No Free Lunch in LLM Watermarking: Trade-offs in Watermarking Design Choices
2402.16187
0
0
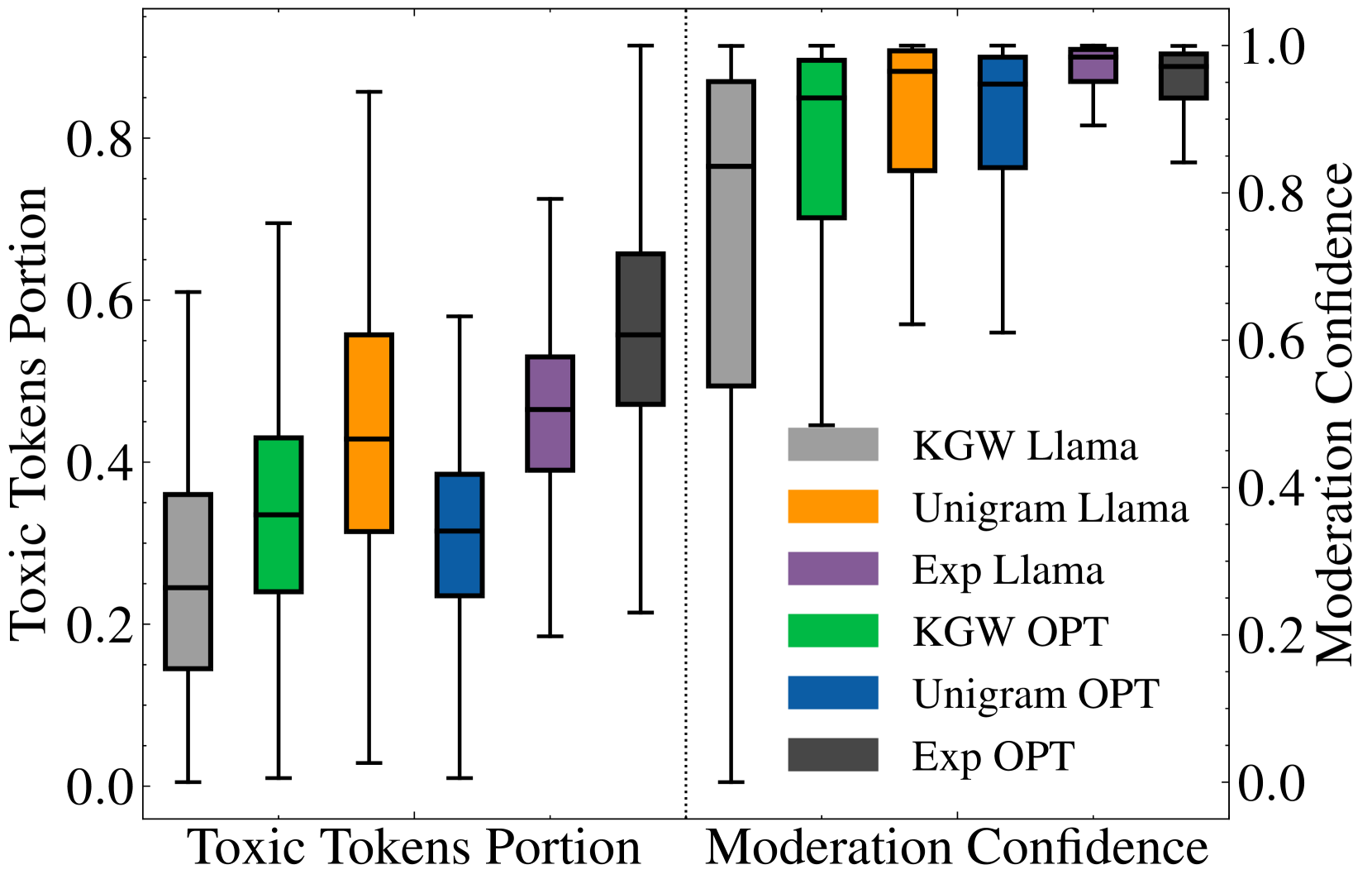
Abstract
Advances in generative models have made it possible for AI-generated text, code, and images to mirror human-generated content in many applications. Watermarking, a technique that aims to embed information in the output of a model to verify its source, is useful for mitigating the misuse of such AI-generated content. However, we show that common design choices in LLM watermarking schemes make the resulting systems surprisingly susceptible to attack -- leading to fundamental trade-offs in robustness, utility, and usability. To navigate these trade-offs, we rigorously study a set of simple yet effective attacks on common watermarking systems, and propose guidelines and defenses for LLM watermarking in practice.
