Federated Learning under Partially Class-Disjoint Data via Manifold Reshaping
2405.18983
0
0
Abstract
Statistical heterogeneity severely limits the performance of federated learning (FL), motivating several explorations e.g., FedProx, MOON and FedDyn, to alleviate this problem. Despite effectiveness, their considered scenario generally requires samples from almost all classes during the local training of each client, although some covariate shifts may exist among clients. In fact, the natural case of partially class-disjoint data (PCDD), where each client contributes a few classes (instead of all classes) of samples, is practical yet underexplored. Specifically, the unique collapse and invasion characteristics of PCDD can induce the biased optimization direction in local training, which prevents the efficiency of federated learning. To address this dilemma, we propose a manifold reshaping approach called FedMR to calibrate the feature space of local training. Our FedMR adds two interplaying losses to the vanilla federated learning: one is intra-class loss to decorrelate feature dimensions for anti-collapse; and the other one is inter-class loss to guarantee the proper margin among categories in the feature expansion. We conduct extensive experiments on a range of datasets to demonstrate that our FedMR achieves much higher accuracy and better communication efficiency. Source code is available at: https://github.com/MediaBrain-SJTU/FedMR.git.
Create account to get full access
Overview
- This paper proposes a new approach called "Federated Learning under Partially Class-Disjoint Data via Manifold Reshaping" to address the challenge of federated learning (FL) with partially class-disjoint data, where different clients have access to different subsets of classes.
- The key idea is to reshape the data manifolds of the clients to align them during the FL process, enabling knowledge sharing across clients and improving the overall model performance.
- The authors demonstrate the effectiveness of their approach through extensive experiments on various datasets and compare it to state-of-the-art FL methods.
Plain English Explanation
In federated learning, multiple devices or clients (e.g., smartphones, laptops) collaborate to train a shared machine learning model without directly sharing their data. This is useful when data is sensitive or distributed across many locations.
However, a common challenge in federated learning is that the data available on different clients may be "partially class-disjoint", meaning that each client has access to a different subset of the classes (e.g., one client has images of dogs and cats, while another has images of birds and horses). This can make it difficult for the clients to share knowledge and learn a high-performing model.
The authors of this paper propose a new approach to address this challenge. The key idea is to "reshape" the data manifolds (the underlying geometric structure of the data) of the different clients during the federated learning process. By aligning these data manifolds, the clients can more effectively share knowledge, leading to improved model performance.
The authors demonstrate the effectiveness of their approach through experiments on various datasets and show that it outperforms other state-of-the-art federated learning methods in scenarios with partially class-disjoint data.
Technical Explanation
The paper introduces a novel federated learning framework called "Federated Learning under Partially Class-Disjoint Data via Manifold Reshaping" (FLPCD-MaRS) to address the challenge of partially class-disjoint data in federated learning.
In a typical federated learning setup, multiple clients (e.g., edge devices) collaborate to train a shared model without directly sharing their local data. However, when the data is partially class-disjoint, meaning that each client has access to a different subset of the classes, it becomes challenging for the clients to effectively share knowledge and learn a high-performing model.
To address this issue, the authors propose to reshape the data manifolds (the underlying geometric structure of the data) of the different clients during the federated learning process. By aligning these data manifolds, the clients can more effectively share knowledge, leading to improved model performance.
The key technical contributions of the paper are:
-
Manifold Reshaping Module: The authors introduce a manifold reshaping module that can be integrated into the federated learning pipeline. This module learns a transformation that aligns the data manifolds of the different clients, enabling more effective knowledge sharing.
-
Optimization Procedure: The authors devise a novel optimization procedure that jointly trains the shared model and the manifold reshaping module, ensuring that the reshaped manifolds are well-aligned and improve the overall model performance.
-
Theoretical Analysis: The authors provide a theoretical analysis of their approach, showing that the manifold reshaping can lead to improved generalization bounds for the federated learning model.
The authors evaluate their FLPCD-MaRS approach on various datasets and compare it to state-of-the-art federated learning methods, including Riemannian Federated Learning, Dimensional Collapse Mitigation, and Hybrid Federated Learning. The results demonstrate the effectiveness of their approach in scenarios with partially class-disjoint data, outperforming the compared methods.
Critical Analysis
The paper presents a well-designed and technically sound approach to address the challenge of partially class-disjoint data in federated learning. The authors' focus on reshaping the data manifolds to enable more effective knowledge sharing is a novel and promising direction.
One potential limitation of the approach is that it may require additional computational resources and training time due to the need to learn the manifold reshaping module along with the shared model. This could be a concern, especially in resource-constrained edge devices.
Additionally, the authors' theoretical analysis provides useful insights, but it would be valuable to see more in-depth experimental validation of the theoretical claims, such as the impact of the manifold reshaping on the generalization performance.
It would also be interesting to see how the FLPCD-MaRS approach would perform in scenarios with more extreme class-disjointness, where the overlap between the classes available to different clients is very small. The authors have demonstrated the effectiveness in partially class-disjoint settings, but the behavior in more challenging cases could be an area for further exploration.
