Rethinking the impact of noisy labels in graph classification: A utility and privacy perspective
2406.07314
0
0

Abstract
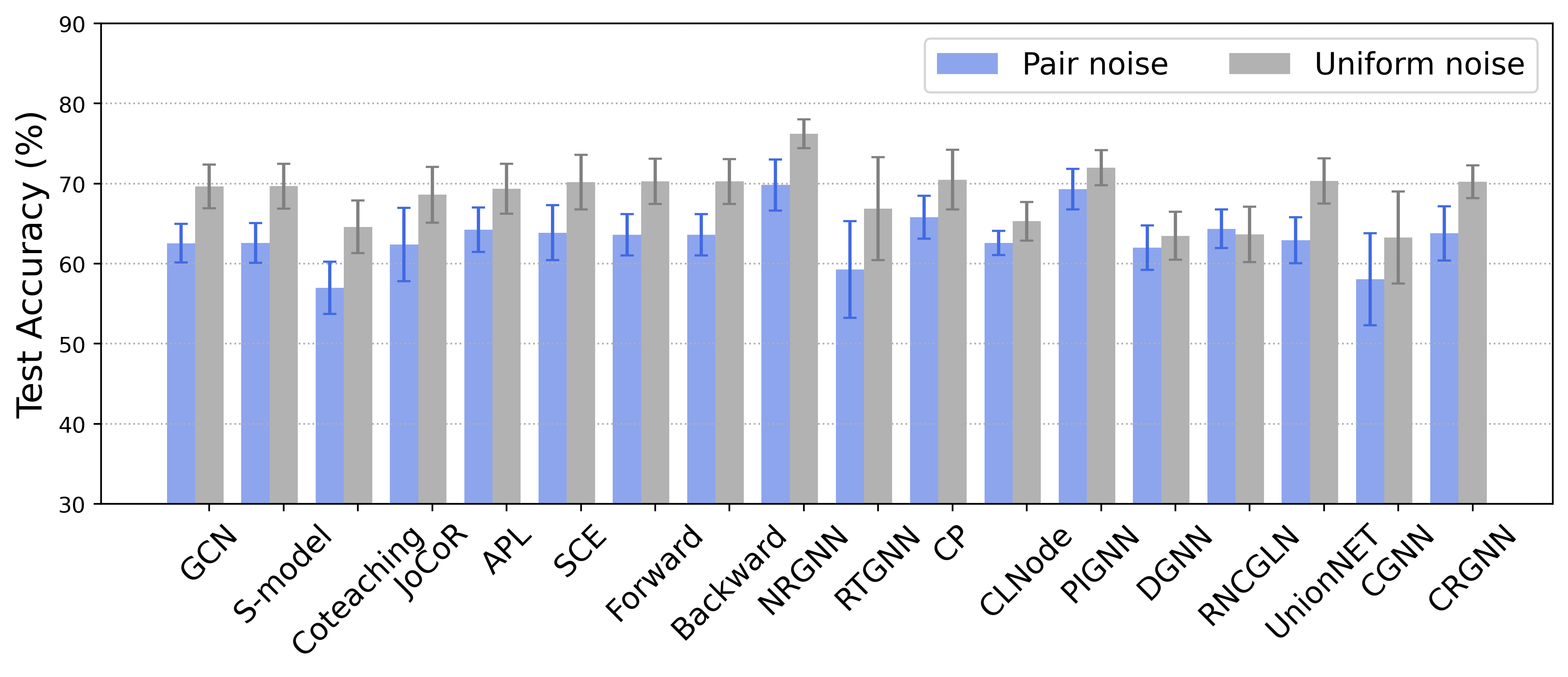
Graph neural networks based on message-passing mechanisms have achieved advanced results in graph classification tasks. However, their generalization performance degrades when noisy labels are present in the training data. Most existing noisy labeling approaches focus on the visual domain or graph node classification tasks and analyze the impact of noisy labels only from a utility perspective. Unlike existing work, in this paper, we measure the effects of noise labels on graph classification from data privacy and model utility perspectives. We find that noise labels degrade the model's generalization performance and enhance the ability of membership inference attacks on graph data privacy. To this end, we propose the robust graph neural network approach with noisy labeled graph classification. Specifically, we first accurately filter the noisy samples by high-confidence samples and the first feature principal component vector of each class. Then, the robust principal component vectors and the model output under data augmentation are utilized to achieve noise label correction guided by dual spatial information. Finally, supervised graph contrastive learning is introduced to enhance the embedding quality of the model and protect the privacy of the training graph data. The utility and privacy of the proposed method are validated by comparing twelve different methods on eight real graph classification datasets. Compared with the state-of-the-art methods, the RGLC method achieves at most and at least 7.8% and 0.8% performance gain at 30% noisy labeling rate, respectively, and reduces the accuracy of privacy attacks to below 60%.
Create account to get full access
Overview
- This paper examines the impact of noisy labels (incorrect or imperfect labels) on the performance of graph classification models.
