Distributed In-Context Learning under Non-IID Among Clients

0
Sign in to get full access
Overview
- Distributed in-context learning under non-IID (independent and identically distributed) conditions among clients
- Explores how to effectively train large language models in a distributed setting with heterogeneous client data
- Proposes a new approach to address the challenges of non-IID data distribution across clients
Plain English Explanation
In this paper, the researchers investigate the problem of distributed in-context learning under non-IID conditions among clients. This means they're looking at how to effectively train large language models in a setting where different clients (e.g., devices or users) have access to different types of data that don't necessarily follow the same statistical distribution.
The key challenge is that traditional machine learning approaches often assume the training data is IID - meaning the data points are independent and follow the same underlying distribution. However, in real-world distributed scenarios, this often isn't the case.
The researchers propose a new approach to address this challenge, which aims to enable efficient context learning even when the data across clients is non-IID. Their solution involves techniques like implicit context learning to capture relevant context information and instruction following to guide the model's learning process.
Technical Explanation
The paper formulates the problem of distributed in-context learning under non-IID conditions among clients. The researchers consider a scenario where multiple clients (e.g., devices or users) collaboratively train a large language model, but the data available to each client follows a different statistical distribution (i.e., is non-IID).
To address this challenge, the paper proposes a novel distributed in-context learning framework that consists of several key components:
- Client-side Context Encoder: Each client maintains a context encoder that learns to extract relevant contextual information from its local data.
- Server-side Model: A central server hosts the main language model, which is trained using the aggregated contextual information from all clients.
- Iterative Client-Server Communication: Clients and the server engage in an iterative communication process to update the model and context encoders.
The researchers evaluate their approach on several benchmark tasks and demonstrate its effectiveness in achieving high performance under non-IID conditions.
Critical Analysis
The paper presents a well-designed solution to the important problem of distributed in-context learning under non-IID conditions. By incorporating client-side context encoders and an iterative client-server communication process, the proposed framework effectively captures relevant contextual information and adapts the language model to the heterogeneous data distributions across clients.
One potential limitation is the computational and communication overhead associated with the iterative client-server updates. The authors acknowledge this tradeoff and suggest exploring ways to reduce the communication burden in future work.
Additionally, the paper could have discussed the scalability of the approach to larger numbers of clients and more diverse datasets. Exploring the robustness of the system to noisy or adversarial client data could also be a valuable area for further research.
Conclusion
This paper presents a novel approach to distributed in-context learning under non-IID conditions among clients. By incorporating client-side context encoders and an iterative client-server communication process, the proposed framework effectively captures relevant contextual information and adapts the language model to the heterogeneous data distributions across clients.
The results demonstrate the effectiveness of this approach in achieving high performance under non-IID conditions, which has important implications for the development of large-scale, distributed language models that can operate in real-world, decentralized environments.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Distributed In-Context Learning under Non-IID Among Clients
Siqi Liang, Sumyeong Ahn, Jiayu Zhou
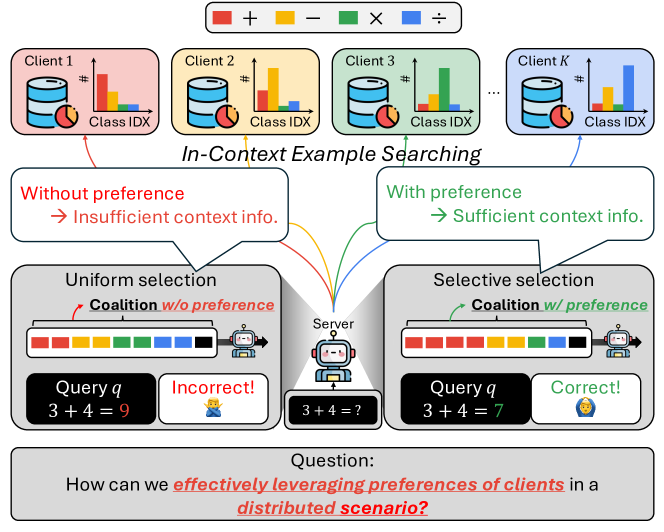
Advancements in large language models (LLMs) have shown their effectiveness in multiple complicated natural language reasoning tasks. A key challenge remains in adapting these models efficiently to new or unfamiliar tasks. In-context learning (ICL) provides a promising solution for few-shot adaptation by retrieving a set of data points relevant to a query, called in-context examples (ICE), from a training dataset and providing them during the inference as context. Most existing studies utilize a centralized training dataset, yet many real-world datasets may be distributed among multiple clients, and remote data retrieval can be associated with costs. Especially when the client data are non-identical independent distributions (non-IID), retrieving from clients a proper set of ICEs needed for a test query presents critical challenges. In this paper, we first show that in this challenging setting, test queries will have different preferences among clients because of non-IIDness, and equal contribution often leads to suboptimal performance. We then introduce a novel approach to tackle the distributed non-IID ICL problem when a data usage budget is present. The principle is that each client's proper contribution (budget) should be designed according to the preference of each query for that client. Our approach uses a data-driven manner to allocate a budget for each client, tailored to each test query. Through extensive empirical studies on diverse datasets, our framework demonstrates superior performance relative to competing baselines.
