi Hinterreiter, Martin Wessel, Fabian Schliski, Isao Echizen, Marc Erich Latoschik, Timo Spinde
Media bias is a multifaceted problem, leading to one-sided views and impacting decision-making. A way to address digital media bias is to detect and indicate it automatically through machine-learning methods. However, such detection is limited due to the difficulty of obtaining reliable training data. Human-in-the-loop-based feedback mechanisms have proven an effective way to facilitate the data-gathering process. Therefore, we introduce and test feedback mechanisms for the media bias domain, which we then implement on NewsUnfold, a news-reading web application to collect reader feedback on machine-generated bias highlights within online news articles. Our approach augments dataset quality by significantly increasing inter-annotator agreement by 26.31% and improving classifier performance by 2.49%. As the first human-in-the-loop application for media bias, the feedback mechanism shows that a user-centric approach to media bias data collection can return reliable data while being scalable and evaluated as easy to use. NewsUnfold demonstrates that feedback mechanisms are a promising strategy to reduce data collection expenses and continuously update datasets to changes in context.
Read more7/30/2024
👨🏫
0
News Ninja: Gamified Annotation of Linguistic Bias in Online News
Smi Hinterreiter, Timo Spinde, Sebastian Oberdorfer, Isao Echizen, Marc Erich Latoschik
Recent research shows that visualizing linguistic bias mitigates its negative effects. However, reliable automatic detection methods to generate such visualizations require costly, knowledge-intensive training data. To facilitate data collection for media bias datasets, we present News Ninja, a game employing data-collecting game mechanics to generate a crowdsourced dataset. Before annotating sentences, players are educated on media bias via a tutorial. Our findings show that datasets gathered with crowdsourced workers trained on News Ninja can reach significantly higher inter-annotator agreements than expert and crowdsourced datasets with similar data quality. As News Ninja encourages continuous play, it allows datasets to adapt to the reception and contextualization of news over time, presenting a promising strategy to reduce data collection expenses, educate players, and promote long-term bias mitigation.
Read more7/25/2024
0
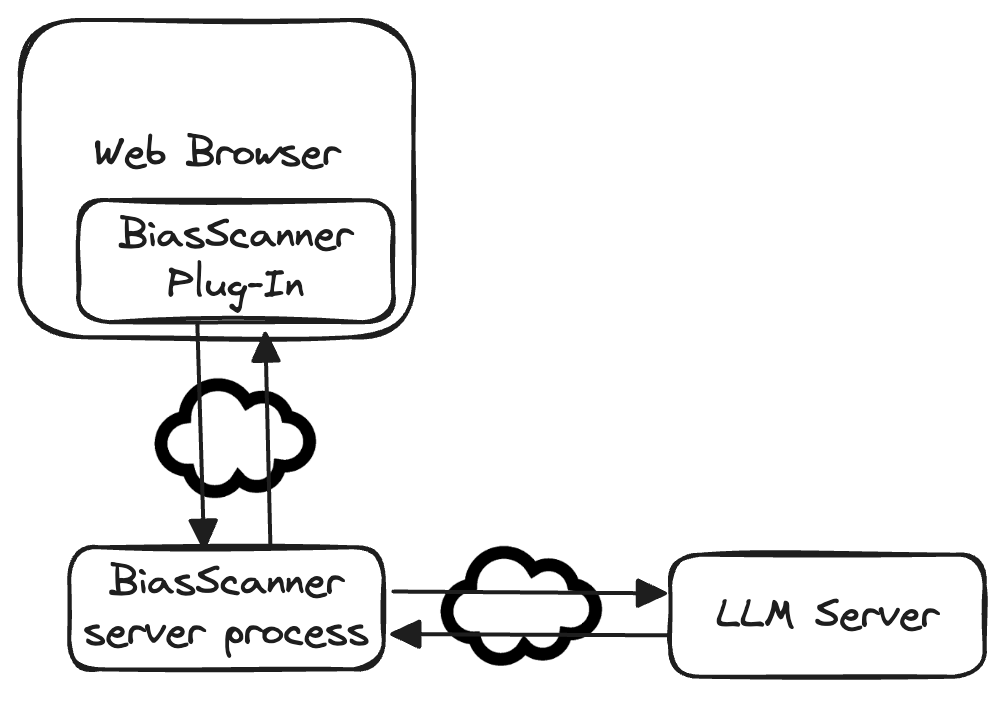
BiasScanner: Automatic Detection and Classification of News Bias to Strengthen Democracy
Tim Menzner, Jochen L. Leidner
The increasing consumption of news online in the 21st century coincided with increased publication of disinformation, biased reporting, hate speech and other unwanted Web content. We describe BiasScanner, an application that aims to strengthen democracy by supporting news consumers with scrutinizing news articles they are reading online. BiasScanner contains a server-side pre-trained large language model to identify biased sentences of news articles and a front-end Web browser plug-in. At the time of writing, BiasScanner can identify and classify more than two dozen types of media bias at the sentence level, making it the most fine-grained model and only deployed application (automatic system in use) of its kind. It was implemented in a light-weight and privacy-respecting manner, and in addition to highlighting likely biased sentence it also provides explanations for each classification decision as well as a summary analysis for each news article. While prior research has addressed news bias detection, we are not aware of any work that resulted in a deployed browser plug-in (c.f. also biasscanner.org for a Web demo).
