Noise-Robust Voice Conversion by Conditional Denoising Training Using Latent Variables of Recording Quality and Environment

0

Sign in to get full access
Overview
- This paper proposes a noise-robust voice conversion (VC) method that uses conditional denoising training with latent variables to improve the quality and robustness of the converted voice in noisy environments.
- The key idea is to incorporate information about the recording quality and environment as latent variables during the training process, allowing the model to better adapt to diverse noise conditions.
- The proposed method aims to outperform conventional denoising-based VC approaches by leveraging this additional information to generate higher-quality and more noise-robust converted speech.
Plain English Explanation
Voice conversion (VC) is a technology that can change the voice of a speaker to sound like another person. However, one challenge with VC is that the converted voice may not sound natural or may be affected by background noise or environmental factors.
The researchers in this paper have developed a new VC method that tries to address this problem. Their approach uses "latent variables" to capture information about the quality of the recording and the environment where the speech was recorded. During the training process, the model learns to use this additional information to generate converted speech that sounds more natural and is less affected by noise.
The key idea is that by incorporating these latent variables, the model can better adapt to different noise conditions and produce higher-quality voice conversions, even in challenging acoustic environments. This could be useful for applications like voice assistants, audiobook narration, or dubbing, where the converted voice needs to sound natural and clear.
Technical Explanation
The researchers propose a noise-robust voice conversion (VC) method that uses conditional denoising training with latent variables to improve the quality and robustness of the converted voice in noisy environments.
The core of their approach is to incorporate information about the recording quality and environment as latent variables during the training process. Specifically, the model learns to predict not only the target voice, but also these latent variables that capture properties of the noise and recording conditions.
By conditioning the VC model on these latent variables, the researchers aim to enable the model to better adapt to diverse noise conditions and generate higher-quality, more noise-robust converted speech compared to conventional denoising-based VC approaches.
The proposed method consists of three key components:
- A VC model that takes the source speech, noise information, and speaker identity as inputs and generates the converted speech.
- A denoising model that predicts the latent variables representing the recording quality and environment.
- A conditional denoising training procedure that jointly optimizes the VC and denoising models.
The researchers evaluate their method on several benchmark datasets and show that it outperforms existing noise-robust VC techniques in terms of speech quality and robustness to noise. They also provide analysis and ablation studies to better understand the contribution of the latent variables and the importance of the conditional denoising training.
Critical Analysis
The key strength of this work is the novel idea of incorporating latent variables representing recording quality and environment into the VC training process. This allows the model to better adapt to diverse noise conditions and generate more robust and higher-quality converted speech.
However, the paper does not address several important practical considerations. For example, it's unclear how the model would perform with real-world noisy recordings, as the experiments only consider simulated noise conditions. Additionally, the computational and memory requirements of the proposed method are not discussed, which could be a concern for deployment in resource-constrained settings.
Another limitation is the lack of subjective evaluation by human listeners. While the objective metrics suggest improved performance, it would be valuable to understand the perceptual impact of the proposed method on end-users.
Finally, the paper does not explore the potential for the latent variables to provide additional functionalities, such as controlling the degree of noise suppression or enabling fine-grained manipulation of the converted voice characteristics. Investigating these directions could further expand the capabilities and applicability of the proposed approach.
Overall, this work presents a promising direction for improving the noise robustness of voice conversion, but additional research is needed to address the practical challenges and fully realize the potential of this approach.
Conclusion
This paper introduces a novel noise-robust voice conversion method that leverages latent variables representing recording quality and environment to generate higher-quality and more noise-resilient converted speech.
The key innovation is the incorporation of these latent variables into the conditional denoising training process, which allows the model to better adapt to diverse noise conditions. The researchers demonstrate the effectiveness of their approach through extensive experiments, showing improvements over conventional denoising-based VC techniques.