Read more8/2/2024
🌿
0
A Survey on In-context Learning
Qingxiu Dong, Lei Li, Damai Dai, Ce Zheng, Jingyuan Ma, Rui Li, Heming Xia, Jingjing Xu, Zhiyong Wu, Baobao Chang, Xu Sun, Lei Li, Zhifang Sui
With the increasing capabilities of large language models (LLMs), in-context learning (ICL) has emerged as a new paradigm for natural language processing (NLP), where LLMs make predictions based on contexts augmented with a few examples. It has been a significant trend to explore ICL to evaluate and extrapolate the ability of LLMs. In this paper, we aim to survey and summarize the progress and challenges of ICL. We first present a formal definition of ICL and clarify its correlation to related studies. Then, we organize and discuss advanced techniques, including training strategies, prompt designing strategies, and related analysis. Additionally, we explore various ICL application scenarios, such as data engineering and knowledge updating. Finally, we address the challenges of ICL and suggest potential directions for further research. We hope that our work can encourage more research on uncovering how ICL works and improving ICL.
Read more6/19/2024
0
In-Context Learning or: How I learned to stop worrying and love Applied Information Retrieval
Andrew Parry, Debasis Ganguly, Manish Chandra
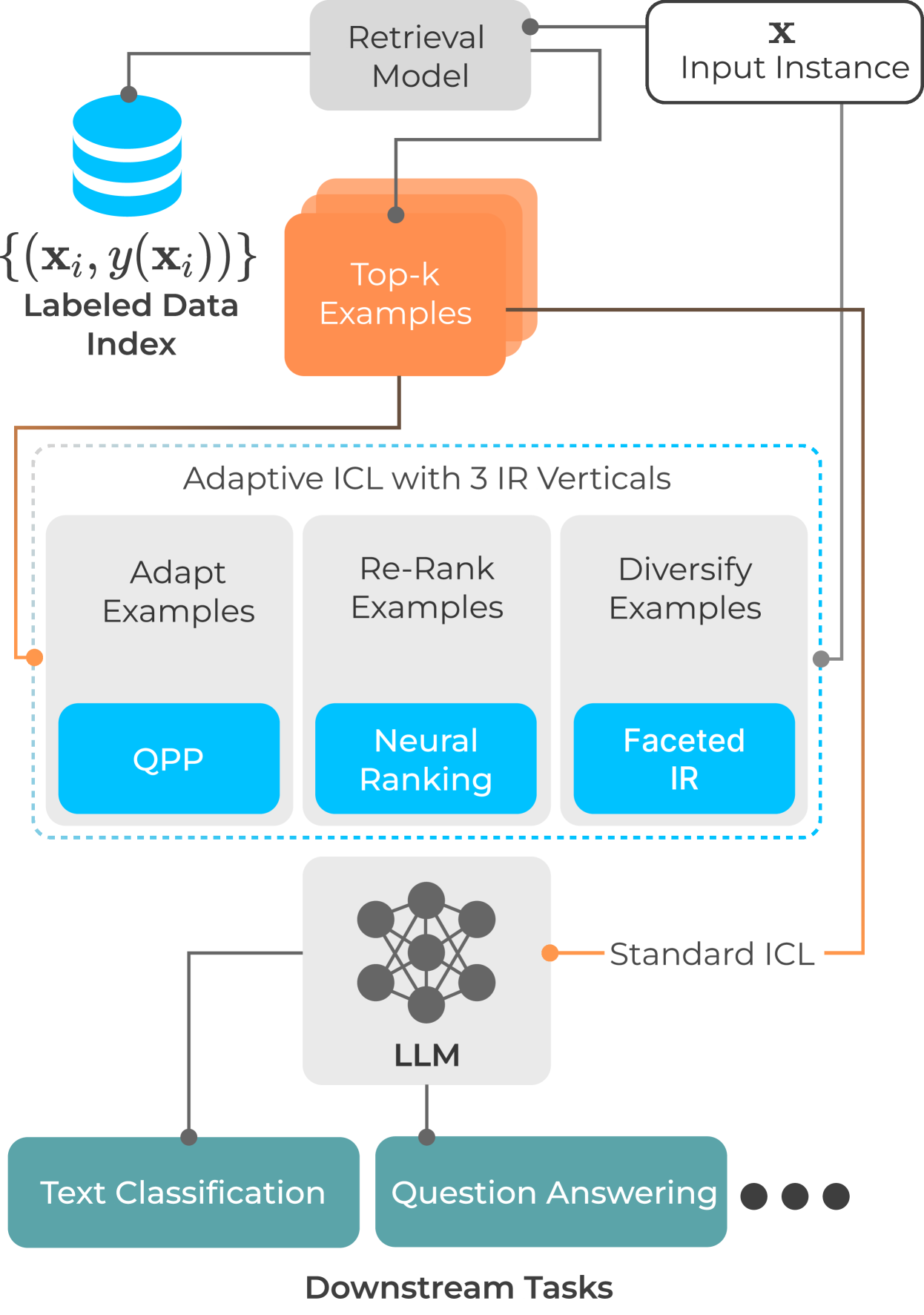
With the increasing ability of large language models (LLMs), in-context learning (ICL) has evolved as a new paradigm for natural language processing (NLP), where instead of fine-tuning the parameters of an LLM specific to a downstream task with labeled examples, a small number of such examples is appended to a prompt instruction for controlling the decoder's generation process. ICL, thus, is conceptually similar to a non-parametric approach, such as $k$-NN, where the prediction for each instance essentially depends on the local topology, i.e., on a localised set of similar instances and their labels (called few-shot examples). This suggests that a test instance in ICL is analogous to a query in IR, and similar examples in ICL retrieved from a training set relate to a set of documents retrieved from a collection in IR. While standard unsupervised ranking models can be used to retrieve these few-shot examples from a training set, the effectiveness of the examples can potentially be improved by re-defining the notion of relevance specific to its utility for the downstream task, i.e., considering an example to be relevant if including it in the prompt instruction leads to a correct prediction. With this task-specific notion of relevance, it is possible to train a supervised ranking model (e.g., a bi-encoder or cross-encoder), which potentially learns to optimally select the few-shot examples. We believe that the recent advances in neural rankers can potentially find a use case for this task of optimally choosing examples for more effective downstream ICL predictions.