Create account to get full access
Overview
- This research paper explores a new approach to attacking watermarks used to identify text generated by large language models (LLMs).
- The authors propose exploiting the strengths of watermarking techniques, rather than trying to remove or bypass them directly.
- The paper investigates how certain watermark properties, such as their learnability and linguistic nature, can be leveraged to generate adversarial examples that evade detection.
Plain English Explanation
The paper focuses on a specific security challenge with large language models (LLMs) - the use of watermarks to detect when an LLM has generated a piece of text. Watermarks are like digital "fingerprints" that are embedded in the text, allowing the model's creators to identify when their LLM has been used.
Rather than trying to remove or hide these watermarks, the researchers in this paper took a different approach. They explored how they could actually <a href="https://aimodels.fyi/papers/arxiv/learnable-linguistic-watermarks-tracing-model-extraction-attacks">exploit the strengths of the watermarking techniques</a> to generate text that would evade detection.
The key insight is that many watermarking methods rely on properties of the text, such as its linguistic patterns or "learnability" (how easily the watermark can be detected by machine learning models). The researchers found ways to leverage these very properties to create adversarial examples - text that looks natural but is specifically crafted to avoid triggering the watermark detection.
By understanding <a href="https://aimodels.fyi/papers/arxiv/reliability-watermarks-large-language-models">how watermarking systems work</a> and the design choices behind them, the researchers were able to develop techniques that could reliably bypass these security measures. This highlights the importance of carefully considering the potential weaknesses and vulnerabilities of any security system, even one as sophisticated as watermarking for LLMs.
Technical Explanation
The paper begins by providing background on the use of <a href="https://aimodels.fyi/papers/arxiv/topic-based-watermarks-llm-generated-text">watermarks in large language models</a> to detect and trace generated text. The authors then introduce their key insight - that rather than trying to remove or hide these watermarks, they can instead be exploited by targeting their specific design properties.
The researchers identified two key watermark properties that could be leveraged: learnability and linguistic nature. They developed techniques to generate adversarial examples that would evade detection by watermark classifiers trained to identify the telltale patterns left by these watermarks.
For the learnability-based attacks, the authors trained substitute models to mimic the watermark classifier's behavior, allowing them to generate text that would bypass detection. They also explored techniques to <a href="https://aimodels.fyi/papers/arxiv/learnability-watermarks-language-models">reduce the learnability</a> of the watermarks themselves.
To target the linguistic nature of watermarks, the researchers developed methods to generate text with natural-sounding linguistic features that would conceal the watermark signals. This involved carefully modeling the target language distribution to create adversarial examples that appear genuine.
Through extensive experimentation, the authors demonstrated the effectiveness of their attack strategies against several state-of-the-art watermarking systems. They were able to generate text that was virtually indistinguishable from genuine LLM output, while still successfully evading the watermark detection.
Critical Analysis
The researchers in this paper took an innovative and thoughtful approach to the problem of watermark evasion. Rather than simply trying to remove or bypass the watermarks, they recognized the importance of understanding the underlying design choices and leveraging those strengths against the watermarking systems.
One potential limitation of the research is that it focuses primarily on attacking the watermarking techniques themselves, without considering broader system-level security implications. In a real-world deployment, watermarks would likely be just one component of a multi-layered defense strategy, and the authors don't explore how their attacks might interact with other security measures.
Additionally, while the experiments demonstrate the effectiveness of the attack strategies, there may be practical constraints or other factors that could limit their real-world applicability. For example, the need to train substitute models or carefully model language distributions may introduce additional complexity or computational overhead.
It's also worth noting that the research raises important ethical questions about the development and use of such adversarial techniques. While the authors frame their work as a necessary exploration of watermark vulnerabilities, there is the potential for these techniques to be misused by bad actors to evade detection and accountability. <a href="https://aimodels.fyi/papers/arxiv/watermark-large-language-models">Responsible watermarking and security practices</a> will be crucial to mitigate these risks.
Conclusion
This research paper presents a novel approach to attacking watermarking systems used to identify text generated by large language models. By exploiting the inherent strengths and design choices of watermarking techniques, the authors were able to develop effective adversarial strategies that could reliably evade detection.
