Nonconvex Federated Learning on Compact Smooth Submanifolds With Heterogeneous Data

0
Sign in to get full access
Overview
- This paper proposes a federated learning framework for training machine learning models on data distributed across multiple devices or clients, where the data lies on compact smooth submanifolds with heterogeneous characteristics.
- The authors introduce a novel algorithm called Riemannian Federated Stochastic Gradient Descent (RF-SGD) that can effectively optimize nonconvex objective functions on Riemannian manifolds in the federated learning setting.
- The paper provides theoretical guarantees for the convergence of the proposed algorithm and demonstrates its empirical performance on several benchmark tasks.
Plain English Explanation
In federated learning, machine learning models are trained on data that is distributed across many different devices, such as smartphones or computers, without the data ever leaving those devices. This is useful for preserving privacy and reducing the amount of data that needs to be transmitted.
However, the data on these different devices may have different characteristics, making it challenging to train a single model that works well across all the data. This paper proposes a new approach to federated learning that can handle data that lies on smooth curved surfaces (known as Riemannian manifolds) and has heterogeneous (or varying) properties.
The key idea is to use a specialized optimization algorithm called Riemannian Federated Stochastic Gradient Descent (RF-SGD) that can effectively train a machine learning model on this type of data. The authors provide theoretical guarantees showing that this algorithm will converge to a good solution, and they demonstrate its effectiveness on several real-world machine learning tasks.
Technical Explanation
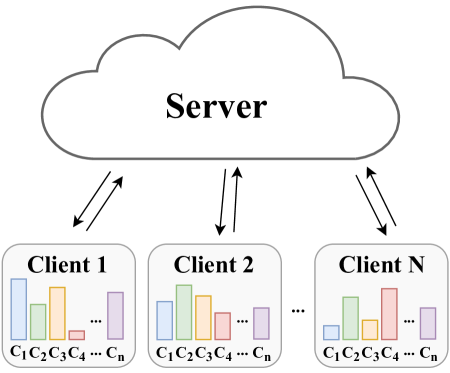
The authors consider a federated learning setting where the data is distributed across multiple clients and lies on compact smooth submanifolds with potentially heterogeneous characteristics. They introduce a novel algorithm called Riemannian Federated Stochastic Gradient Descent (RF-SGD) to optimize nonconvex objective functions on these Riemannian manifolds.
The key steps of the RF-SGD algorithm are:
- Each client computes a Riemannian stochastic gradient descent update on their local data.
- The clients then send their local model updates to a central server.
- The server aggregates the updates using a Riemannian averaging operation and sends the aggregated update back to the clients.
- The clients update their local models using the aggregated update.
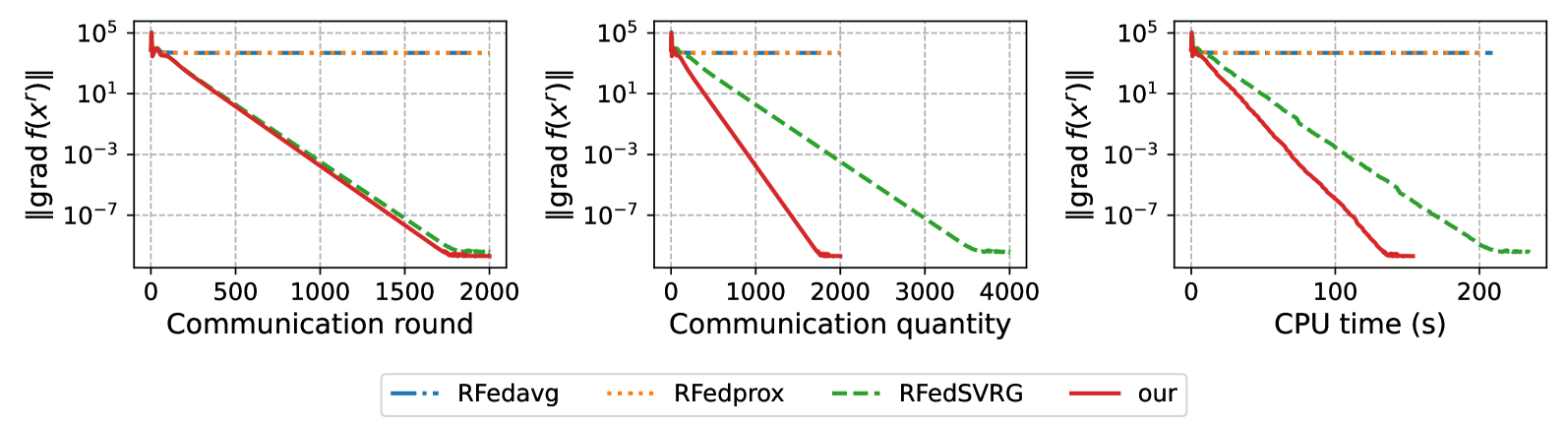
The authors provide convergence guarantees for the RF-SGD algorithm, showing that it can converge to a stationary point of the nonconvex objective function under suitable assumptions. They also demonstrate the empirical performance of RF-SGD on several benchmark tasks, including matrix completion and image classification, and compare it to other federated learning approaches.
Critical Analysis
The authors do a comprehensive job of analyzing the theoretical properties of the proposed RF-SGD algorithm and validating its empirical performance. However, there are a few potential limitations and areas for further research that could be considered:
- The assumption of compact smooth submanifolds may not always hold in practice, and it would be valuable to explore extensions to more general manifold structures.
