On the Reliability of Watermarks for Large Language Models
2306.04634
0
0
💬
Abstract
As LLMs become commonplace, machine-generated text has the potential to flood the internet with spam, social media bots, and valueless content. Watermarking is a simple and effective strategy for mitigating such harms by enabling the detection and documentation of LLM-generated text. Yet a crucial question remains: How reliable is watermarking in realistic settings in the wild? There, watermarked text may be modified to suit a user's needs, or entirely rewritten to avoid detection. We study the robustness of watermarked text after it is re-written by humans, paraphrased by a non-watermarked LLM, or mixed into a longer hand-written document. We find that watermarks remain detectable even after human and machine paraphrasing. While these attacks dilute the strength of the watermark, paraphrases are statistically likely to leak n-grams or even longer fragments of the original text, resulting in high-confidence detections when enough tokens are observed. For example, after strong human paraphrasing the watermark is detectable after observing 800 tokens on average, when setting a 1e-5 false positive rate. We also consider a range of new detection schemes that are sensitive to short spans of watermarked text embedded inside a large document, and we compare the robustness of watermarking to other kinds of detectors.
Create account to get full access
Overview
- As large language models (LLMs) become more common, there is a risk of machine-generated text being used for spam, bots, and low-quality content online.
- Watermarking is a strategy to detect and document LLM-generated text, but its reliability in real-world settings is unclear.
- This paper studies the robustness of watermarking when text is rewritten by humans, paraphrased by non-watermarked LLMs, or mixed into longer hand-written documents.
Plain English Explanation
The rapid development of large language models (LLMs) has led to concerns about malicious actors using these models to generate vast amounts of spam, fake social media posts, and other low-value content. One approach to addressing this is watermarking, which involves embedding a hidden signal in the text to enable detection of machine-generated content.
However, a key question is how effective watermarking remains in realistic scenarios where the generated text may be modified. For example, a user could manually rephrase the watermarked text to suit their needs, or an adversary could use another LLM to paraphrase the text and try to remove the watermark.
This paper examines the robustness of watermarking against these types of "attacks". The researchers find that even after strong human paraphrasing or LLM-based rewrites, the watermark can still be detected with high confidence by observing enough of the modified text. This is because the paraphrased versions often retain short fragments or statistical patterns from the original watermarked text.
The paper also explores new detection methods that are sensitive to detecting small amounts of watermarked text embedded within larger documents. Overall, the results suggest that watermarking can be a reliable way to identify machine-generated content, even when attempts are made to obscure or remove the watermark.
Technical Explanation
The researchers conducted a series of experiments to test the robustness of watermarked text against different "attacks":
- Human rewriting: They had people manually rewrite watermarked text in their own words, aiming to preserve the meaning while obscuring the watermark.
- LLM paraphrasing: They used a non-watermarked LLM to automatically paraphrase the watermarked text.
- Mixing into longer documents: They embedded the watermarked text within longer, hand-written documents.
Even after these modifications, the researchers found that the watermark could still be detected with high confidence by observing a sufficient amount of the altered text. For example, after strong human paraphrasing, the watermark was detectable on average after seeing 800 tokens, when setting a low 1-in-100,000 false positive rate.
The paper also introduces new watermark detection schemes that are specifically designed to be sensitive to short spans of watermarked text within larger documents. These detectors were found to be more robust than previous approaches.
Overall, the results demonstrate that watermarking is a promising technique for mitigating the risks of machine-generated text, as the watermark remains detectable even after attempts to obscure or remove it. However, the researchers note that further work is needed to fully understand the limitations and optimal application of watermarking in real-world settings.
Critical Analysis
The paper provides compelling evidence that watermarking can be a robust defense against malicious uses of LLM-generated text, even when the text is modified. However, a few potential limitations and areas for further research are worth considering:
- The experiments focused on relatively simple paraphrasing and rewriting attacks. More sophisticated techniques, such as using multiple LLMs in sequence or combining paraphrasing with other obfuscation methods, may pose greater challenges for watermark detection.
- The research did not explore the scalability and computational efficiency of the watermark detection methods, which could be important considerations for real-world deployment at large scale.