The findings highlight the importance of carefully considering the potential vulnerabilities and weaknesses of any security system, even one as sophisticated as watermarking. As LLMs become more prevalent and powerful, ensuring their responsible development and use will require a multifaceted approach that anticipates and addresses these types of security challenges.
While the paper raises important ethical concerns, the insights it provides can also inform the development of more robust and resilient watermarking systems, ultimately contributing to the safe and trustworthy deployment of large language models in the future.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
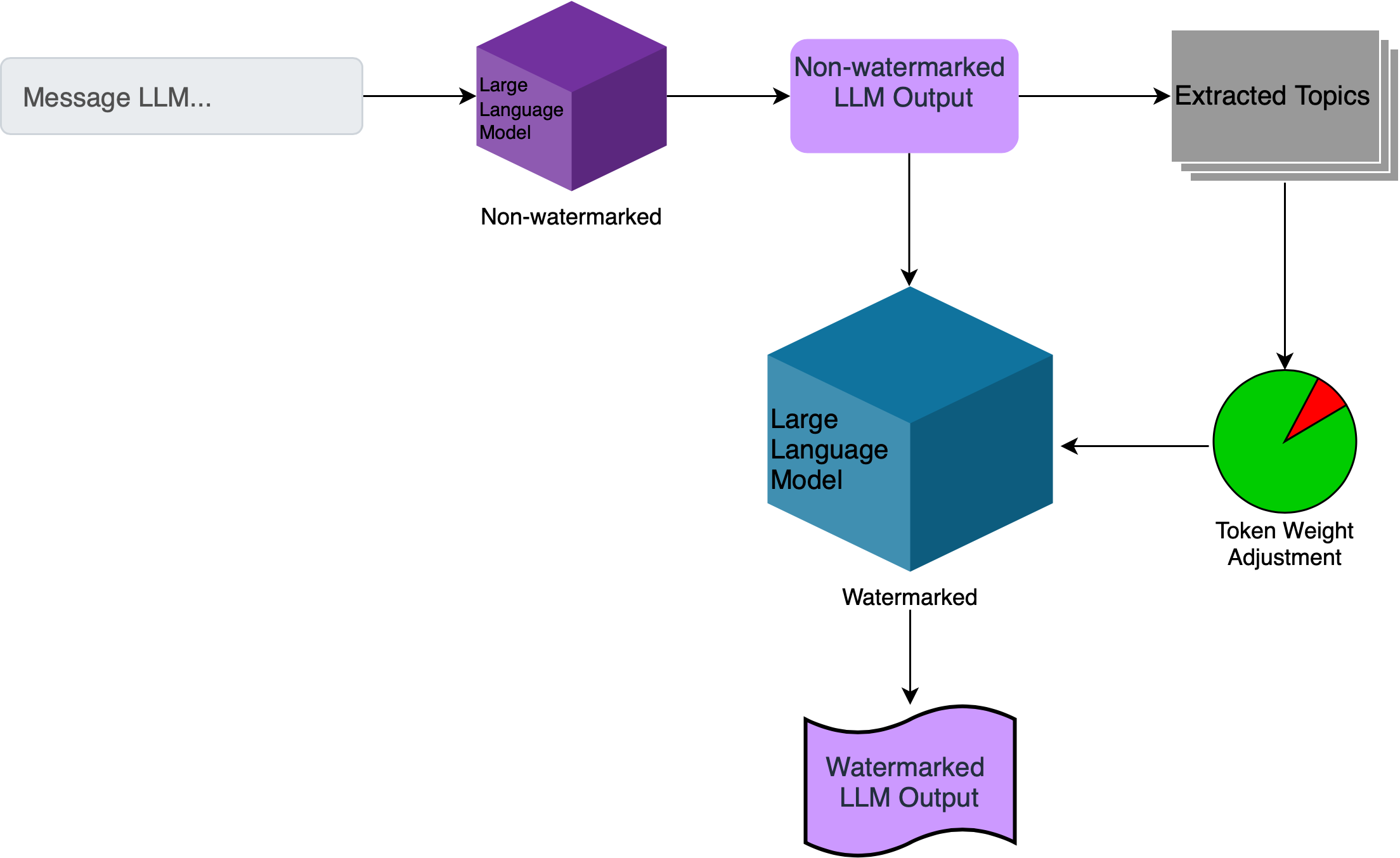
Topic-based Watermarks for LLM-Generated Text
Alexander Nemecek, Yuzhou Jiang, Erman Ayday
0
0
Recent advancements of large language models (LLMs) have resulted in indistinguishable text outputs comparable to human-generated text. Watermarking algorithms are potential tools that offer a way to differentiate between LLM- and human-generated text by embedding detectable signatures within LLM-generated output. However, current watermarking schemes lack robustness against known attacks against watermarking algorithms. In addition, they are impractical considering an LLM generates tens of thousands of text outputs per day and the watermarking algorithm needs to memorize each output it generates for the detection to work. In this work, focusing on the limitations of current watermarking schemes, we propose the concept of a topic-based watermarking algorithm for LLMs. The proposed algorithm determines how to generate tokens for the watermarked LLM output based on extracted topics of an input prompt or the output of a non-watermarked LLM. Inspired from previous work, we propose using a pair of lists (that are generated based on the specified extracted topic(s)) that specify certain tokens to be included or excluded while generating the watermarked output of the LLM. Using the proposed watermarking algorithm, we show the practicality of a watermark detection algorithm. Furthermore, we discuss a wide range of attacks that can emerge against watermarking algorithms for LLMs and the benefit of the proposed watermarking scheme for the feasibility of modeling a potential attacker considering its benefit vs. loss.
