No Dataset Needed for Downstream Knowledge Benchmarking: Response Dispersion Inversely Correlates with Accuracy on Domain-specific QA

1

Sign in to get full access
Overview
- Presents a novel approach to benchmarking large language models' knowledge without relying on downstream datasets
- Finds that response dispersion, a measure of model output variability, inversely correlates with accuracy on domain-specific question answering tasks
- Suggests that monitoring response dispersion can provide a simple yet effective way to evaluate model knowledge without the need for labeled datasets
Plain English Explanation
The research paper introduces a new method for evaluating the knowledge of large language models, such as GPT-3 or PaLM, without the need for specialized datasets. The authors propose that the variability, or "dispersion," of a model's responses to a given prompt can indicate how well the model understands the domain-specific information being tested.
The key idea is that models with a better grasp of the subject matter will tend to produce more consistent, focused responses, while less knowledgeable models will exhibit more diverse and scattered outputs. By measuring this response dispersion, the researchers found they could predict the model's performance on domain-specific question-answering tasks without requiring a labeled dataset for that particular domain.
This is a significant finding, as building specialized datasets for evaluating model knowledge can be time-consuming and resource-intensive. The authors argue that their approach provides a simpler and more efficient way to assess a model's capabilities, which could be particularly useful for quickly benchmarking emerging language models or evaluating their suitability for specific applications.
Technical Explanation
The paper presents an experimental study that investigates the relationship between a language model's response dispersion and its performance on domain-specific question-answering (QA) tasks. The authors hypothesized that models with a better grasp of the domain-specific knowledge would exhibit lower response dispersion, as their outputs would be more consistent and focused.
To test this, the researchers selected several pre-trained language models, including GPT-3, PaLM, and others, and evaluated them on a range of domain-specific QA tasks, such as biology, physics, and law. For each task, they measured the models' response dispersion by calculating the entropy of the output tokens, which captures the diversity and unpredictability of the responses.
The results showed a clear inverse correlation between response dispersion and QA accuracy: models with lower response dispersion tended to perform better on the domain-specific QA tasks, while those with higher dispersion exhibited lower accuracy. The authors argue that this relationship holds true across different domains and model architectures, suggesting it is a robust and generalizable phenomenon.
The authors propose that monitoring response dispersion could provide a simple yet effective way to evaluate a model's knowledge without the need for labeled datasets. This could be particularly useful for quickly benchmarking emerging language models or assessing their suitability for specific applications, where building specialized datasets can be time-consuming and resource-intensive.
Critical Analysis
The research presented in this paper offers a promising approach to evaluating language models' knowledge without relying on downstream datasets. The authors' key insight – that response dispersion can serve as a proxy for domain-specific understanding – is both elegant and compelling.
One potential limitation of the study is that it focuses primarily on the relationship between response dispersion and QA performance, without exploring other facets of model knowledge or capabilities. It would be valuable to see how the dispersion metric correlates with other types of tasks or benchmarks, such as commonsense reasoning, analogy-making, or zero-shot learning.
Additionally, the paper does not delve into the potential reasons or mechanisms underlying the inverse correlation between dispersion and accuracy. A deeper investigation into the cognitive and linguistic factors that drive this relationship could yield further insights and potentially inform the development of more sophisticated evaluation techniques.
Despite these minor caveats, the authors' findings represent a significant contribution to the field of language model evaluation. By providing a simple, dataset-agnostic approach to assessing domain-specific knowledge, this research could have important implications for the way we benchmark and compare the capabilities of large language models, especially as the field continues to rapidly evolve.
Conclusion
The paper "No Dataset Needed for Downstream Knowledge Benchmarking: Response Dispersion Inversely Correlates with Accuracy on Domain-specific QA" presents a novel approach to evaluating language models' knowledge that does not rely on specialized datasets. The key insight is that the variability, or dispersion, of a model's responses to a given prompt can serve as an effective proxy for its domain-specific understanding, with lower dispersion indicating better performance on related tasks.
This finding could have far-reaching implications for the way we benchmark and compare large language models, as it provides a simple and efficient alternative to the resource-intensive process of building specialized datasets. By monitoring response dispersion, researchers and practitioners may be able to quickly assess a model's suitability for a particular application or domain, paving the way for more agile and cost-effective model development and deployment.
