RepLiQA: A Question-Answering Dataset for Benchmarking LLMs on Unseen Reference Content
2406.11811
0
0
Abstract
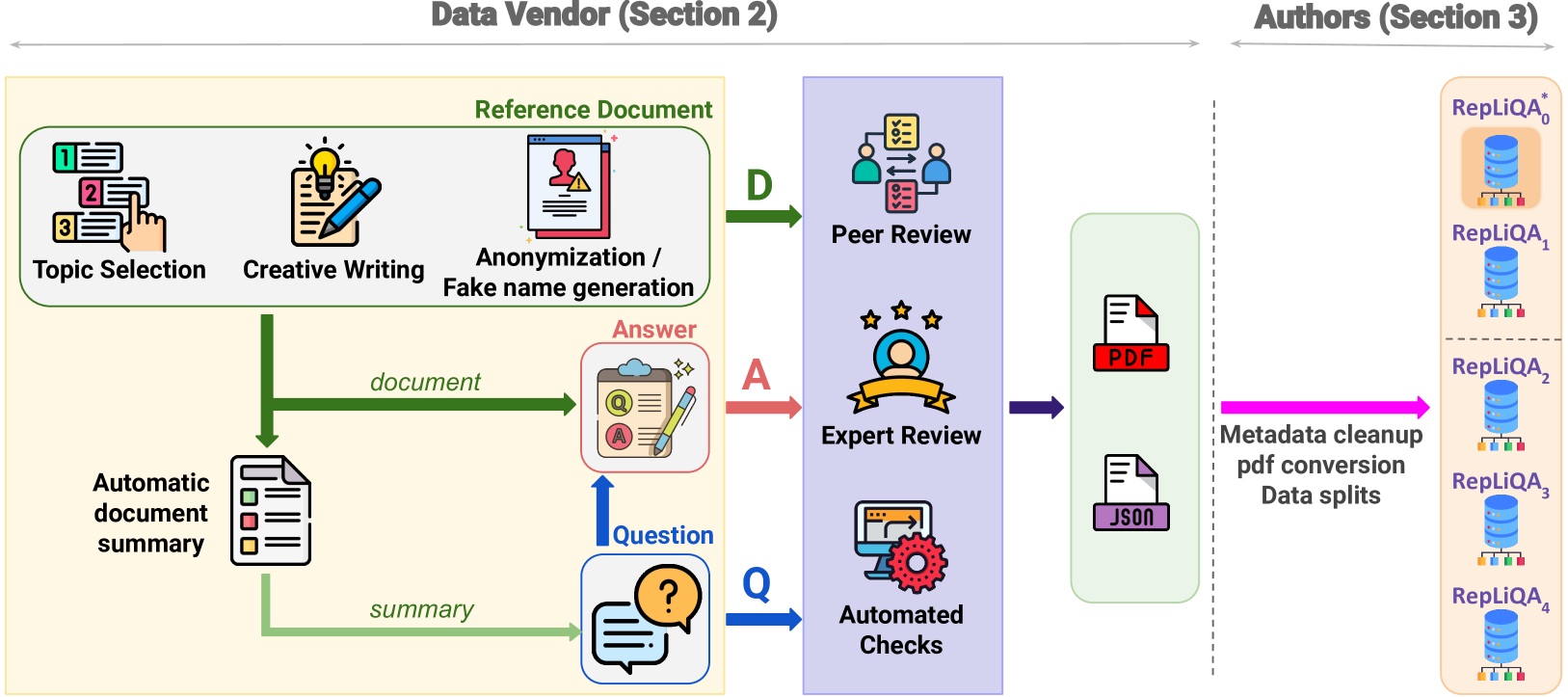
Large Language Models (LLMs) are trained on vast amounts of data, most of which is automatically scraped from the internet. This data includes encyclopedic documents that harbor a vast amount of general knowledge (e.g., Wikipedia) but also potentially overlap with benchmark datasets used for evaluating LLMs. Consequently, evaluating models on test splits that might have leaked into the training set is prone to misleading conclusions. To foster sound evaluation of language models, we introduce a new test dataset named RepLiQA, suited for question-answering and topic retrieval tasks. RepLiQA is a collection of five splits of test sets, four of which have not been released to the internet or exposed to LLM APIs prior to this publication. Each sample in RepLiQA comprises (1) a reference document crafted by a human annotator and depicting an imaginary scenario (e.g., a news article) absent from the internet; (2) a question about the document's topic; (3) a ground-truth answer derived directly from the information in the document; and (4) the paragraph extracted from the reference document containing the answer. As such, accurate answers can only be generated if a model can find relevant content within the provided document. We run a large-scale benchmark comprising several state-of-the-art LLMs to uncover differences in performance across models of various types and sizes in a context-conditional language modeling setting. Released splits of RepLiQA can be found here: https://huggingface.co/datasets/ServiceNow/repliqa.