- It explores the trade-offs between utility (model accuracy) and privacy (protecting sensitive information) in the presence of noisy labels.
- The authors propose a novel framework that can effectively handle noisy labels while preserving privacy.
Plain English Explanation
In machine learning, the performance of a model often depends on the quality of the training data. When the labels (the information used to train the model) contain errors or noise, it can negatively impact the model's accuracy. This is especially true for graph classification tasks, where the model needs to classify the properties of interconnected data points (like social networks or molecular structures).
The researchers of this paper wanted to understand how the presence of noisy labels affects the utility (usefulness) and privacy (protecting sensitive information) of graph classification models. They developed a new framework that can handle noisy labels while still preserving the privacy of the underlying data.
The key idea is to find a way to train the model effectively, even when the labels are not perfect, without compromising the privacy of the individuals or entities represented in the graph data. This is important because graph data often contains sensitive information about people or organizations, and protecting that information is crucial.
The researchers tested their framework on several real-world graph datasets and found that it could maintain high model accuracy while also protecting the privacy of the data. This is a significant advancement, as it allows for more reliable machine learning models to be built using noisy or imperfect data, without sacrificing the privacy of the individuals or entities involved.
Technical Explanation
The paper introduces a novel framework called NPGL (Noise-tolerant and Privacy-preserving Graph Learning) that can effectively handle noisy labels in graph classification tasks while preserving the privacy of the underlying data.
The key components of the NPGL framework are:
-
Noise-tolerant learning: The framework uses a graphical model to capture the relationship between the true labels, noisy labels, and graph structure. This allows the model to learn effectively even in the presence of noisy labels.
-
Privacy-preserving mechanisms: The framework employs differential privacy techniques to protect the sensitive information in the graph data, ensuring that individual privacy is maintained.
The authors conducted extensive experiments on several real-world graph datasets, including NoisyGL and Trusted Multi-View, to evaluate the performance of their NPGL framework. They compared it to other state-of-the-art methods for handling noisy labels and preserving privacy in graph classification tasks.
The results demonstrate that the NPGL framework can maintain high model accuracy while also providing strong privacy guarantees, outperforming existing approaches in both utility and privacy metrics.
Critical Analysis
The paper makes a compelling case for the importance of handling noisy labels in graph classification tasks while preserving privacy. The proposed NPGL framework represents a significant advancement in this area, as it addresses a critical challenge that has not been fully resolved by previous work.
However, the paper also acknowledges several limitations and areas for further research:
-
Scalability: The authors note that the computationally intensive nature of the graphical model used in NPGL may limit its scalability to large-scale graph datasets. Exploring more efficient or approximate inference techniques could help address this issue.
-
Generalization: The performance of the NPGL framework was evaluated on a limited set of graph datasets. Further research is needed to assess its generalization capabilities and robustness across a wider range of real-world graph classification problems.
-
Theoretical analysis: The paper lacks a comprehensive theoretical analysis of the properties and guarantees provided by the NPGL framework. Developing a stronger theoretical foundation could help to better understand the underlying mechanisms and provide more insights into the trade-offs between utility and privacy.
-
Practical considerations: While the paper demonstrates the effectiveness of NPGL in a research setting, more work is needed to address the practical challenges of deploying such a framework in real-world applications, such as handling dynamic or evolving graph data.
Overall, the paper presents a valuable contribution to the field of graph classification, highlighting the importance of addressing noisy labels and privacy concerns simultaneously. The NPGL framework offers a promising approach, and further research and development in this area could lead to significant advancements in the practical application of machine learning on sensitive graph data.
Conclusion
This paper introduces a novel framework called NPGL that can effectively handle noisy labels in graph classification tasks while preserving the privacy of the underlying data. The framework uses a graphical model to capture the relationship between true labels, noisy labels, and graph structure, allowing for noise-tolerant learning. It also employs differential privacy techniques to protect sensitive information in the graph data.
The key contribution of this work is the ability to maintain high model accuracy (utility) while also providing strong privacy guarantees, which is a critical challenge in many real-world graph classification problems. The researchers' extensive experiments on several benchmark datasets demonstrate the effectiveness of the NPGL framework in balancing the trade-offs between utility and privacy.