4/17/2024
💬
On the Reliability of Watermarks for Large Language Models
John Kirchenbauer, Jonas Geiping, Yuxin Wen, Manli Shu, Khalid Saifullah, Kezhi Kong, Kasun Fernando, Aniruddha Saha, Micah Goldblum, Tom Goldstein
0
0
As LLMs become commonplace, machine-generated text has the potential to flood the internet with spam, social media bots, and valueless content. Watermarking is a simple and effective strategy for mitigating such harms by enabling the detection and documentation of LLM-generated text. Yet a crucial question remains: How reliable is watermarking in realistic settings in the wild? There, watermarked text may be modified to suit a user's needs, or entirely rewritten to avoid detection. We study the robustness of watermarked text after it is re-written by humans, paraphrased by a non-watermarked LLM, or mixed into a longer hand-written document. We find that watermarks remain detectable even after human and machine paraphrasing. While these attacks dilute the strength of the watermark, paraphrases are statistically likely to leak n-grams or even longer fragments of the original text, resulting in high-confidence detections when enough tokens are observed. For example, after strong human paraphrasing the watermark is detectable after observing 800 tokens on average, when setting a 1e-5 false positive rate. We also consider a range of new detection schemes that are sensitive to short spans of watermarked text embedded inside a large document, and we compare the robustness of watermarking to other kinds of detectors.
5/3/2024
💬
Watermark Stealing in Large Language Models
Nikola Jovanovi'c, Robin Staab, Martin Vechev
0
0
LLM watermarking has attracted attention as a promising way to detect AI-generated content, with some works suggesting that current schemes may already be fit for deployment. In this work we dispute this claim, identifying watermark stealing (WS) as a fundamental vulnerability of these schemes. We show that querying the API of the watermarked LLM to approximately reverse-engineer a watermark enables practical spoofing attacks, as hypothesized in prior work, but also greatly boosts scrubbing attacks, which was previously unnoticed. We are the first to propose an automated WS algorithm and use it in the first comprehensive study of spoofing and scrubbing in realistic settings. We show that for under $50 an attacker can both spoof and scrub state-of-the-art schemes previously considered safe, with average success rate of over 80%. Our findings challenge common beliefs about LLM watermarking, stressing the need for more robust schemes. We make all our code and additional examples available at https://watermark-stealing.org.
6/26/2024
📈
Learnable Linguistic Watermarks for Tracing Model Extraction Attacks on Large Language Models
Minhao Bai, Kaiyi Pang, Yongfeng Huang
0
0
In the rapidly evolving domain of artificial intelligence, safeguarding the intellectual property of Large Language Models (LLMs) is increasingly crucial. Current watermarking techniques against model extraction attacks, which rely on signal insertion in model logits or post-processing of generated text, remain largely heuristic. We propose a novel method for embedding learnable linguistic watermarks in LLMs, aimed at tracing and preventing model extraction attacks. Our approach subtly modifies the LLM's output distribution by introducing controlled noise into token frequency distributions, embedding an statistically identifiable controllable watermark.We leverage statistical hypothesis testing and information theory, particularly focusing on Kullback-Leibler Divergence, to differentiate between original and modified distributions effectively. Our watermarking method strikes a delicate well balance between robustness and output quality, maintaining low false positive/negative rates and preserving the LLM's original performance.
5/3/2024