While the paper presents an interesting and potentially impactful contribution to the field of voice conversion, it also highlights the need for further research to address practical considerations and explore additional capabilities of the proposed method. By continuing to advance the state-of-the-art in noise-robust VC, this work could have valuable applications in a wide range of audio-based technologies and services.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Noise-Robust Voice Conversion by Conditional Denoising Training Using Latent Variables of Recording Quality and Environment
Takuto Igarashi, Yuki Saito, Kentaro Seki, Shinnosuke Takamichi, Ryuichi Yamamoto, Kentaro Tachibana, Hiroshi Saruwatari
We propose noise-robust voice conversion (VC) which takes into account the recording quality and environment of noisy source speech. Conventional denoising training improves the noise robustness of a VC model by learning noisy-to-clean VC process. However, the naturalness of the converted speech is limited when the noise of the source speech is unseen during the training. To this end, our proposed training conditions a VC model on two latent variables representing the recording quality and environment of the source speech. These latent variables are derived from deep neural networks pre-trained on recording quality assessment and acoustic scene classification and calculated in an utterance-wise or frame-wise manner. As a result, the trained VC model can explicitly learn information about speech degradation during the training. Objective and subjective evaluations show that our training improves the quality of the converted speech compared to the conventional training.
Read more6/12/2024

0
VC-ENHANCE: Speech Restoration with Integrated Noise Suppression and Voice Conversion
Kyungguen Byun, Jason Filos, Erik Visser, Sunkuk Moon
Noise suppression (NS) algorithms are effective in improving speech quality in many cases. However, aggressive noise suppression can damage the target speech, reducing both speech intelligibility and quality despite removing the noise. This study proposes an explicit speech restoration method using a voice conversion (VC) technique for restoration after noise suppression. We observed that high-quality speech can be restored through a diffusion-based voice conversion stage, conditioned on the target speaker embedding and speech content information extracted from the de-noised speech. This speech restoration can achieve enhancement effects such as bandwidth extension, de-reverberation, and in-painting. Our experimental results demonstrate that this two-stage NS+VC framework outperforms single-stage enhancement models in terms of output speech quality, as measured by objective metrics, while scoring slightly lower in speech intelligibility. To further improve the intelligibility of the combined system, we propose a content encoder adaptation method for robust content extraction in noisy conditions.
Read more9/11/2024
⛏️
0
SelfVC: Voice Conversion With Iterative Refinement using Self Transformations
Paarth Neekhara, Shehzeen Hussain, Rafael Valle, Boris Ginsburg, Rishabh Ranjan, Shlomo Dubnov, Farinaz Koushanfar, Julian McAuley
We propose SelfVC, a training strategy to iteratively improve a voice conversion model with self-synthesized examples. Previous efforts on voice conversion focus on factorizing speech into explicitly disentangled representations that separately encode speaker characteristics and linguistic content. However, disentangling speech representations to capture such attributes using task-specific loss terms can lead to information loss. In this work, instead of explicitly disentangling attributes with loss terms, we present a framework to train a controllable voice conversion model on entangled speech representations derived from self-supervised learning (SSL) and speaker verification models. First, we develop techniques to derive prosodic information from the audio signal and SSL representations to train predictive submodules in the synthesis model. Next, we propose a training strategy to iteratively improve the synthesis model for voice conversion, by creating a challenging training objective using self-synthesized examples. We demonstrate that incorporating such self-synthesized examples during training improves the speaker similarity of generated speech as compared to a baseline voice conversion model trained solely on heuristically perturbed inputs. Our framework is trained without any text and achieves state-of-the-art results in zero-shot voice conversion on metrics evaluating naturalness, speaker similarity, and intelligibility of synthesized audio.