Read more5/3/2024
0
Locally Differentially Private In-Context Learning
Chunyan Zheng, Keke Sun, Wenhao Zhao, Haibo Zhou, Lixin Jiang, Shaoyang Song, Chunlai Zhou
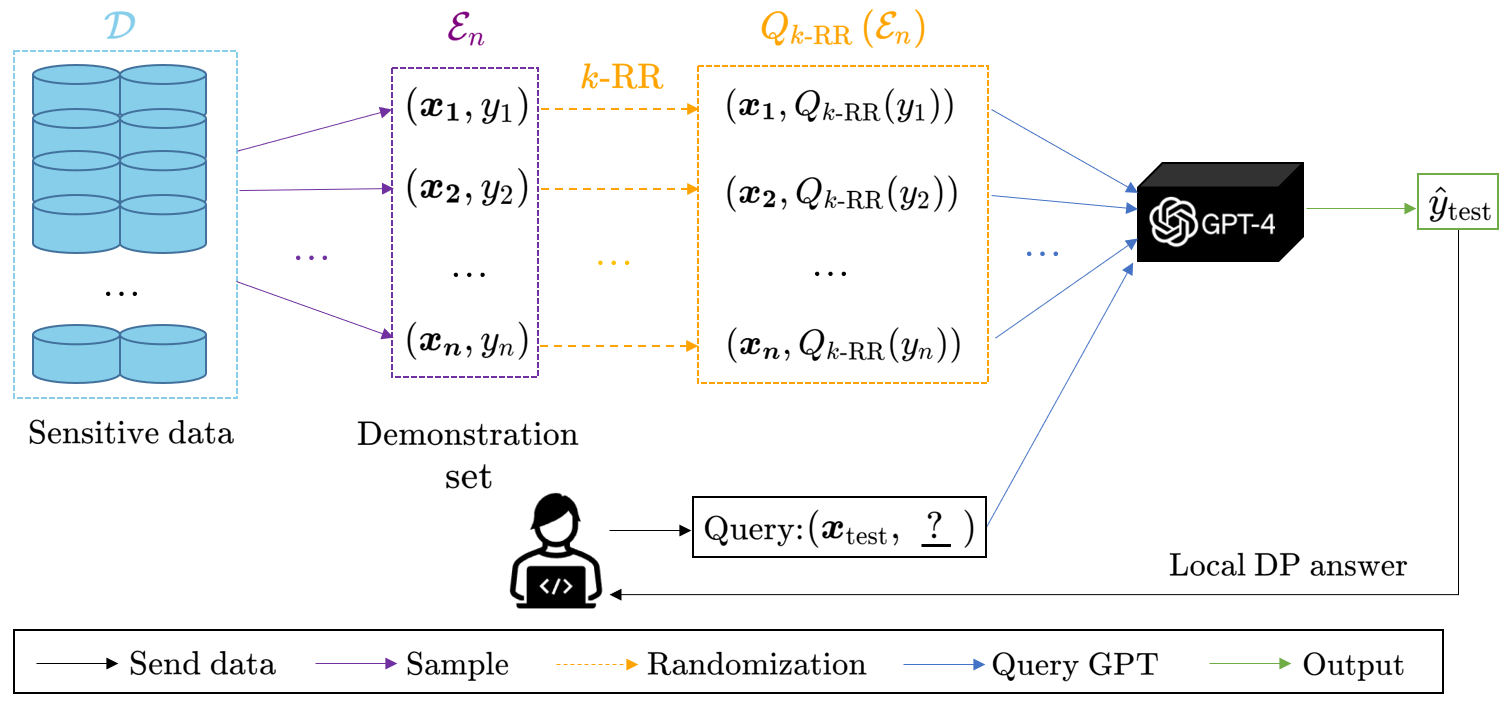
Large pretrained language models (LLMs) have shown surprising In-Context Learning (ICL) ability. An important application in deploying large language models is to augment LLMs with a private database for some specific task. The main problem with this promising commercial use is that LLMs have been shown to memorize their training data and their prompt data are vulnerable to membership inference attacks (MIA) and prompt leaking attacks. In order to deal with this problem, we treat LLMs as untrusted in privacy and propose a locally differentially private framework of in-context learning(LDP-ICL) in the settings where labels are sensitive. Considering the mechanisms of in-context learning in Transformers by gradient descent, we provide an analysis of the trade-off between privacy and utility in such LDP-ICL for classification. Moreover, we apply LDP-ICL to the discrete distribution estimation problem. In the end, we perform several experiments to demonstrate our analysis results.
Read more5/9/2024