No Dimensional Sampling Coresets for Classification

0
🏷️
Sign in to get full access
Overview
- This paper proposes a novel method for creating "coresets" - small subsets of data that can be used to approximate the full dataset for classification tasks.
- The method does not require any dimensionality reduction or feature selection, making it simpler and more efficient than previous coreset approaches.
- The authors provide theoretical guarantees on the approximation error of their coreset method and demonstrate its effectiveness on several real-world datasets.
Plain English Explanation
When working with large datasets, it can be computationally expensive to train machine learning models on the entire dataset. One solution is to create a "coreset" - a smaller subset of the data that can be used instead, while still maintaining the essential characteristics of the full dataset.
The researchers in this paper introduce a new way to create these coresets for classification problems. Their method does not require reducing the number of features or dimensions in the data, which is often a complex and error-prone process. Instead, they select a small number of representative data points that can accurately approximate the full dataset.
The key insight is that they can do this without needing to change the underlying structure or dimensionality of the data. This makes the coreset creation process much simpler and more efficient than previous approaches. The researchers also prove mathematically that their coresets will provide a good approximation of the full dataset, with guarantees on the maximum error.
They then show experimentally that their coreset method performs well on several real-world classification tasks, achieving accuracy comparable to using the full dataset but with much faster training times. This suggests their approach could be very useful for speeding up machine learning on large-scale datasets.
Technical Explanation
The paper introduces a novel "no-dimensional" coreset construction method for classification problems. Coresets are small, weighted subsets of the original data that can be used as a proxy for the full dataset, enabling more efficient computation.
Previous coreset construction techniques have often relied on dimensionality reduction or feature selection to identify the most informative subset of the data. In contrast, the authors' method selects a subset of the original data points without modifying their dimensionality.
The key technical insight is to leverage the structure of the classification problem. The authors show that for any distribution over the data and any set of classifiers, there exists a small coreset that can provably approximate the performance of the full dataset. Importantly, the size of this coreset is independent of the data dimensionality.
The coreset construction algorithm works by iteratively selecting data points that maximize a novel "influence score" which captures how much each point affects the classification objective. The authors provide rigorous theoretical guarantees on the approximation error of the resulting coreset.
Extensive experiments on real-world datasets demonstrate the effectiveness of the no-dimensional coresets. They achieve classification accuracy comparable to using the full dataset, while providing significant speedups in training time - up to 30x faster in some cases. This suggests the proposed method could be a powerful tool for scaling up machine learning on large-scale classification problems.
Critical Analysis
The paper makes a compelling case for the utility of no-dimensional coresets for classification tasks. By avoiding dimensionality reduction or feature engineering, the authors sidestep many of the potential pitfalls associated with those approaches, such as losing important information or introducing bias.
However, the coreset construction process does add some computational overhead, which could be a concern for extremely large datasets or time-sensitive applications. The authors acknowledge this and suggest ways to further optimize the algorithm's efficiency.
Additionally, the theoretical guarantees provided in the paper rely on assumptions about the underlying data distribution and classifier class. While the experiments demonstrate robust performance across diverse real-world datasets, it would be valuable to explore the method's sensitivity to violations of these assumptions.
Finally, the paper focuses primarily on the coreset construction process and its impact on classification performance. An interesting avenue for future research could be to investigate how these no-dimensional coresets might be leveraged in other machine learning tasks, such as clustering or regression.
Conclusion
This paper presents a novel and compelling approach to creating coresets for classification problems. By avoiding the need for dimensionality reduction or feature engineering, the authors have developed a simpler and more efficient coreset construction method that can provide significant computational benefits without compromising model performance.