Read more5/6/2024
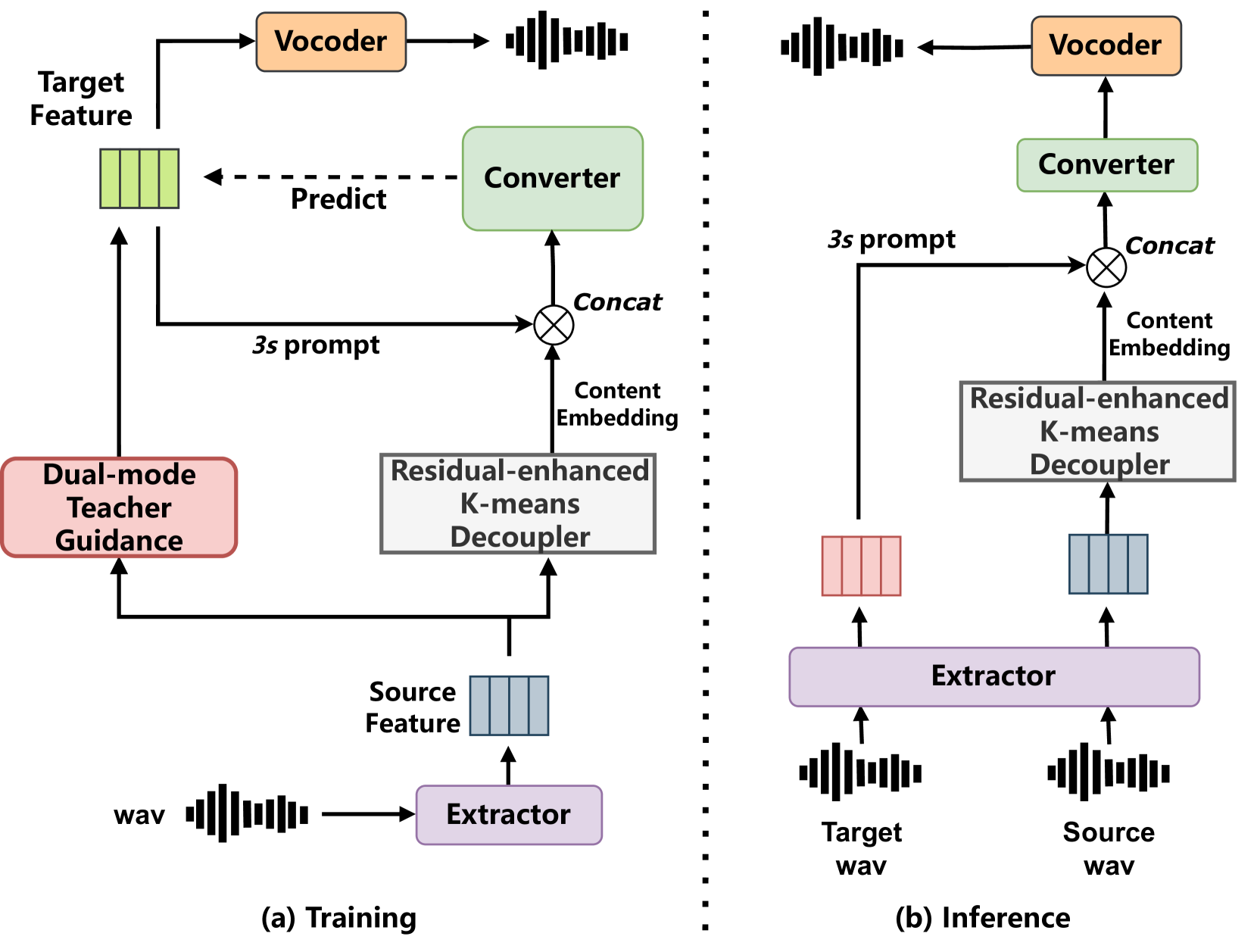
0
Vec-Tok-VC+: Residual-enhanced Robust Zero-shot Voice Conversion with Progressive Constraints in a Dual-mode Training Strategy
Linhan Ma, Xinfa Zhu, Yuanjun Lv, Zhichao Wang, Ziqian Wang, Wendi He, Hongbin Zhou, Lei Xie
Zero-shot voice conversion (VC) aims to transform source speech into arbitrary unseen target voice while keeping the linguistic content unchanged. Recent VC methods have made significant progress, but semantic losses in the decoupling process as well as training-inference mismatch still hinder conversion performance. In this paper, we propose Vec-Tok-VC+, a novel prompt-based zero-shot VC model improved from Vec-Tok Codec, achieving voice conversion given only a 3s target speaker prompt. We design a residual-enhanced K-Means decoupler to enhance the semantic content extraction with a two-layer clustering process. Besides, we employ teacher-guided refinement to simulate the conversion process to eliminate the training-inference mismatch, forming a dual-mode training strategy. Furthermore, we design a multi-codebook progressive loss function to constrain the layer-wise output of the model from coarse to fine to improve speaker similarity and content accuracy. Objective and subjective evaluations demonstrate that Vec-Tok-VC+ outperforms the strong baselines in naturalness, intelligibility, and speaker similarity.
Read more6/17/2024