Read more7/16/2024
0
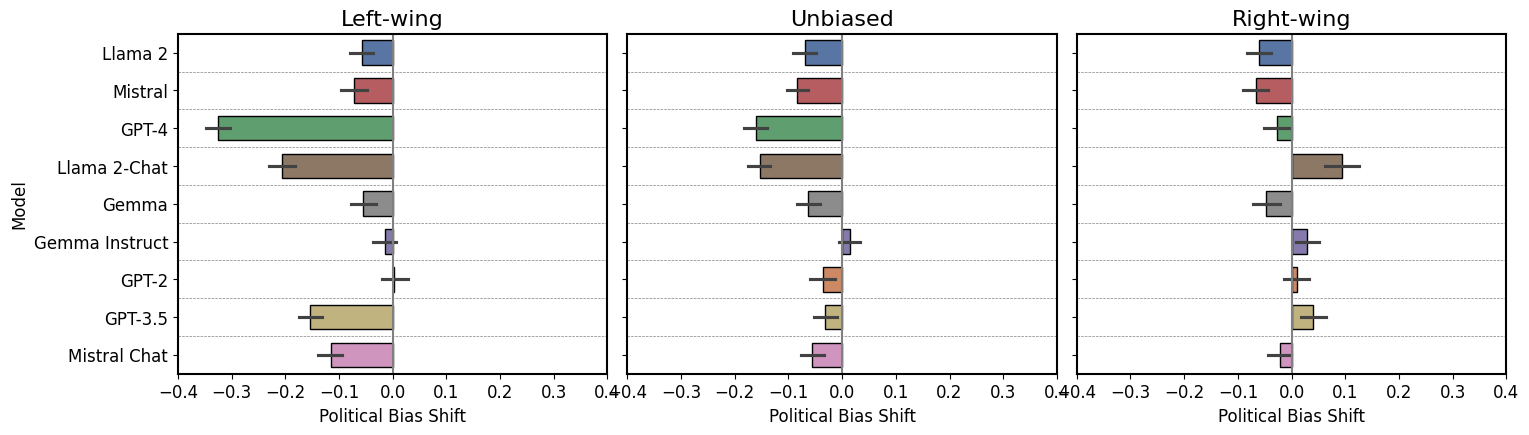
Quantifying Generative Media Bias with a Corpus of Real-world and Generated News Articles
Filip Trhlik, Pontus Stenetorp
Large language models (LLMs) are increasingly being utilised across a range of tasks and domains, with a burgeoning interest in their application within the field of journalism. This trend raises concerns due to our limited understanding of LLM behaviour in this domain, especially with respect to political bias. Existing studies predominantly focus on LLMs undertaking political questionnaires, which offers only limited insights into their biases and operational nuances. To address this gap, our study establishes a new curated dataset that contains 2,100 human-written articles and utilises their descriptions to generate 56,700 synthetic articles using nine LLMs. This enables us to analyse shifts in properties between human-authored and machine-generated articles, with this study focusing on political bias, detecting it using both supervised models and LLMs. Our findings reveal significant disparities between base and instruction-tuned LLMs, with instruction-tuned models exhibiting consistent political bias. Furthermore, we are able to study how LLMs behave as classifiers, observing their display of political bias even in this role. Overall, for the first time within the journalistic domain, this study outlines a framework and provides a structured dataset for quantifiable experiments, serving as a foundation for further research into LLM political bias and its implications.
Read more6/18/2024