Noisy Label Processing for Classification: A Survey
2404.04159
0
0

Abstract
In recent years, deep neural networks (DNNs) have gained remarkable achievement in computer vision tasks, and the success of DNNs often depends greatly on the richness of data. However, the acquisition process of data and high-quality ground truth requires a lot of manpower and money. In the long, tedious process of data annotation, annotators are prone to make mistakes, resulting in incorrect labels of images, i.e., noisy labels. The emergence of noisy labels is inevitable. Moreover, since research shows that DNNs can easily fit noisy labels, the existence of noisy labels will cause significant damage to the model training process. Therefore, it is crucial to combat noisy labels for computer vision tasks, especially for classification tasks. In this survey, we first comprehensively review the evolution of different deep learning approaches for noisy label combating in the image classification task. In addition, we also review different noise patterns that have been proposed to design robust algorithms. Furthermore, we explore the inner pattern of real-world label noise and propose an algorithm to generate a synthetic label noise pattern guided by real-world data. We test the algorithm on the well-known real-world dataset CIFAR-10N to form a new real-world data-guided synthetic benchmark and evaluate some typical noise-robust methods on the benchmark.
Create account to get full access
Overview
- This paper provides a comprehensive survey of techniques for processing noisy labels in classification tasks.
- Noisy labels are a common challenge in real-world datasets, where the ground truth labels may contain errors or inconsistencies.
- The paper discusses various approaches to address this issue, including robust learning algorithms, label correction methods, and data augmentation techniques.
Plain English Explanation
In many real-world machine learning tasks, such as image recognition or text classification, the training data we have access to may not be perfect. The labels we use to train our models might contain errors or inconsistencies, a problem known as "noisy labels." This can happen for a variety of reasons, such as human annotators making mistakes, or data being collected from noisy or unreliable sources.
This paper provides an overview of different techniques that researchers have developed to deal with noisy labels. Some approaches focus on making the learning algorithms more robust to label noise, so that the model can still perform well even when the training data is imperfect. Other methods try to actively identify and correct the noisy labels, either by using additional information or by making assumptions about the noise distribution.
Another strategy is to augment the training data in ways that make the model more resilient to label noise, for example by introducing synthetic noisy labels during training. The paper discusses the pros and cons of these different approaches and how they can be combined to achieve the best performance on noisy label problems.
Overall, this survey provides a comprehensive overview of the state-of-the-art in noisy label processing, which is a critical challenge in many real-world machine learning applications. By understanding these techniques, researchers and practitioners can develop more robust and reliable classification models, even when working with imperfect training data.
Technical Explanation
The paper begins by defining the problem of label noise and outlining the scope of the survey. Label noise refers to the situation where the ground truth labels in a dataset contain errors or inconsistencies, which can negatively impact the performance of machine learning models trained on that data.
The authors then introduce the different types of label noise, such as symmetric noise (where labels are randomly flipped) and asymmetric noise (where labels are systematically confused with a related class). They also discuss the various factors that can contribute to label noise, including human annotation errors, data collection errors, and inherent ambiguity in the classification task.
The core of the paper focuses on reviewing the various techniques that have been proposed to address the challenge of noisy labels. These approaches can be broadly categorized into three main strategies:
-
Robust Learning Algorithms: These methods aim to make the learning algorithm more resilient to label noise, for example by modifying the loss function or introducing additional regularization terms.
-
Label Correction Methods: These techniques try to identify and correct the noisy labels in the training data, either by using additional information or by making assumptions about the noise distribution.
-
Data Augmentation Techniques: These methods introduce synthetic noisy labels during training to make the model more robust to label noise.
The paper also discusses how these different approaches can be combined to achieve even better performance on noisy label problems.
Critical Analysis
The survey provides a comprehensive overview of the state-of-the-art in noisy label processing, covering a wide range of techniques and their relative strengths and weaknesses. However, the authors acknowledge that there are still many open challenges and areas for further research in this field.
One key limitation is that many of the proposed methods rely on strong assumptions about the noise distribution or require additional information (such as a small set of clean labels) that may not always be available in real-world scenarios. The authors suggest that developing more generally applicable and data-efficient noisy label processing techniques is an important direction for future research.