- The paper does not consider the impact of differential privacy or other privacy-preserving techniques, which are crucial for real-world federated learning applications.
- The experiments are limited to relatively small-scale tasks, and it would be interesting to see how the RF-SGD algorithm scales to larger, more complex machine learning problems.
Overall, this paper makes an important contribution to the field of federated learning on Riemannian manifolds and provides a strong foundation for further research in this area.
Conclusion
This paper presents a novel federated learning framework for training machine learning models on data distributed across multiple devices, where the data lies on compact smooth submanifolds with heterogeneous characteristics. The authors introduce the Riemannian Federated Stochastic Gradient Descent (RF-SGD) algorithm, which can effectively optimize nonconvex objective functions on these Riemannian manifolds.
The theoretical analysis and empirical results demonstrate the effectiveness of the proposed approach, suggesting that it could be a valuable tool for a wide range of real-world federated learning applications. While the paper has some limitations, it opens up new avenues for further research in this important and rapidly evolving field.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Nonconvex Federated Learning on Compact Smooth Submanifolds With Heterogeneous Data
Jiaojiao Zhang, Jiang Hu, Anthony Man-Cho So, Mikael Johansson
Many machine learning tasks, such as principal component analysis and low-rank matrix completion, give rise to manifold optimization problems. Although there is a large body of work studying the design and analysis of algorithms for manifold optimization in the centralized setting, there are currently very few works addressing the federated setting. In this paper, we consider nonconvex federated learning over a compact smooth submanifold in the setting of heterogeneous client data. We propose an algorithm that leverages stochastic Riemannian gradients and a manifold projection operator to improve computational efficiency, uses local updates to improve communication efficiency, and avoids client drift. Theoretically, we show that our proposed algorithm converges sub-linearly to a neighborhood of a first-order optimal solution by using a novel analysis that jointly exploits the manifold structure and properties of the loss functions. Numerical experiments demonstrate that our algorithm has significantly smaller computational and communication overhead than existing methods.
Read more6/13/2024
0
Federated Learning under Partially Class-Disjoint Data via Manifold Reshaping
Ziqing Fan, Jiangchao Yao, Ruipeng Zhang, Lingjuan Lyu, Ya Zhang, Yanfeng Wang
Statistical heterogeneity severely limits the performance of federated learning (FL), motivating several explorations e.g., FedProx, MOON and FedDyn, to alleviate this problem. Despite effectiveness, their considered scenario generally requires samples from almost all classes during the local training of each client, although some covariate shifts may exist among clients. In fact, the natural case of partially class-disjoint data (PCDD), where each client contributes a few classes (instead of all classes) of samples, is practical yet underexplored. Specifically, the unique collapse and invasion characteristics of PCDD can induce the biased optimization direction in local training, which prevents the efficiency of federated learning. To address this dilemma, we propose a manifold reshaping approach called FedMR to calibrate the feature space of local training. Our FedMR adds two interplaying losses to the vanilla federated learning: one is intra-class loss to decorrelate feature dimensions for anti-collapse; and the other one is inter-class loss to guarantee the proper margin among categories in the feature expansion. We conduct extensive experiments on a range of datasets to demonstrate that our FedMR achieves much higher accuracy and better communication efficiency. Source code is available at: https://github.com/MediaBrain-SJTU/FedMR.git.
Read more6/4/2024
🔮
0
Locally Adaptive Federated Learning
Sohom Mukherjee, Nicolas Loizou, Sebastian U. Stich
Federated learning is a paradigm of distributed machine learning in which multiple clients coordinate with a central server to learn a model, without sharing their own training data. Standard federated optimization methods such as Federated Averaging (FedAvg) ensure balance among the clients by using the same stepsize for local updates on all clients. However, this means that all clients need to respect the global geometry of the function which could yield slow convergence. In this work, we propose locally adaptive federated learning algorithms, that leverage the local geometric information for each client function. We show that such locally adaptive methods with uncoordinated stepsizes across all clients can be particularly efficient in interpolated (overparameterized) settings, and analyze their convergence in the presence of heterogeneous data for convex and strongly convex settings. We validate our theoretical claims by performing illustrative experiments for both i.i.d. non-i.i.d. cases. Our proposed algorithms match the optimization performance of tuned FedAvg in the convex setting, outperform FedAvg as well as state-of-the-art adaptive federated algorithms like FedAMS for non-convex experiments, and come with superior generalization performance.
Read more5/15/2024
📈
0
Privacy-preserving Federated Primal-dual Learning for Non-convex and Non-smooth Problems with Model Sparsification
Yiwei Li, Chien-Wei Huang, Shuai Wang, Chong-Yung Chi, Tony Q. S. Quek
Federated learning (FL) has been recognized as a rapidly growing research area, where the model is trained over massively distributed clients under the orchestration of a parameter server (PS) without sharing clients' data. This paper delves into a class of federated problems characterized by non-convex and non-smooth loss functions, that are prevalent in FL applications but challenging to handle due to their intricate non-convexity and non-smoothness nature and the conflicting requirements on communication efficiency and privacy protection. In this paper, we propose a novel federated primal-dual algorithm with bidirectional model sparsification tailored for non-convex and non-smooth FL problems, and differential privacy is applied for privacy guarantee. Its unique insightful properties and some privacy and convergence analyses are also presented as the FL algorithm design guidelines. Extensive experiments on real-world data are conducted to demonstrate the effectiveness of the proposed algorithm and much superior performance than some state-of-the-art FL algorithms, together with the validation of all the analytical results and properties.
Read more4/4/2024