NICE: To Optimize In-Context Examples or Not?

0

Sign in to get full access
Overview
- This paper explores the question of whether it is beneficial to optimize the in-context examples used in large language models (LLMs) during training.
- The researchers investigate different methods for selecting in-context examples and evaluate their impact on model performance across a range of tasks.
- The paper provides insights into the role of in-context examples in LLM training and the potential trade-offs between optimization and generalization.
Plain English Explanation
Large language models (LLMs) are powerful AI systems that can generate human-like text, answer questions, and even complete complex tasks. These models are trained on vast amounts of text data, which helps them learn the patterns and structure of language.
One important aspect of LLM training is the use of "in-context examples" - snippets of text that are provided to the model along with the input it is trying to process. These examples can help the model better understand the context and task at hand, potentially improving its performance.
The researchers in this paper wanted to explore whether it's worth optimizing the selection of these in-context examples to further boost the model's capabilities. They tested different methods for choosing the most relevant and helpful examples, and evaluated how this affected the model's performance on a variety of tasks.
The paper's findings provide insights into the trade-offs between optimizing in-context examples and maintaining the model's ability to generalize to new situations. While optimizing the examples can lead to improved performance on certain tasks, it may also limit the model's flexibility and adaptability to unfamiliar contexts.
Overall, this research contributes to our understanding of how the design choices in LLM training can impact a model's capabilities and real-world applicability. By exploring the nuances of in-context example selection, the authors help shed light on the complex interplay between optimization and generalization in large language models.
Technical Explanation
The paper, titled "NICE: To Optimize In-Context Examples or Not?", investigates the impact of optimizing the selection of in-context examples during the training of large language models (LLMs). The researchers propose a framework called NICE (Natural In-Context Examples) that explores different methods for selecting the most relevant and helpful examples to provide to the model during training.
The team tested several NICE algorithms, including ones that prioritize examples based on their similarity to the input, their informativeness, or their diversity. They then evaluated the performance of LLMs trained using these optimized in-context examples on a range of downstream tasks, such as natural language inference, question answering, and text generation.
The results suggest that optimizing in-context examples can indeed lead to improved performance on certain tasks, but it may also limit the model's ability to generalize to new situations. The researchers found that while the NICE-optimized models excelled on the specific tasks they were trained for, they sometimes struggled when faced with novel contexts or inputs that deviated from the training data.
This trade-off between optimization and generalization is a key insight from the paper. The authors argue that the optimal approach to in-context example selection may depend on the intended use case and the specific goals of the LLM deployment. In some cases, a more generalized, less-optimized approach may be preferable, while in others, the benefits of targeted optimization may outweigh the potential loss of flexibility.
The paper also discusses the computational and scalability considerations of the NICE algorithms, as well as potential extensions and future research directions in this area.
Critical Analysis
The NICE framework proposed in this paper represents a valuable contribution to the ongoing research on improving the training and performance of large language models. By exploring the role of in-context examples, the authors shed light on an important aspect of LLM design that has often been overlooked.
One strength of the paper is its rigorous experimental design, which allows the researchers to systematically evaluate the impact of different in-context example selection methods across a diverse set of tasks. This approach helps to illuminate the nuanced trade-offs between optimization and generalization, and provides useful guidance for practitioners who are looking to deploy LLMs in real-world applications.
However, the paper also acknowledges several limitations and areas for further research. For example, the authors note that the NICE algorithms may not be scalable to the enormous datasets used to train state-of-the-art LLMs, and that the performance gains observed in their experiments may be task-dependent.
Additionally, while the paper discusses the potential implications of its findings, it does not delve deeply into the broader societal and ethical considerations surrounding the use of LLMs. As these models become more powerful and ubiquitous, it will be important for the research community to grapple with questions of bias, fairness, and responsible deployment.
Overall, this paper represents a valuable contribution to the field of large language model research. By exploring the nuanced role of in-context examples, the authors have provided valuable insights that can help guide the development of more effective and reliable LLM systems. However, further research is needed to fully understand the implications of these findings and to ensure that LLMs are deployed in a responsible and ethical manner.
Conclusion
The paper "NICE: To Optimize In-Context Examples or Not?" investigates the impact of optimizing the selection of in-context examples during the training of large language models (LLMs). The researchers propose a framework called NICE that explores different methods for choosing the most relevant and helpful examples to provide to the model.
The findings suggest that while optimizing in-context examples can lead to improved performance on specific tasks, it may also limit the model's ability to generalize to new situations. This trade-off between optimization and generalization is a key insight from the paper, which highlights the importance of considering the intended use case and deployment goals when designing LLM training approaches.
This research contributes to our understanding of how the design choices in LLM training can impact a model's capabilities and real-world applicability. By exploring the nuances of in-context example selection, the authors help shed light on the complex interplay between optimization and generalization in large language models, paving the way for the development of more effective and reliable AI systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
NICE: To Optimize In-Context Examples or Not?