Overall, this research represents an important step forward in the quest to better understand and evaluate the capabilities of large language models, with the potential to significantly impact the field of natural language processing and its real-world applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
1
No Dataset Needed for Downstream Knowledge Benchmarking: Response Dispersion Inversely Correlates with Accuracy on Domain-specific QA
Robert L Simione II
This research seeks to obviate the need for creating QA datasets and grading (chatbot) LLM responses when comparing LLMs' knowledge in specific topic domains. This is done in an entirely end-user centric way without need for access to any inner workings of the LLM, so long as it can be prompted and given a random seed to create different generations to the same prompt. The paper does this by, for a given topic domain, defining the response dispersion of an LLM by repeatedly asking an LLM the same opinion question about that topic domain. Namely, the response dispersion is the count of singular values needed to explain 95% of the variance in the embedding matrix of the LLM's responses. It is found that the response dispersion is inversely correlated with accuracy on relevant QA evaluations (average spearman rank correlation stronger than -.59). A use-case analysis shows that when comparing two different LLMs on the same topic domain, comparing their response dispersion is a suitable replacement for comparing their QA accuracy between 74% and 89% of the time, the range depending on certain reasonable accuracy-difference tolerances that may be acceptable to an end-user in exchange for the labor being saved using response dispersion instead of QA accuracy for comparison. Two response embeddings are studied for creating the embedding matrix in this study, one is from OpenAI's APIs and one is a novel embedding, here named reference sentence similarity embeddings, that can be computed locally and performs very nearly as well in calculating response dispersion. Also in this research, a pre-existing dataset called the IRC-Wiki Trivia dataset, originally developed for trivia games, has been re-purposed, curated, and the curation, called IRC-WikiTriviaQA, is made available for the purpose of this research.
Read more8/27/2024
0
RepLiQA: A Question-Answering Dataset for Benchmarking LLMs on Unseen Reference Content
Joao Monteiro, Pierre-Andre Noel, Etienne Marcotte, Sai Rajeswar, Valentina Zantedeschi, David Vazquez, Nicolas Chapados, Christopher Pal, Perouz Taslakian
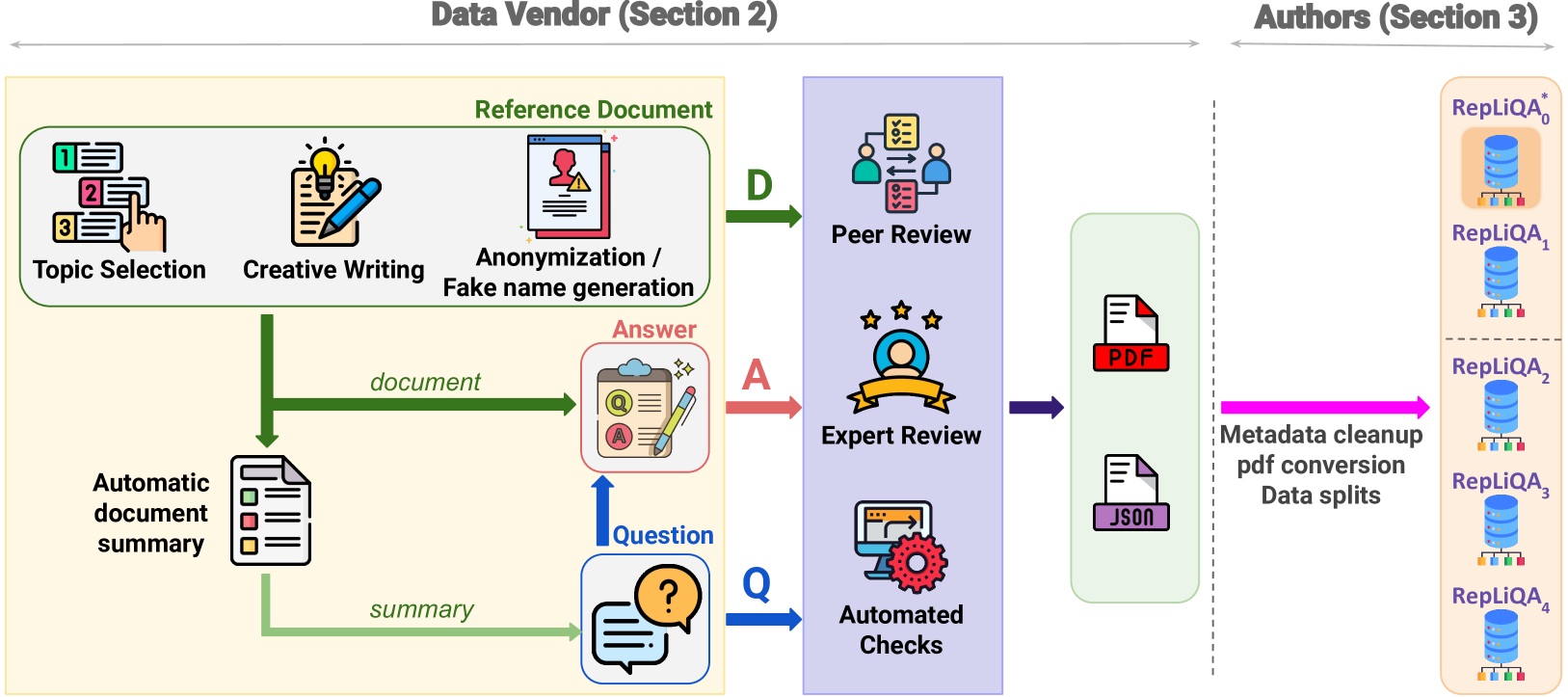
Large Language Models (LLMs) are trained on vast amounts of data, most of which is automatically scraped from the internet. This data includes encyclopedic documents that harbor a vast amount of general knowledge (e.g., Wikipedia) but also potentially overlap with benchmark datasets used for evaluating LLMs. Consequently, evaluating models on test splits that might have leaked into the training set is prone to misleading conclusions. To foster sound evaluation of language models, we introduce a new test dataset named RepLiQA, suited for question-answering and topic retrieval tasks. RepLiQA is a collection of five splits of test sets, four of which have not been released to the internet or exposed to LLM APIs prior to this publication. Each sample in RepLiQA comprises (1) a reference