While the paper highlights several limitations and areas for future research, such as improving scalability and exploring more robust theoretical guarantees, the NPGL framework represents a significant advancement in the field of graph classification. This work could have important implications for a wide range of applications, from social network analysis to molecular structure identification, where reliable and privacy-preserving machine learning models are of paramount importance.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
NoisyGL: A Comprehensive Benchmark for Graph Neural Networks under Label Noise
Zhonghao Wang, Danyu Sun, Sheng Zhou, Haobo Wang, Jiapei Fan, Longtao Huang, Jiajun Bu
0
0
Graph Neural Networks (GNNs) exhibit strong potential in node classification task through a message-passing mechanism. However, their performance often hinges on high-quality node labels, which are challenging to obtain in real-world scenarios due to unreliable sources or adversarial attacks. Consequently, label noise is common in real-world graph data, negatively impacting GNNs by propagating incorrect information during training. To address this issue, the study of Graph Neural Networks under Label Noise (GLN) has recently gained traction. However, due to variations in dataset selection, data splitting, and preprocessing techniques, the community currently lacks a comprehensive benchmark, which impedes deeper understanding and further development of GLN. To fill this gap, we introduce NoisyGL in this paper, the first comprehensive benchmark for graph neural networks under label noise. NoisyGL enables fair comparisons and detailed analyses of GLN methods on noisy labeled graph data across various datasets, with unified experimental settings and interface. Our benchmark has uncovered several important insights that were missed in previous research, and we believe these findings will be highly beneficial for future studies. We hope our open-source benchmark library will foster further advancements in this field. The code of the benchmark can be found in https://github.com/eaglelab-zju/NoisyGL.
6/10/2024

Noisy Label Processing for Classification: A Survey
Mengting Li, Chuang Zhu
0
0
In recent years, deep neural networks (DNNs) have gained remarkable achievement in computer vision tasks, and the success of DNNs often depends greatly on the richness of data. However, the acquisition process of data and high-quality ground truth requires a lot of manpower and money. In the long, tedious process of data annotation, annotators are prone to make mistakes, resulting in incorrect labels of images, i.e., noisy labels. The emergence of noisy labels is inevitable. Moreover, since research shows that DNNs can easily fit noisy labels, the existence of noisy labels will cause significant damage to the model training process. Therefore, it is crucial to combat noisy labels for computer vision tasks, especially for classification tasks. In this survey, we first comprehensively review the evolution of different deep learning approaches for noisy label combating in the image classification task. In addition, we also review different noise patterns that have been proposed to design robust algorithms. Furthermore, we explore the inner pattern of real-world label noise and propose an algorithm to generate a synthetic label noise pattern guided by real-world data. We test the algorithm on the well-known real-world dataset CIFAR-10N to form a new real-world data-guided synthetic benchmark and evaluate some typical noise-robust methods on the benchmark.
4/8/2024
Resurrecting Label Propagation for Graphs with Heterophily and Label Noise
Yao Cheng, Caihua Shan, Yifei Shen, Xiang Li, Siqiang Luo, Dongsheng Li
0
0
Label noise is a common challenge in large datasets, as it can significantly degrade the generalization ability of deep neural networks. Most existing studies focus on noisy labels in computer vision; however, graph models encompass both node features and graph topology as input, and become more susceptible to label noise through message-passing mechanisms. Recently, only a few works have been proposed to tackle the label noise on graphs. One significant limitation is that they operate under the assumption that the graph exhibits homophily and that the labels are distributed smoothly. However, real-world graphs can exhibit varying degrees of heterophily, or even be dominated by heterophily, which results in the inadequacy of the current methods. In this paper, we study graph label noise in the context of arbitrary heterophily, with the aim of rectifying noisy labels and assigning labels to previously unlabeled nodes. We begin by conducting two empirical analyses to explore the impact of graph homophily on graph label noise. Following observations, we propose a efficient algorithm, denoted as $R^{2}LP$. Specifically, $R^{2}LP$ is an iterative algorithm with three steps: (1) reconstruct the graph to recover the homophily property, (2) utilize label propagation to rectify the noisy labels, (3) select high-confidence labels to retain for the next iteration. By iterating these steps, we obtain a set of correct labels, ultimately achieving high accuracy in the node classification task. The theoretical analysis is also provided to demonstrate its remarkable denoising effect. Finally, we perform experiments on ten benchmark datasets with different levels of graph heterophily and various types of noise. In these experiments, we compare the performance of $R^{2}LP$ against ten typical baseline methods. Our results illustrate the superior performance of the proposed $R^{2}LP$.
6/13/2024
📈
Instance-dependent Noisy-label Learning with Graphical Model Based Noise-rate Estimation
Arpit Garg, Cuong Nguyen, Rafael Felix, Thanh-Toan Do, Gustavo Carneiro
0
0
Deep learning faces a formidable challenge when handling noisy labels, as models tend to overfit samples affected by label noise. This challenge is further compounded by the presence of instance-dependent noise (IDN), a realistic form of label noise arising from ambiguous sample information. To address IDN, Label Noise Learning (LNL) incorporates a sample selection stage to differentiate clean and noisy-label samples. This stage uses an arbitrary criterion and a pre-defined curriculum that initially selects most samples as noisy and gradually decreases this selection rate during training. Such curriculum is sub-optimal since it does not consider the actual label noise rate in the training set. This paper addresses this issue with a new noise-rate estimation method that is easily integrated with most state-of-the-art (SOTA) LNL methods to produce a more effective curriculum. Synthetic and real-world benchmark results demonstrate that integrating our approach with SOTA LNL methods improves accuracy in most cases.
5/1/2024