Additionally, the survey focuses primarily on classification tasks, and it would be valuable to explore how these techniques can be extended to other machine learning problems, such as regression or structured prediction. The authors also note that most of the existing work has been evaluated on standard benchmark datasets, and more research is needed to understand how these methods perform on diverse, real-world datasets.
Overall, this survey provides a valuable resource for researchers and practitioners working on noisy label problems, but it also highlights the need for continued innovation and rigorous empirical evaluation in this important area of machine learning.
Conclusion
This paper presents a comprehensive survey of techniques for processing noisy labels in classification tasks. The authors discuss a range of approaches, including robust learning algorithms, label correction methods, and data augmentation techniques, and analyze their relative strengths and weaknesses.
The survey highlights the critical importance of addressing label noise, which is a common challenge in real-world machine learning applications. By developing more effective and generalizable noisy label processing methods, researchers and practitioners can build more reliable and robust classification models, even when working with imperfect training data.
The paper identifies several open challenges and directions for future research, such as the need for more data-efficient techniques and the extension of these methods to a broader range of machine learning problems. Overall, this survey provides a valuable resource for the machine learning community and underscores the ongoing importance of addressing the "noisy elephant in the room" of real-world data.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🖼️
Human-annotated label noise and their impact on ConvNets for remote sensing image scene classification
Longkang Peng, Tao Wei, Xuehong Chen, Xiaobei Chen, Rui Sun, Luoma Wan, Jin Chen, Xiaolin Zhu
0
0
Convolutional neural networks (ConvNets) have been successfully applied to satellite image scene classification. Human-labeled training datasets are essential for ConvNets to perform accurate classification. Errors in human-annotated training datasets are unavoidable due to the complexity of satellite images. However, the distribution of real-world human-annotated label noises on remote sensing images and their impact on ConvNets have not been investigated. To fill this research gap, this study, for the first time, collected real-world labels from 32 participants and explored how their annotated label noise affect three representative ConvNets (VGG16, GoogleNet, and ResNet-50) for remote sensing image scene classification. We found that: (1) human-annotated label noise exhibits significant class and instance dependence; (2) an additional 1% of human-annotated label noise in training data leads to 0.5% reduction in the overall accuracy of ConvNets classification; (3) the error pattern of ConvNet predictions was strongly correlated with that of participant's labels. To uncover the mechanism underlying the impact of human labeling errors on ConvNets, we further compared it with three types of simulated label noise: uniform noise, class-dependent noise and instance-dependent noise. Our results show that the impact of human-annotated label noise on ConvNets significantly differs from all three types of simulated label noise, while both class dependence and instance dependence contribute to the impact of human-annotated label noise on ConvNets. These observations necessitate a reevaluation of the handling of noisy labels, and we anticipate that our real-world label noise dataset would facilitate the future development and assessment of label-noise learning algorithms.
5/1/2024
🌀
Noise Correction on Subjective Datasets
Uthman Jinadu, Yi Ding
0
0
Incorporating every annotator's perspective is crucial for unbiased data modeling. Annotator fatigue and changing opinions over time can distort dataset annotations. To combat this, we propose to learn a more accurate representation of diverse opinions by utilizing multitask learning in conjunction with loss-based label correction. We show that using our novel formulation, we can cleanly separate agreeing and disagreeing annotations. Furthermore, this method provides a controllable way to encourage or discourage disagreement. We demonstrate that this modification can improve prediction performance in a single or multi-annotator setting. Lastly, we show that this method remains robust to additional label noise that is applied to subjective data.