document crafted by a human annotator and depicting an imaginary scenario (e.g., a news article) absent from the internet; (2) a question about the document's topic; (3) a ground-truth answer derived directly from the information in the document; and (4) the paragraph extracted from the reference document containing the answer. As such, accurate answers can only be generated if a model can find relevant content within the provided document. We run a large-scale benchmark comprising several state-of-the-art LLMs to uncover differences in performance across models of various types and sizes in a context-conditional language modeling setting. Released splits of RepLiQA can be found here: https://huggingface.co/datasets/ServiceNow/repliqa.
Read more6/18/2024

0
A Compass for Navigating the World of Sentence Embeddings for the Telecom Domain
Sujoy Roychowdhury, Sumit Soman, H. G. Ranjani, Vansh Chhabra, Neeraj Gunda, Subhadip Bandyopadhyay, Sai Krishna Bala
A plethora of sentence embedding models makes it challenging to choose one, especially for domains such as telecom, rich with specialized vocabulary. We evaluate multiple embeddings obtained from publicly available models and their domain-adapted variants, on both point retrieval accuracies as well as their (95%) confidence intervals. We establish a systematic method to obtain thresholds for similarity scores for different embeddings. We observe that fine-tuning improves mean bootstrapped accuracies as well as tightens confidence intervals. The pre-training combined with fine-tuning makes confidence intervals even tighter. To understand these variations, we analyse and report significant correlations between the distributional overlap between top-$K$, correct and random sentence similarities with retrieval accuracies and similarity thresholds. Following current literature, we analyze if retrieval accuracy variations can be attributed to isotropy of embeddings. Our conclusions are that isotropy of embeddings (as measured by two independent state-of-the-art isotropy metric definitions) cannot be attributed to better retrieval performance. However, domain adaptation which improves retrieval accuracies also improves isotropy. We establish that domain adaptation moves domain specific embeddings further away from general domain embeddings.
Read more7/23/2024

0
PEDANTS (Precise Evaluations of Diverse Answer Nominee Text for Skinflints): Efficient Evaluation Analysis and Benchmarking for Open-Domain Question Answering
Zongxia Li, Ishani Mondal, Yijun Liang, Huy Nghiem, Jordan Lee Boyd-Graber
Question answering (QA) can only make progress if we know if an answer is correct, but for many of the most challenging and interesting QA examples, current efficient answer correctness (AC) metrics do not align with human judgments, particularly verbose, free-form answers from large language models (LLMs). There are two challenges: a lack of diverse evaluation data and that models are too big and non-transparent; LLM-based scorers correlate better with humans, but this expensive task has only been tested on limited QA datasets. We rectify these issues by providing guidelines and datasets for evaluating machine QA adopted from human QA community. We also propose an efficient, low-resource, and interpretable QA evaluation method more stable than an exact match and neural methods.
Read more7/9/2024