Overall, the paper presents a compelling and technically sound approach that addresses an important challenge in federated learning. The authors' focus on data manifold reshaping is a promising direction that could inspire further research and development in this area.
Conclusion
This paper introduces a novel federated learning framework called "Federated Learning under Partially Class-Disjoint Data via Manifold Reshaping" (FLPCD-MaRS) to address the challenge of partially class-disjoint data in federated learning. The key idea is to reshape the data manifolds of the different clients during the learning process, enabling more effective knowledge sharing and improved model performance.
The authors demonstrate the effectiveness of their approach through extensive experiments and theoretical analysis, showing that FLPCD-MaRS outperforms state-of-the-art federated learning methods in scenarios with partially class-disjoint data. This work represents an important step forward in addressing a significant challenge in federated learning and could pave the way for further advancements in this field.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
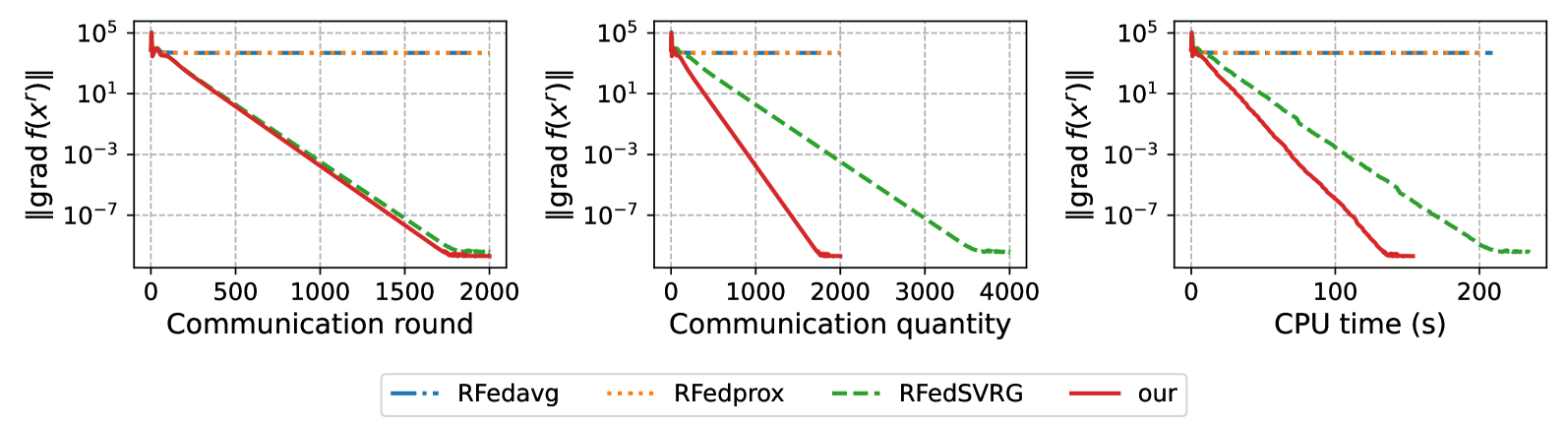
Nonconvex Federated Learning on Compact Smooth Submanifolds With Heterogeneous Data
Jiaojiao Zhang, Jiang Hu, Anthony Man-Cho So, Mikael Johansson
0
0
Many machine learning tasks, such as principal component analysis and low-rank matrix completion, give rise to manifold optimization problems. Although there is a large body of work studying the design and analysis of algorithms for manifold optimization in the centralized setting, there are currently very few works addressing the federated setting. In this paper, we consider nonconvex federated learning over a compact smooth submanifold in the setting of heterogeneous client data. We propose an algorithm that leverages stochastic Riemannian gradients and a manifold projection operator to improve computational efficiency, uses local updates to improve communication efficiency, and avoids client drift. Theoretically, we show that our proposed algorithm converges sub-linearly to a neighborhood of a first-order optimal solution by using a novel analysis that jointly exploits the manifold structure and properties of the loss functions. Numerical experiments demonstrate that our algorithm has significantly smaller computational and communication overhead than existing methods.
6/13/2024

Federated Learning with Bilateral Curation for Partially Class-Disjoint Data
Ziqing Fan, Ruipeng Zhang, Jiangchao Yao, Bo Han, Ya Zhang, Yanfeng Wang
0
0
Partially class-disjoint data (PCDD), a common yet under-explored data formation where each client contributes a part of classes (instead of all classes) of samples, severely challenges the performance of federated algorithms. Without full classes, the local objective will contradict the global objective, yielding the angle collapse problem for locally missing classes and the space waste problem for locally existing classes. As far as we know, none of the existing methods can intrinsically mitigate PCDD challenges to achieve holistic improvement in the bilateral views (both global view and local view) of federated learning. To address this dilemma, we are inspired by the strong generalization of simplex Equiangular Tight Frame~(ETF) on the imbalanced data, and propose a novel approach called FedGELA where the classifier is globally fixed as a simplex ETF while locally adapted to the personal distributions. Globally, FedGELA provides fair and equal discrimination for all classes and avoids inaccurate updates of the classifier, while locally it utilizes the space of locally missing classes for locally existing classes. We conduct extensive experiments on a range of datasets to demonstrate that our FedGELA achieves promising performance~(averaged improvement of 3.9% to FedAvg and 1.5% to best baselines) and provide both local and global convergence guarantees. Source code is available at:https://github.com/MediaBrain-SJTU/FedGELA.git.
