Not Just Pretty Pictures: Toward Interventional Data Augmentation Using Text-to-Image Generators
2212.11237
0
0
📊
Abstract
Neural image classifiers are known to undergo severe performance degradation when exposed to inputs that are sampled from environmental conditions that differ from their training data. Given the recent progress in Text-to-Image (T2I) generation, a natural question is how modern T2I generators can be used to simulate arbitrary interventions over such environmental factors in order to augment training data and improve the robustness of downstream classifiers. We experiment across a diverse collection of benchmarks in single domain generalization (SDG) and reducing reliance on spurious features (RRSF), ablating across key dimensions of T2I generation, including interventional prompting strategies, conditioning mechanisms, and post-hoc filtering. Our extensive empirical findings demonstrate that modern T2I generators like Stable Diffusion can indeed be used as a powerful interventional data augmentation mechanism, outperforming previously state-of-the-art data augmentation techniques regardless of how each dimension is configured.
Create account to get full access
Overview
- Neural image classifiers can perform poorly when exposed to inputs that differ from their training data.
- Recent progress in Text-to-Image (T2I) generation raises the question of how T2I generators can be used to simulate environmental interventions and improve the robustness of downstream classifiers.
- The researchers experiment with using T2I generation to augment training data and evaluate performance on single domain generalization (SDG) and reducing reliance on spurious features (RRSF) benchmarks.
Plain English Explanation
Neural image classifiers are machine learning models that can identify and categorize objects, scenes, or other visual elements in images. However, these classifiers often struggle when faced with images that are different from the ones they were trained on. For example, a classifier trained on sunny, clear-day images may perform poorly on images taken in rainy or overcast conditions.
To address this issue, the researchers in this study explored using Text-to-Image (T2I) generation models as a tool for creating synthetic training data. T2I models can generate images from textual descriptions, and the researchers hypothesized that these models could be used to simulate different environmental conditions, like changes in lighting, weather, or camera angles.
By augmenting the original training data with these synthetically generated images, the researchers aimed to improve the robustness and generalization of the downstream image classifiers. They tested this approach on two different benchmarks: single domain generalization (SDG), which measures how well a model performs on data from a different domain, and reducing reliance on spurious features (RRSF), which tests whether a model is basing its predictions on meaningful features rather than superficial ones.
The researchers experimented with various aspects of the T2I generation process, such as the prompting strategies, conditioning mechanisms, and post-hoc filtering techniques. Their extensive empirical findings showed that modern T2I generators, like Stable Diffusion, can indeed be used effectively as a data augmentation tool, outperforming previously state-of-the-art techniques regardless of how the T2I generation process is configured.
Technical Explanation
The researchers conducted extensive experiments to assess the effectiveness of using Text-to-Image (T2I) generation as a data augmentation technique for improving the robustness of downstream image classifiers.
They evaluated their approach on two benchmark tasks: single domain generalization (SDG) and reducing reliance on spurious features (RRSF). In the SDG task, the goal is to train a model that can perform well on data from a different domain than the one it was trained on. The RRSF task, on the other hand, tests whether a model is basing its predictions on meaningful features rather than superficial ones.
The researchers experimented with various aspects of the T2I generation process, including:
- Interventional prompting strategies: Prompts that explicitly specify environmental conditions or interventions to simulate.
- Conditioning mechanisms: How the T2I model is conditioned on the input data (e.g., class labels, images, or both).
- Post-hoc filtering: Techniques for selecting the most relevant or high-quality generated images for data augmentation.
The researchers' extensive empirical findings demonstrate that modern T2I generators, like Stable Diffusion, can be effectively used as a powerful data augmentation mechanism, outperforming previously state-of-the-art techniques regardless of how the T2I generation process is configured.
Critical Analysis
The researchers acknowledge several caveats and limitations in their study. They note that the effectiveness of the T2I-based data augmentation approach may depend on the specific task, dataset, and downstream model being used. Additionally, the researchers mention that the quality and realism of the generated images can vary, which could impact the effectiveness of the data augmentation.
While the researchers demonstrate the potential of using T2I generation for data augmentation, there are still open questions and areas for further research. For example, it would be interesting to explore the performance of this approach on more complex or diverse datasets, or to investigate the impact of different T2I model architectures and training techniques.