6/5/2024
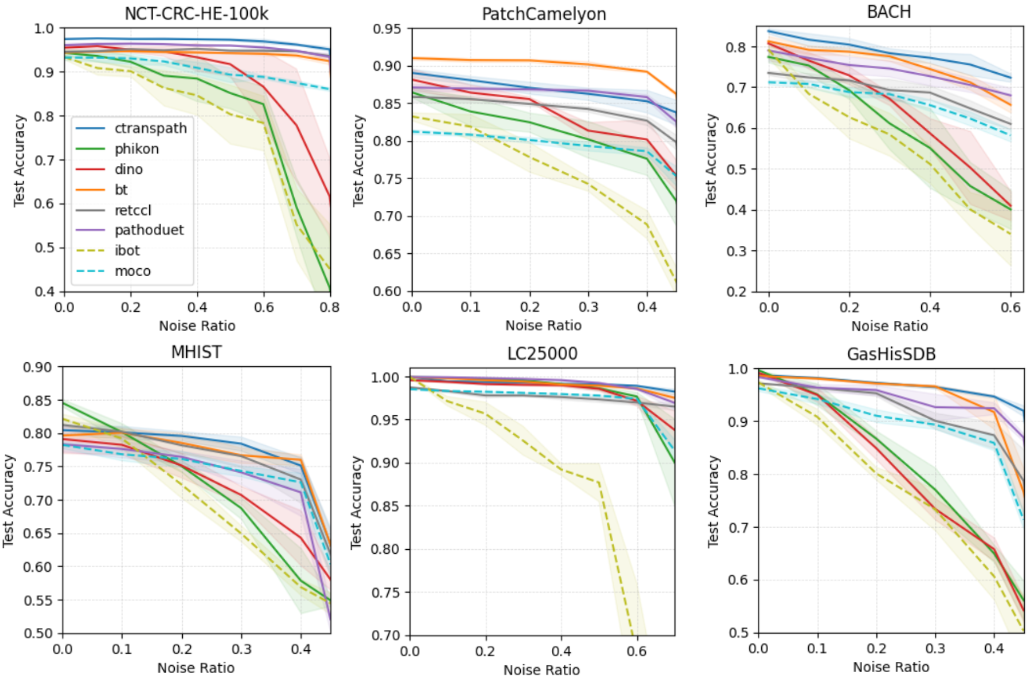
Contrastive-Based Deep Embeddings for Label Noise-Resilient Histopathology Image Classification
Lucas Dedieu, Nicolas Nerrienet, Adrien Nivaggioli, Clara Simmat, Marceau Clavel, Arnaud Gauthier, St'ephane Sockeel, R'emy Peyret
0
0
Recent advancements in deep learning have proven highly effective in medical image classification, notably within histopathology. However, noisy labels represent a critical challenge in histopathology image classification, where accurate annotations are vital for training robust deep learning models. Indeed, deep neural networks can easily overfit label noise, leading to severe degradations in model performance. While numerous public pathology foundation models have emerged recently, none have evaluated their resilience to label noise. Through thorough empirical analyses across multiple datasets, we exhibit the label noise resilience property of embeddings extracted from foundation models trained in a self-supervised contrastive manner. We demonstrate that training with such embeddings substantially enhances label noise robustness when compared to non-contrastive-based ones as well as commonly used noise-resilient methods. Our results unequivocally underline the superiority of contrastive learning in effectively mitigating the label noise challenge. Code is publicly available at https://github.com/LucasDedieu/NoiseResilientHistopathology.
4/12/2024

Rethinking the impact of noisy labels in graph classification: A utility and privacy perspective
De Li, Xianxian Li, Zeming Gan, Qiyu Li, Bin Qu, Jinyan Wang
0
0
Graph neural networks based on message-passing mechanisms have achieved advanced results in graph classification tasks. However, their generalization performance degrades when noisy labels are present in the training data. Most existing noisy labeling approaches focus on the visual domain or graph node classification tasks and analyze the impact of noisy labels only from a utility perspective. Unlike existing work, in this paper, we measure the effects of noise labels on graph classification from data privacy and model utility perspectives. We find that noise labels degrade the model's generalization performance and enhance the ability of membership inference attacks on graph data privacy. To this end, we propose the robust graph neural network approach with noisy labeled graph classification. Specifically, we first accurately filter the noisy samples by high-confidence samples and the first feature principal component vector of each class. Then, the robust principal component vectors and the model output under data augmentation are utilized to achieve noise label correction guided by dual spatial information. Finally, supervised graph contrastive learning is introduced to enhance the embedding quality of the model and protect the privacy of the training graph data. The utility and privacy of the proposed method are validated by comparing twelve different methods on eight real graph classification datasets. Compared with the state-of-the-art methods, the RGLC method achieves at most and at least 7.8% and 0.8% performance gain at 30% noisy labeling rate, respectively, and reduces the accuracy of privacy attacks to below 60%.
6/12/2024