Create account to get full access
Overview
- The paper presents a new dataset called RepLiQA, which is designed to evaluate the ability of large language models (LLMs) to answer questions using unseen reference content.
- RepLiQA contains question-answer pairs based on passages from academic papers, allowing for the assessment of LLMs' knowledge and reasoning capabilities beyond what is typically covered in existing question-answering datasets.
- The dataset is intended to serve as a benchmark for measuring the progress of LLMs in understanding and reasoning about complex, technical content.
Plain English Explanation
The RepLiQA dataset is a new tool for testing the capabilities of large language models (LLMs) - the powerful artificial intelligence systems that can understand and generate human-like text. Unlike many existing question-answering datasets, which focus on more general knowledge, RepLiQA is based on academic research papers, challenging LLMs to draw insights and provide answers using technical content that they may not have been explicitly trained on.
The idea behind RepLiQA is to create a more rigorous way to evaluate how well LLMs can comprehend and reason about complex information, beyond just reciting facts. By having the models answer questions about research papers, the dataset aims to assess their deeper understanding and ability to apply their knowledge in novel contexts. This is an important step in advancing LLM technology, as these systems are increasingly being relied upon for tasks that require sophisticated reasoning and problem-solving skills.
Technical Explanation
The RepLiQA dataset consists of question-answer pairs derived from passages taken from academic papers across a variety of domains, including computer science, physics, and medicine. The questions are designed to test an LLM's ability to understand the content of the passages, extract relevant information, and apply logical reasoning to provide accurate answers.
To create the dataset, the authors first collected a large corpus of academic papers and used natural language processing techniques to identify key passages and generate corresponding questions. The questions cover a range of complexity, from factual recall to more abstract reasoning and inference. The dataset also includes metadata about the paper sources and the types of questions asked, allowing researchers to analyze the performance of LLMs in different areas.
By focusing on unseen reference content, the RepLiQA dataset aims to go beyond the limitations of existing question-answering benchmarks, which may be biased towards the specific knowledge and styles of text that LLMs have been trained on. The authors argue that this approach provides a more rigorous and realistic assessment of an LLM's true understanding and reasoning capabilities.
Critical Analysis
The RepLiQA dataset represents an important step forward in evaluating the capabilities of large language models, but it also has some potential limitations and areas for further research.
One key consideration is the representativeness of the academic paper corpus used to create the dataset. While the authors have aimed to cover a range of domains, the selection of papers may still be biased towards certain fields or styles of writing. This could limit the generalizability of the results to other types of technical content.
Additionally, the authors note that the dataset's questions may not fully capture the nuances of human-like understanding and reasoning. While the questions are designed to be challenging, they may still fall short of the level of complexity and flexibility required for real-world applications of LLM technology.
Further research could explore ways to expand the dataset, such as incorporating more diverse sources of technical content, or developing new question types and evaluation metrics that better align with the ultimate goals of LLM development. Ongoing collaboration between researchers, dataset creators, and LLM developers will be crucial to ensure that benchmarks like RepLiQA continue to drive meaningful progress in the field.
Conclusion
The RepLiQA dataset represents an important step forward in the evaluation of large language models, providing a more rigorous and technically-grounded benchmark for assessing their understanding and reasoning capabilities. By focusing on unseen reference content from academic papers, the dataset challenges LLMs to go beyond the limitations of existing question-answering datasets and demonstrate their true depth of knowledge and problem-solving skills.