The theoretical guarantees and empirical results suggest this technique could be a valuable tool for scaling up machine learning on large-scale datasets. As the field of AI continues to grapple with the challenges of working with ever-growing volumes of data, innovations like no-dimensional coresets will likely play an important role in enabling more efficient and effective machine learning.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🏷️
0
No Dimensional Sampling Coresets for Classification
Meysam Alishahi, Jeff M. Phillips
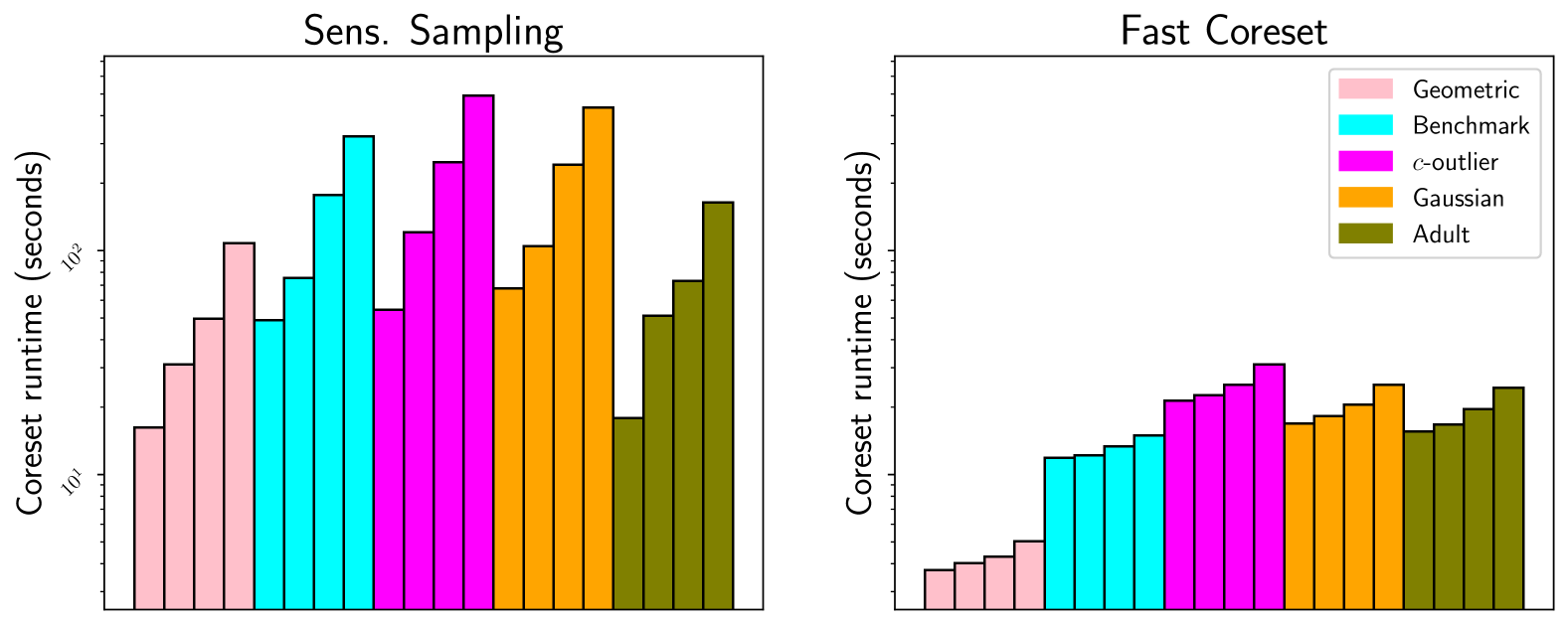
We refine and generalize what is known about coresets for classification problems via the sensitivity sampling framework. Such coresets seek the smallest possible subsets of input data, so one can optimize a loss function on the coreset and ensure approximation guarantees with respect to the original data. Our analysis provides the first no dimensional coresets, so the size does not depend on the dimension. Moreover, our results are general, apply for distributional input and can use iid samples, so provide sample complexity bounds, and work for a variety of loss functions. A key tool we develop is a Radamacher complexity version of the main sensitivity sampling approach, which can be of independent interest.
Read more7/24/2024
0
Settling Time vs. Accuracy Tradeoffs for Clustering Big Data
Andrew Draganov, David Saulpic, Chris Schwiegelshohn
We study the theoretical and practical runtime limits of k-means and k-median clustering on large datasets. Since effectively all clustering methods are slower than the time it takes to read the dataset, the fastest approach is to quickly compress the data and perform the clustering on the compressed representation. Unfortunately, there is no universal best choice for compressing the number of points - while random sampling runs in sublinear time and coresets provide theoretical guarantees, the former does not enforce accuracy while the latter is too slow as the numbers of points and clusters grow. Indeed, it has been conjectured that any sensitivity-based coreset construction requires super-linear time in the dataset size. We examine this relationship by first showing that there does exist an algorithm that obtains coresets via sensitivity sampling in effectively linear time - within log-factors of the time it takes to read the data. Any approach that significantly improves on this must then resort to practical heuristics, leading us to consider the spectrum of sampling strategies across both real and artificial datasets in the static and streaming settings. Through this, we show the conditions in which coresets are necessary for preserving cluster validity as well as the settings in which faster, cruder sampling strategies are sufficient. As a result, we provide a comprehensive theoretical and practical blueprint for effective clustering regardless of data size. Our code is publicly available and has scripts to recreate the experiments.