Furthermore, the researchers do not fully address the potential biases or artifacts that may be introduced by the T2I generation process and how those might affect the downstream classifier's performance. Careful analysis of the generated images and their impact on the classifier's decision-making process would be a valuable area for future research.
Conclusion
This study presents a compelling exploration of using Text-to-Image (T2I) generation as a data augmentation technique to improve the robustness of neural image classifiers. The researchers' extensive experiments demonstrate the effectiveness of this approach, showing that it can outperform previous state-of-the-art data augmentation techniques across a range of benchmarks.
The findings have significant implications for the development of more reliable and generalizable image classification models, which are crucial for a wide range of real-world applications. By leveraging the power of T2I generation, researchers and practitioners can now explore new ways to create synthetic training data that better captures the diverse environmental conditions their models may encounter in the field.
As the field of machine learning continues to evolve, this study highlights the importance of exploring innovative data augmentation techniques, such as those enabled by advancements in generative models. The insights gained from this research can inspire further advancements in building more robust and versatile image classification systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
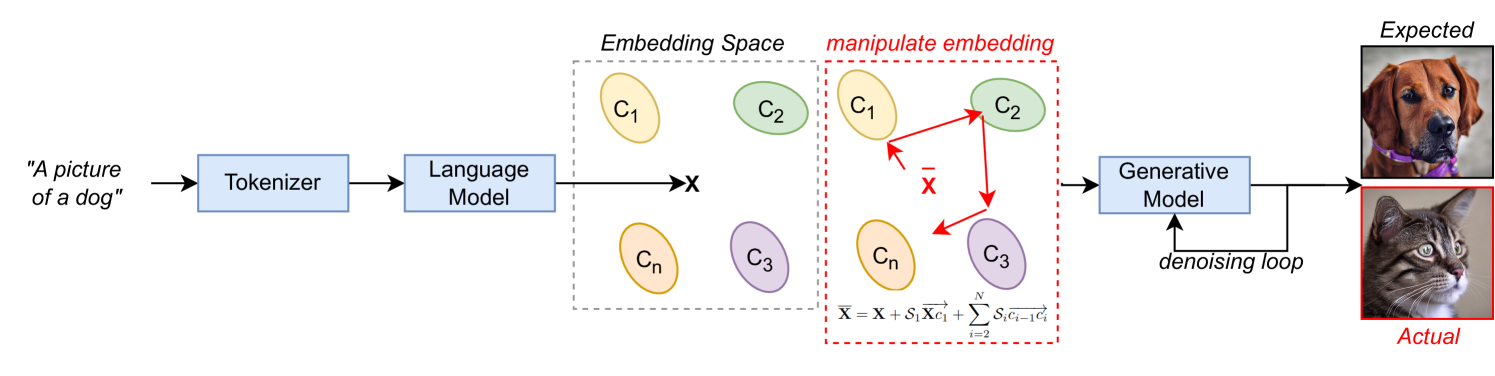
Severity Controlled Text-to-Image Generative Model Bias Manipulation
Jordan Vice, Naveed Akhtar, Richard Hartley, Ajmal Mian
0
0
Text-to-image (T2I) generative models are gaining wide popularity, especially in public domains. However, their intrinsic bias and potential malicious manipulations remain under-explored. Charting the susceptibility of T2I models to such manipulation, we first expose the new possibility of a dynamic and computationally efficient exploitation of model bias by targeting the embedded language models. By leveraging mathematical foundations of vector algebra, our technique enables a scalable and convenient control over the severity of output manipulation through model bias. As a by-product, this control also allows a form of precise prompt engineering to generate images which are generally implausible with regular text prompts. We also demonstrate a constructive application of our manipulation for balancing the frequency of generated classes - as in model debiasing. Our technique does not require training and is also framed as a backdoor attack with severity control using semantically-null text triggers in the prompts. With extensive analysis, we present interesting qualitative and quantitative results to expose potential manipulation possibilities for T2I models. Key-words: Text-to-Image Models, Generative Models, Backdoor Attacks, Prompt Engineering, Bias
4/4/2024

A Survey of Multimodal-Guided Image Editing with Text-to-Image Diffusion Models
Xincheng Shuai, Henghui Ding, Xingjun Ma, Rongcheng Tu, Yu-Gang Jiang, Dacheng Tao
0
0
Image editing aims to edit the given synthetic or real image to meet the specific requirements from users. It is widely studied in recent years as a promising and challenging field of Artificial Intelligence Generative Content (AIGC). Recent significant advancement in this field is based on the development of text-to-image (T2I) diffusion models, which generate images according to text prompts. These models demonstrate remarkable generative capabilities and have become widely used tools for image editing. T2I-based image editing methods significantly enhance editing performance and offer a user-friendly interface for modifying content guided by multimodal inputs. In this survey, we provide a comprehensive review of multimodal-guided image editing techniques that leverage T2I diffusion models. First, we define the scope of image editing from a holistic perspective and detail various control signals and editing scenarios. We then propose a unified framework to formalize the editing process, categorizing it into two primary algorithm families. This framework offers a design space for users to achieve specific