While the dataset has some potential limitations, it serves as a valuable tool for researchers and developers working to advance the state of the art in LLM technology. As the field continues to evolve, the lessons learned from RepLiQA and similar benchmarks will be crucial in guiding the development of increasingly capable and versatile language models that can tackle complex, real-world challenges.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
💬
LibriSQA: A Novel Dataset and Framework for Spoken Question Answering with Large Language Models
Zihan Zhao, Yiyang Jiang, Heyang Liu, Yanfeng Wang, Yu Wang
0
0
While Large Language Models (LLMs) have demonstrated commendable performance across a myriad of domains and tasks, existing LLMs still exhibit a palpable deficit in handling multimodal functionalities, especially for the Spoken Question Answering (SQA) task which necessitates precise alignment and deep interaction between speech and text features. To address the SQA challenge on LLMs, we initially curated the free-form and open-ended LibriSQA dataset from Librispeech, comprising Part I with natural conversational formats and Part II encompassing multiple-choice questions followed by answers and analytical segments. Both parts collectively include 107k SQA pairs that cover various topics. Given the evident paucity of existing speech-text LLMs, we propose a lightweight, end-to-end framework to execute the SQA task on the LibriSQA, witnessing significant results. By reforming ASR into the SQA format, we further substantiate our framework's capability in handling ASR tasks. Our empirical findings bolster the LLMs' aptitude for aligning and comprehending multimodal information, paving the way for the development of universal multimodal LLMs. The dataset and demo can be found at https://github.com/ZihanZhaoSJTU/LibriSQA.
4/19/2024
MedREQAL: Examining Medical Knowledge Recall of Large Language Models via Question Answering
Juraj Vladika, Phillip Schneider, Florian Matthes
0
0
In recent years, Large Language Models (LLMs) have demonstrated an impressive ability to encode knowledge during pre-training on large text corpora. They can leverage this knowledge for downstream tasks like question answering (QA), even in complex areas involving health topics. Considering their high potential for facilitating clinical work in the future, understanding the quality of encoded medical knowledge and its recall in LLMs is an important step forward. In this study, we examine the capability of LLMs to exhibit medical knowledge recall by constructing a novel dataset derived from systematic reviews -- studies synthesizing evidence-based answers for specific medical questions. Through experiments on the new MedREQAL dataset, comprising question-answer pairs extracted from rigorous systematic reviews, we assess six LLMs, such as GPT and Mixtral, analyzing their classification and generation performance. Our experimental insights into LLM performance on the novel biomedical QA dataset reveal the still challenging nature of this task.
6/11/2024

NewsQs: Multi-Source Question Generation for the Inquiring Mind
Alyssa Hwang, Kalpit Dixit, Miguel Ballesteros, Yassine Benajiba, Vittorio Castelli, Markus Dreyer, Mohit Bansal, Kathleen McKeown
0
0
We present NewsQs (news-cues), a dataset that provides question-answer pairs for multiple news documents. To create NewsQs, we augment a traditional multi-document summarization dataset with questions automatically generated by a T5-Large model fine-tuned on FAQ-style news articles from the News On the Web corpus. We show that fine-tuning a model with control codes produces questions that are judged acceptable more often than the same model without them as measured through human evaluation. We use a QNLI model with high correlation with human annotations to filter our data. We release our final dataset of high-quality questions, answers, and document clusters as a resource for future work in query-based multi-document summarization.
6/18/2024

SportQA: A Benchmark for Sports Understanding in Large Language Models
Haotian Xia, Zhengbang Yang, Yuqing Wang, Rhys Tracy, Yun Zhao, Dongdong Huang, Zezhi Chen, Yan Zhu, Yuan-fang Wang, Weining Shen
0
0
A deep understanding of sports, a field rich in strategic and dynamic content, is crucial for advancing Natural Language Processing (NLP). This holds particular significance in the context of evaluating and advancing Large Language Models (LLMs), given the existing gap in specialized benchmarks. To bridge this gap, we introduce SportQA, a novel benchmark specifically designed for evaluating LLMs in the context of sports understanding. SportQA encompasses over 70,000 multiple-choice questions across three distinct difficulty levels, each targeting different aspects of sports knowledge from basic historical facts to intricate, scenario-based reasoning tasks. We conducted a thorough evaluation of prevalent LLMs, mainly utilizing few-shot learning paradigms supplemented by chain-of-thought (CoT) prompting. Our results reveal that while LLMs exhibit competent performance in basic sports knowledge, they struggle with more complex, scenario-based sports reasoning, lagging behind human expertise. The introduction of SportQA marks a significant step forward in NLP, offering a tool for assessing and enhancing sports understanding in LLMs.
6/19/2024