Pragya Srivastava, Satvik Golechha, Amit Deshpande, Amit Sharma
Recent work shows that in-context learning and optimization of in-context examples (ICE) can significantly improve the accuracy of large language models (LLMs) on a wide range of tasks, leading to an apparent consensus that ICE optimization is crucial for better performance. However, most of these studies assume a fixed or no instruction provided in the prompt. We challenge this consensus by investigating the necessity of optimizing ICE when task-specific instructions are provided and find that there are many tasks for which it yields diminishing returns. In particular, using a diverse set of tasks and a systematically created instruction set with gradually added details, we find that as the prompt instruction becomes more detailed, the returns on ICE optimization diminish. To characterize this behavior, we introduce a task-specific metric called Normalized Invariability to Choice of Examples (NICE) that quantifies the learnability of tasks from a given instruction, and provides a heuristic to help decide whether to optimize instructions or ICE for a new task. Given a task, the proposed metric can reliably predict the utility of optimizing ICE compared to using random ICE. Our code is available at https://github.com/microsoft/nice-icl.
Read more6/7/2024
0
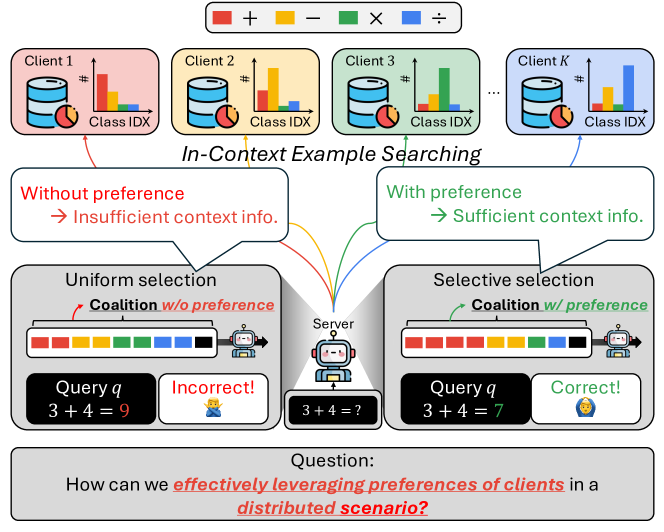
Distributed In-Context Learning under Non-IID Among Clients
Siqi Liang, Sumyeong Ahn, Jiayu Zhou
Advancements in large language models (LLMs) have shown their effectiveness in multiple complicated natural language reasoning tasks. A key challenge remains in adapting these models efficiently to new or unfamiliar tasks. In-context learning (ICL) provides a promising solution for few-shot adaptation by retrieving a set of data points relevant to a query, called in-context examples (ICE), from a training dataset and providing them during the inference as context. Most existing studies utilize a centralized training dataset, yet many real-world datasets may be distributed among multiple clients, and remote data retrieval can be associated with costs. Especially when the client data are non-identical independent distributions (non-IID), retrieving from clients a proper set of ICEs needed for a test query presents critical challenges. In this paper, we first show that in this challenging setting, test queries will have different preferences among clients because of non-IIDness, and equal contribution often leads to suboptimal performance. We then introduce a novel approach to tackle the distributed non-IID ICL problem when a data usage budget is present. The principle is that each client's proper contribution (budget) should be designed according to the preference of each query for that client. Our approach uses a data-driven manner to allocate a budget for each client, tailored to each test query. Through extensive empirical studies on diverse datasets, our framework demonstrates superior performance relative to competing baselines.
Read more8/2/2024
🛠️
0
Prompt Optimization with EASE? Efficient Ordering-aware Automated Selection of Exemplars
Zhaoxuan Wu, Xiaoqiang Lin, Zhongxiang Dai, Wenyang Hu, Yao Shu, See-Kiong Ng, Patrick Jaillet, Bryan Kian Hsiang Low
Large language models (LLMs) have shown impressive capabilities in real-world applications. The capability of in-context learning (ICL) allows us to adapt an LLM to downstream tasks by including input-label exemplars in the prompt without model fine-tuning. However, the quality of these exemplars in the prompt greatly impacts performance, highlighting the need for an effective automated exemplar selection method. Recent studies have explored retrieval-based approaches to select exemplars tailored to individual test queries, which can be undesirable due to extra test-time computation and an increased risk of data exposure. Moreover, existing methods fail to adequately account for the impact of exemplar ordering on the performance. On the other hand, the impact of the instruction, another essential component in the prompt given to the LLM, is often overlooked in existing exemplar selection methods. To address these challenges, we propose a novel method named EASE, which leverages the hidden embedding from a pre-trained language model to represent ordered sets of exemplars and uses a neural bandit algorithm to optimize the sets of exemplars while accounting for exemplar ordering. Our EASE can efficiently find an ordered set of exemplars that performs well for all test queries from a given task, thereby eliminating test-time computation. Importantly, EASE can be readily extended to jointly optimize both the exemplars and the instruction. Through extensive empirical evaluations (including novel tasks), we demonstrate the superiority of EASE over existing methods, and reveal practical insights about the impact of exemplar selection on ICL, which may be of independent interest. Our code is available at https://github.com/ZhaoxuanWu/EASE-Prompt-Optimization.