- While the paper compared watermarking to other detection approaches, a more comprehensive benchmarking against a wider range of detection techniques would help further assess the relative strengths and weaknesses of watermarking.
Additionally, the researchers acknowledge that more work is needed to understand the best practices for implementing watermarking, such as how to design effective watermarks and integrate detection into relevant applications and workflows.
Overall, this paper makes a valuable contribution by demonstrating the resilience of watermarking against common text modification attacks. However, ongoing research and development will be necessary to ensure the long-term effectiveness of this approach as an anti-spam and content integrity measure in the face of evolving LLM-based threats.
Conclusion
As LLMs become more widespread, the risk of machine-generated text being misused for spam, misinformation, and low-quality content grows. This paper shows that watermarking can be a robust strategy for detecting and documenting LLM-generated text, even when the text is rewritten by humans or automatically paraphrased.
The key finding is that watermarks remain detectable with high confidence after these types of "attacks", as the modified text often retains statistical patterns or short fragments of the original watermarked content. This suggests watermarking could be an effective tool for maintaining content integrity and combating the potential harms of LLM-generated text on a large scale.
While further research is needed to fully understand the limitations and optimal implementation of watermarking, this paper makes an important contribution to addressing a critical challenge posed by the rise of advanced language models. As these technologies become more ubiquitous, developing reliable methods for identifying machine-generated content will be crucial for preserving the integrity and value of information online.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
💬
Robust Distortion-free Watermarks for Language Models
Rohith Kuditipudi, John Thickstun, Tatsunori Hashimoto, Percy Liang
0
0
We propose a methodology for planting watermarks in text from an autoregressive language model that are robust to perturbations without changing the distribution over text up to a certain maximum generation budget. We generate watermarked text by mapping a sequence of random numbers -- which we compute using a randomized watermark key -- to a sample from the language model. To detect watermarked text, any party who knows the key can align the text to the random number sequence. We instantiate our watermark methodology with two sampling schemes: inverse transform sampling and exponential minimum sampling. We apply these watermarks to three language models -- OPT-1.3B, LLaMA-7B and Alpaca-7B -- to experimentally validate their statistical power and robustness to various paraphrasing attacks. Notably, for both the OPT-1.3B and LLaMA-7B models, we find we can reliably detect watermarked text ($p leq 0.01$) from $35$ tokens even after corrupting between $40$-$50%$ of the tokens via random edits (i.e., substitutions, insertions or deletions). For the Alpaca-7B model, we conduct a case study on the feasibility of watermarking responses to typical user instructions. Due to the lower entropy of the responses, detection is more difficult: around $25%$ of the responses -- whose median length is around $100$ tokens -- are detectable with $p leq 0.01$, and the watermark is also less robust to certain automated paraphrasing attacks we implement.
6/7/2024
💬
A Watermark for Large Language Models
John Kirchenbauer, Jonas Geiping, Yuxin Wen, Jonathan Katz, Ian Miers, Tom Goldstein
0
0
Potential harms of large language models can be mitigated by watermarking model output, i.e., embedding signals into generated text that are invisible to humans but algorithmically detectable from a short span of tokens. We propose a watermarking framework for proprietary language models. The watermark can be embedded with negligible impact on text quality, and can be detected using an efficient open-source algorithm without access to the language model API or parameters. The watermark works by selecting a randomized set of green tokens before a word is generated, and then softly promoting use of green tokens during sampling. We propose a statistical test for detecting the watermark with interpretable p-values, and derive an information-theoretic framework for analyzing the sensitivity of the watermark. We test the watermark using a multi-billion parameter model from the Open Pretrained Transformer (OPT) family, and discuss robustness and security.