Read more4/3/2024
0
Spectral Greedy Coresets for Graph Neural Networks
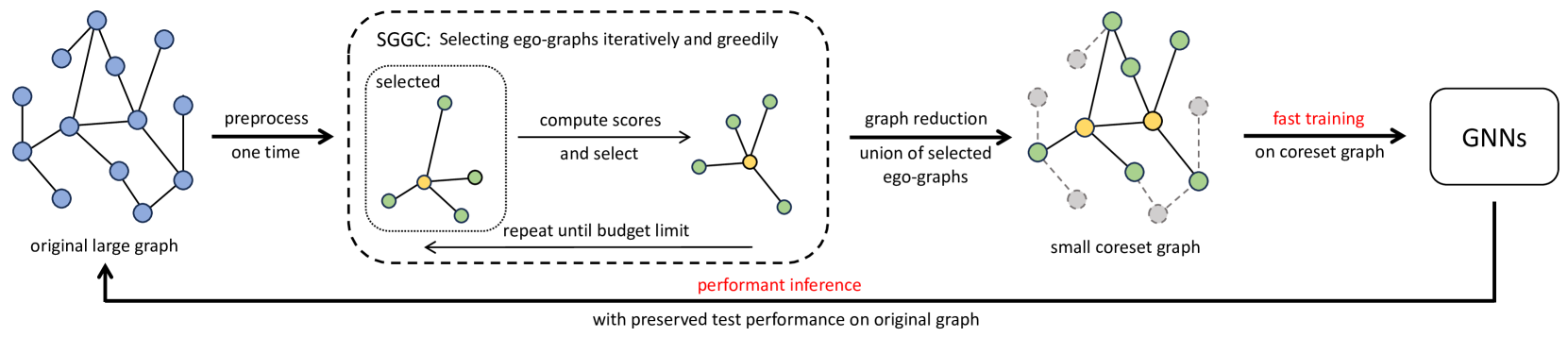
Mucong Ding, Yinhan He, Jundong Li, Furong Huang
The ubiquity of large-scale graphs in node-classification tasks significantly hinders the real-world applications of Graph Neural Networks (GNNs). Node sampling, graph coarsening, and dataset condensation are effective strategies for enhancing data efficiency. However, owing to the interdependence of graph nodes, coreset selection, which selects subsets of the data examples, has not been successfully applied to speed up GNN training on large graphs, warranting special treatment. This paper studies graph coresets for GNNs and avoids the interdependence issue by selecting ego-graphs (i.e., neighborhood subgraphs around a node) based on their spectral embeddings. We decompose the coreset selection problem for GNNs into two phases: a coarse selection of widely spread ego graphs and a refined selection to diversify their topologies. We design a greedy algorithm that approximately optimizes both objectives. Our spectral greedy graph coreset (SGGC) scales to graphs with millions of nodes, obviates the need for model pre-training, and applies to low-homophily graphs. Extensive experiments on ten datasets demonstrate that SGGC outperforms other coreset methods by a wide margin, generalizes well across GNN architectures, and is much faster than graph condensation.
Read more5/28/2024

0
General bounds on the quality of Bayesian coresets
Trevor Campbell
Bayesian coresets speed up posterior inference in the large-scale data regime by approximating the full-data log-likelihood function with a surrogate log-likelihood based on a small, weighted subset of the data. But while Bayesian coresets and methods for construction are applicable in a wide range of models, existing theoretical analysis of the posterior inferential error incurred by coreset approximations only apply in restrictive settings -- i.e., exponential family models, or models with strong log-concavity and smoothness assumptions. This work presents general upper and lower bounds on the Kullback-Leibler (KL) divergence of coreset approximations that reflect the full range of applicability of Bayesian coresets. The lower bounds require only mild model assumptions typical of Bayesian asymptotic analyses, while the upper bounds require the log-likelihood functions to satisfy a generalized subexponentiality criterion that is weaker than conditions used in earlier work. The lower bounds are applied to obtain fundamental limitations on the quality of coreset approximations, and to provide a theoretical explanation for the previously-observed poor empirical performance of importance sampling-based construction methods. The upper bounds are used to analyze the performance of recent subsample-optimize methods. The flexibility of the theory is demonstrated in validation experiments involving multimodal, unidentifiable, heavy-tailed Bayesian posterior distributions.
Read more5/21/2024