Read more5/28/2024
0
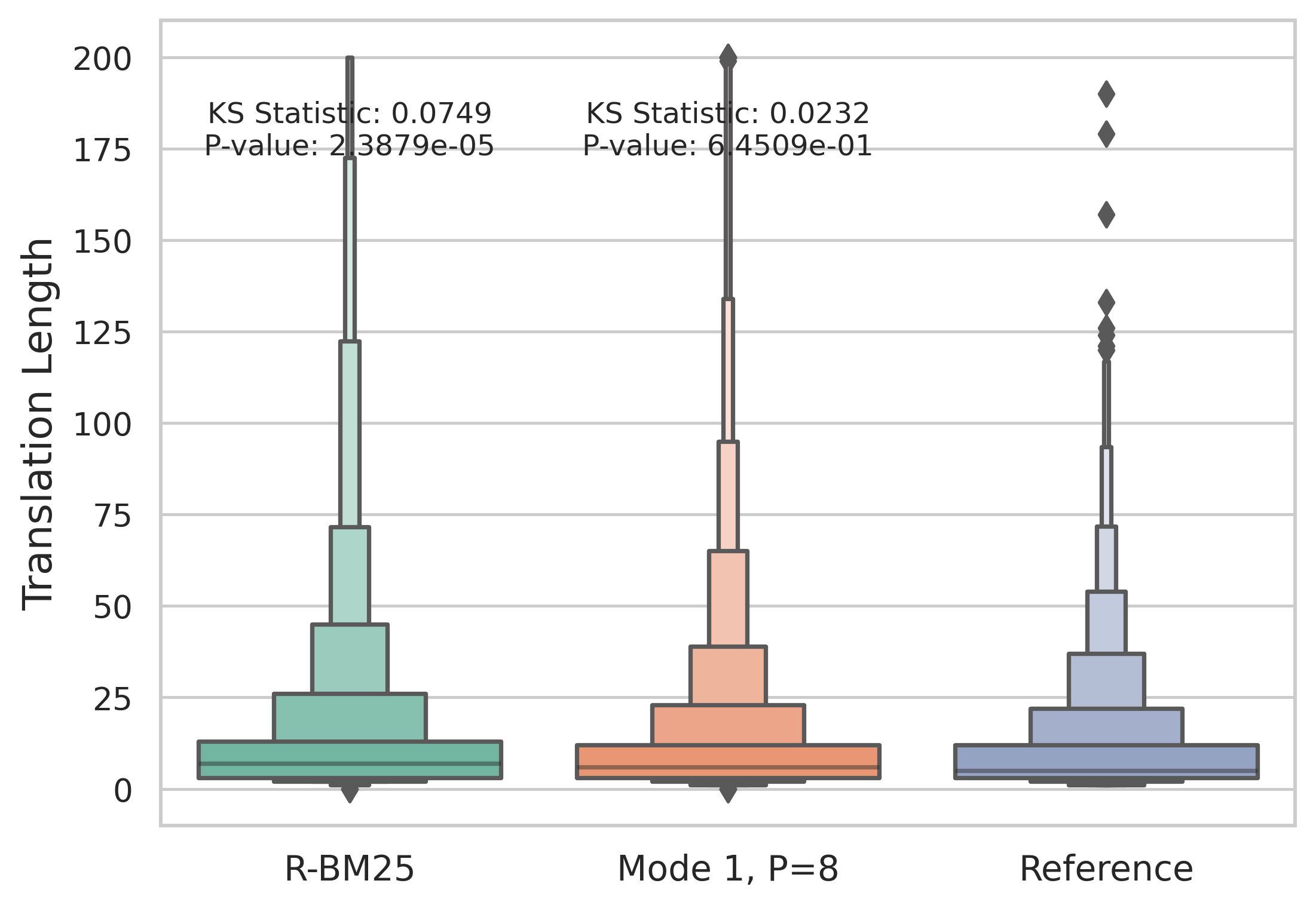
Guiding In-Context Learning of LLMs through Quality Estimation for Machine Translation
Javad Pourmostafa Roshan Sharami, Dimitar Shterionov, Pieter Spronck
The quality of output from large language models (LLMs), particularly in machine translation (MT), is closely tied to the quality of in-context examples (ICEs) provided along with the query, i.e., the text to translate. The effectiveness of these ICEs is influenced by various factors, such as the domain of the source text, the order in which the ICEs are presented, the number of these examples, and the prompt templates used. Naturally, selecting the most impactful ICEs depends on understanding how these affect the resulting translation quality, which ultimately relies on translation references or human judgment. This paper presents a novel methodology for in-context learning (ICL) that relies on a search algorithm guided by domain-specific quality estimation (QE). Leveraging the XGLM model, our methodology estimates the resulting translation quality without the need for translation references, selecting effective ICEs for MT to maximize translation quality. Our results demonstrate significant improvements over existing ICL methods and higher translation performance compared to fine-tuning a pre-trained language model (PLM), specifically mBART-50.
Read more9/19/2024