5/3/2024
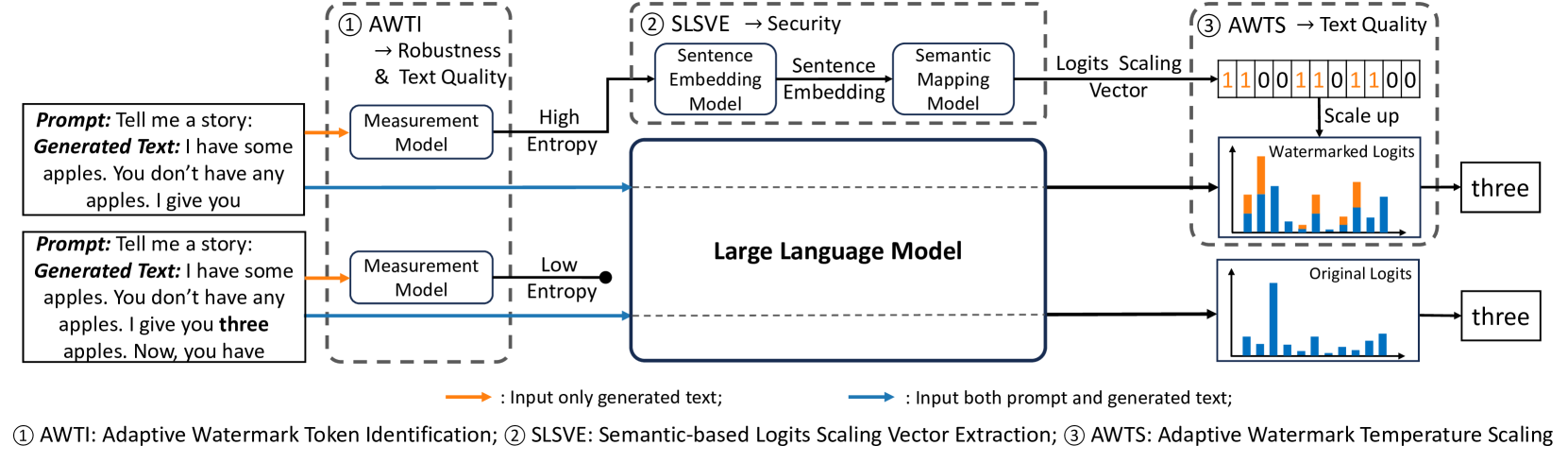
Adaptive Text Watermark for Large Language Models
Yepeng Liu, Yuheng Bu
0
0
The advancement of Large Language Models (LLMs) has led to increasing concerns about the misuse of AI-generated text, and watermarking for LLM-generated text has emerged as a potential solution. However, it is challenging to generate high-quality watermarked text while maintaining strong security, robustness, and the ability to detect watermarks without prior knowledge of the prompt or model. This paper proposes an adaptive watermarking strategy to address this problem. To improve the text quality and maintain robustness, we adaptively add watermarking to token distributions with high entropy measured using an auxiliary model and keep the low entropy token distributions untouched. For the sake of security and to further minimize the watermark's impact on text quality, instead of using a fixed green/red list generated from a random secret key, which can be vulnerable to decryption and forgery, we adaptively scale up the output logits in proportion based on the semantic embedding of previously generated text using a well designed semantic mapping model. Our experiments involving various LLMs demonstrate that our approach achieves comparable robustness performance to existing watermark methods. Additionally, the text generated by our method has perplexity comparable to that of emph{un-watermarked} LLMs while maintaining security even under various attacks.