5/30/2024
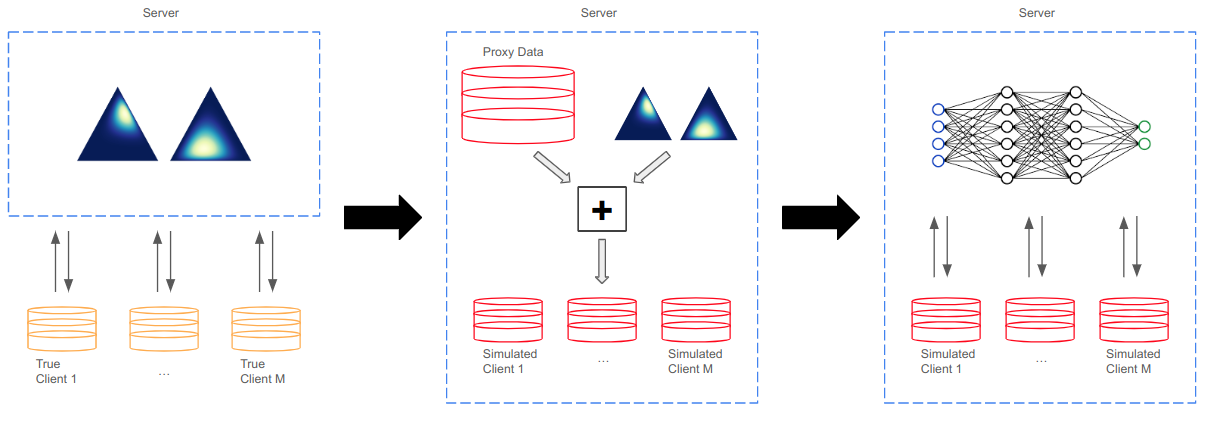
Improved Modelling of Federated Datasets using Mixtures-of-Dirichlet-Multinomials
Jonathan Scott, 'Aine Cahill
0
0
In practice, training using federated learning can be orders of magnitude slower than standard centralized training. This severely limits the amount of experimentation and tuning that can be done, making it challenging to obtain good performance on a given task. Server-side proxy data can be used to run training simulations, for instance for hyperparameter tuning. This can greatly speed up the training pipeline by reducing the number of tuning runs to be performed overall on the true clients. However, it is challenging to ensure that these simulations accurately reflect the dynamics of the real federated training. In particular, the proxy data used for simulations often comes as a single centralized dataset without a partition into distinct clients, and partitioning this data in a naive way can lead to simulations that poorly reflect real federated training. In this paper we address the challenge of how to partition centralized data in a way that reflects the statistical heterogeneity of the true federated clients. We propose a fully federated, theoretically justified, algorithm that efficiently learns the distribution of the true clients and observe improved server-side simulations when using the inferred distribution to create simulated clients from the centralized data.
6/5/2024

Federated Model Heterogeneous Matryoshka Representation Learning
Liping Yi, Han Yu, Chao Ren, Gang Wang, Xiaoguang Liu, Xiaoxiao Li
0
0
Model heterogeneous federated learning (MHeteroFL) enables FL clients to collaboratively train models with heterogeneous structures in a distributed fashion. However, existing MHeteroFL methods rely on training loss to transfer knowledge between the client model and the server model, resulting in limited knowledge exchange. To address this limitation, we propose the Federated model heterogeneous Matryoshka Representation Learning (FedMRL) approach for supervised learning tasks. It adds an auxiliary small homogeneous model shared by clients with heterogeneous local models. (1) The generalized and personalized representations extracted by the two models' feature extractors are fused by a personalized lightweight representation projector. This step enables representation fusion to adapt to local data distribution. (2) The fused representation is then used to construct Matryoshka representations with multi-dimensional and multi-granular embedded representations learned by the global homogeneous model header and the local heterogeneous model header. This step facilitates multi-perspective representation learning and improves model learning capability. Theoretical analysis shows that FedMRL achieves a $O(1/T)$ non-convex convergence rate. Extensive experiments on benchmark datasets demonstrate its superior model accuracy with low communication and computational costs compared to seven state-of-the-art baselines. It achieves up to 8.48% and 24.94% accuracy improvement compared with the state-of-the-art and the best same-category baseline, respectively.
6/4/2024