goals. Subsequently, we present an in-depth analysis of each component within this framework, examining the characteristics and applicable scenarios of different combinations. Given that training-based methods learn to directly map the source image to target one under user guidance, we discuss them separately, and introduce injection schemes of source image in different scenarios. Additionally, we review the application of 2D techniques to video editing, highlighting solutions for inter-frame inconsistency. Finally, we discuss open challenges in the field and suggest potential future research directions. We keep tracing related works at https://github.com/xinchengshuai/Awesome-Image-Editing.
6/21/2024
📊
Robust Disaster Assessment from Aerial Imagery Using Text-to-Image Synthetic Data
Tarun Kalluri, Jihyeon Lee, Kihyuk Sohn, Sahil Singla, Manmohan Chandraker, Joseph Xu, Jeremiah Liu
0
0
We present a simple and efficient method to leverage emerging text-to-image generative models in creating large-scale synthetic supervision for the task of damage assessment from aerial images. While significant recent advances have resulted in improved techniques for damage assessment using aerial or satellite imagery, they still suffer from poor robustness to domains where manual labeled data is unavailable, directly impacting post-disaster humanitarian assistance in such under-resourced geographies. Our contribution towards improving domain robustness in this scenario is two-fold. Firstly, we leverage the text-guided mask-based image editing capabilities of generative models and build an efficient and easily scalable pipeline to generate thousands of post-disaster images from low-resource domains. Secondly, we propose a simple two-stage training approach to train robust models while using manual supervision from different source domains along with the generated synthetic target domain data. We validate the strength of our proposed framework under cross-geography domain transfer setting from xBD and SKAI images in both single-source and multi-source settings, achieving significant improvements over a source-only baseline in each case.
5/24/2024
🤯
Survey of Bias In Text-to-Image Generation: Definition, Evaluation, and Mitigation
Yixin Wan, Arjun Subramonian, Anaelia Ovalle, Zongyu Lin, Ashima Suvarna, Christina Chance, Hritik Bansal, Rebecca Pattichis, Kai-Wei Chang
0
0
The recent advancement of large and powerful models with Text-to-Image (T2I) generation abilities -- such as OpenAI's DALLE-3 and Google's Gemini -- enables users to generate high-quality images from textual prompts. However, it has become increasingly evident that even simple prompts could cause T2I models to exhibit conspicuous social bias in generated images. Such bias might lead to both allocational and representational harms in society, further marginalizing minority groups. Noting this problem, a large body of recent works has been dedicated to investigating different dimensions of bias in T2I systems. However, an extensive review of these studies is lacking, hindering a systematic understanding of current progress and research gaps. We present the first extensive survey on bias in T2I generative models. In this survey, we review prior studies on dimensions of bias: Gender, Skintone, and Geo-Culture. Specifically, we discuss how these works define, evaluate, and mitigate different aspects of bias. We found that: (1) while gender and skintone biases are widely studied, geo-cultural bias remains under-explored; (2) most works on gender and skintone bias investigated occupational association, while other aspects are less frequently studied; (3) almost all gender bias works overlook non-binary identities in their studies; (4) evaluation datasets and metrics are scattered, with no unified framework for measuring biases; and (5) current mitigation methods fail to resolve biases comprehensively. Based on current limitations, we point out future research directions that contribute to human-centric definitions, evaluations, and mitigation of biases. We hope to highlight the importance of studying biases in T2I systems, as well as encourage future efforts to holistically understand and tackle biases, building fair and trustworthy T2I technologies for everyone.
5/3/2024