6/11/2024
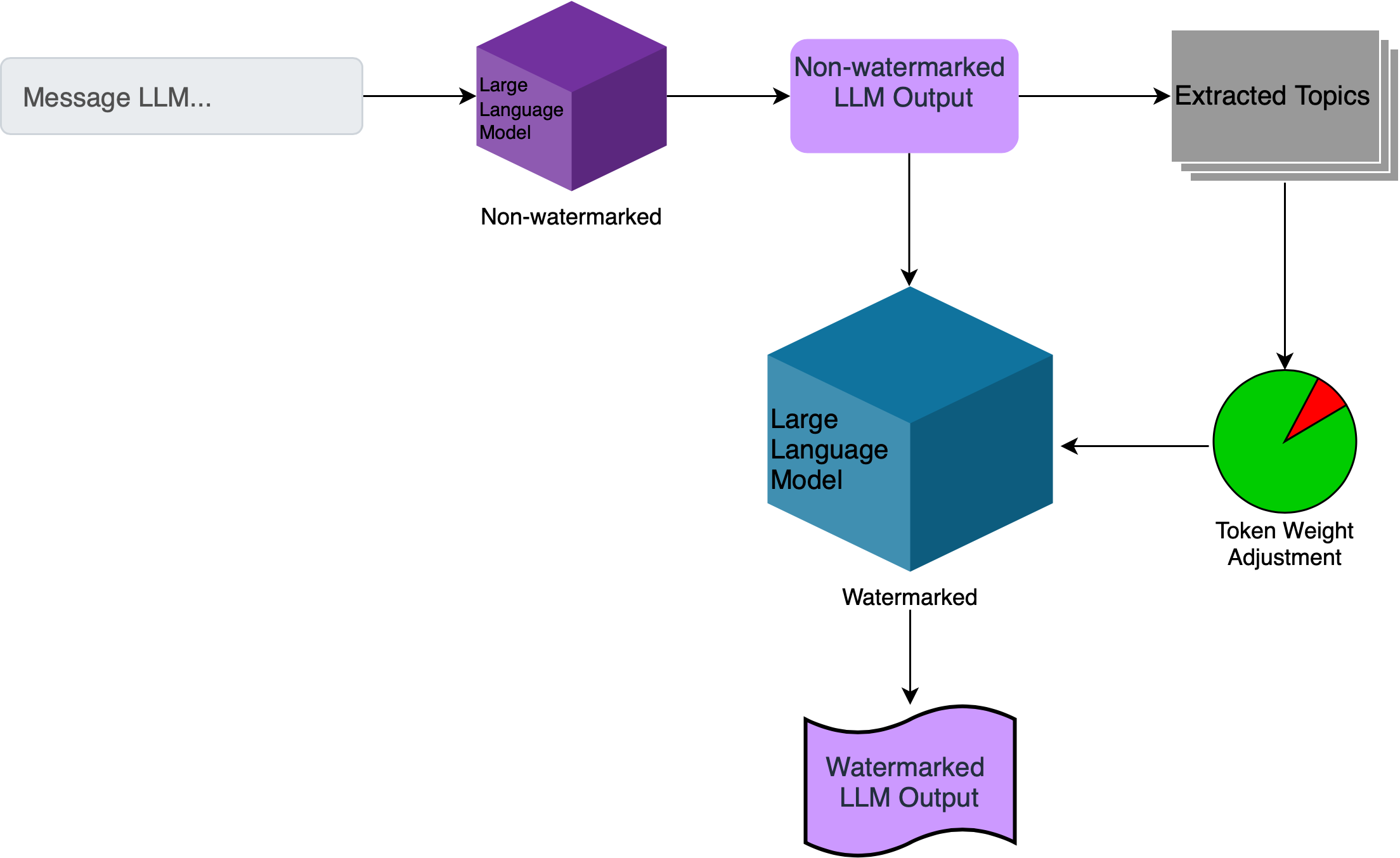
Topic-based Watermarks for LLM-Generated Text
Alexander Nemecek, Yuzhou Jiang, Erman Ayday
0
0
Recent advancements of large language models (LLMs) have resulted in indistinguishable text outputs comparable to human-generated text. Watermarking algorithms are potential tools that offer a way to differentiate between LLM- and human-generated text by embedding detectable signatures within LLM-generated output. However, current watermarking schemes lack robustness against known attacks against watermarking algorithms. In addition, they are impractical considering an LLM generates tens of thousands of text outputs per day and the watermarking algorithm needs to memorize each output it generates for the detection to work. In this work, focusing on the limitations of current watermarking schemes, we propose the concept of a topic-based watermarking algorithm for LLMs. The proposed algorithm determines how to generate tokens for the watermarked LLM output based on extracted topics of an input prompt or the output of a non-watermarked LLM. Inspired from previous work, we propose using a pair of lists (that are generated based on the specified extracted topic(s)) that specify certain tokens to be included or excluded while generating the watermarked output of the LLM. Using the proposed watermarking algorithm, we show the practicality of a watermark detection algorithm. Furthermore, we discuss a wide range of attacks that can emerge against watermarking algorithms for LLMs and the benefit of the proposed watermarking scheme for the feasibility of modeling a potential attacker considering its benefit vs. loss.
4/17/2024