A Novel Framework For Text Detection From Natural Scene Images With Complex Background

0
🔎
Sign in to get full access
Overview
- Recognizing text in camera images is a challenging task due to complex and varied backgrounds.
- This paper proposes a novel and efficient method to detect text regions from images with complex backgrounds using Wavelet Transforms.
- The framework involves Wavelet Transformation of the grayscale image, Sub-band filtering, and Region clustering to identify text regions.
- This method is more sophisticated and efficient than previous approaches as it is not limited to a particular font size.
- The experimental dataset includes 50 images with varying backgrounds and edge prominence.
- The method can be easily customized for different applications.
Plain English Explanation
Wavelet Transforms are a powerful tool for analyzing and processing images. In this paper, the researchers use Wavelet Transforms to help detect text in camera images, which can be a challenging task.
The key idea is to first convert the image to grayscale and then apply Wavelet Transformation. This breaks the image down into different frequency bands or "sub-bands." The researchers then use a technique called "Sub-band filtering" to identify areas of the image that are likely to contain text.
Next, they use a "Region clustering" method to group together the text-containing areas and fit a bounding box around each one. This allows them to accurately locate and identify the text regions in the image.
One of the advantages of this approach is that it doesn't rely on a specific font size or style of text. This makes it more versatile and able to handle a wider range of text in different types of images, like those with complex backgrounds or varying edge prominence.
The researchers tested their method on a dataset of 50 images and found it to be effective and efficient. They also note that the method can be easily adapted for different applications that require text detection in images.
Technical Explanation
The paper presents a novel framework for detecting text regions from images with complex backgrounds using Wavelet Transforms. The key steps of the proposed method are:
-
Wavelet Transformation: The original image is converted to grayscale and then undergoes Wavelet Transformation, which decomposes the image into different frequency sub-bands.
-
Sub-band Filtering: The sub-bands are then filtered to identify the regions likely to contain text, based on their frequency characteristics.
-
Region Clustering: A region clustering technique is applied to the filtered sub-bands, using the centroids of the regions. This groups together the text-containing areas.
-
Bounding Box Fitting: Finally, a bounding box is fitted around each clustered region to accurately identify the text areas within the image.
The researchers tested this method on a dataset of 50 images with varying backgrounds and edge prominence. They found that their approach is more sophisticated and efficient than previous text detection methods, as it is not limited to a particular font size or style of text.
The flexibility of this method allows it to be easily customized for different applications that require text detection in images with complex backgrounds, such as document scanning or scene text recognition.
Critical Analysis
The paper presents a well-designed and effective method for text detection in images with complex backgrounds. The use of Wavelet Transforms and the subsequent processing steps are well-explained and seem to be a significant improvement over previous approaches.
One potential limitation of the study is the relatively small dataset of 50 images used for evaluation. While the results are promising, testing the method on a larger and more diverse dataset would help demonstrate its robustness and generalizability.
Additionally, the paper does not provide any comparison to state-of-the-art deep learning-based text detection methods, which have become increasingly prevalent in recent years. Comparing the performance of this Wavelet-based approach to modern deep learning techniques would help contextualize the contributions of this work.
Overall, the proposed method appears to be a valuable contribution to the field of text detection in natural scenes. Further research could explore combining the Wavelet-based approach with deep learning techniques to leverage the strengths of both and develop even more robust and versatile text detection solutions.
Conclusion
This paper presents a novel and efficient framework for detecting text regions in images with complex backgrounds using Wavelet Transforms. The method is more sophisticated than previous approaches as it is not limited to a particular font size or style of text, making it a versatile solution for a wide range of applications.
The experimental results demonstrate the effectiveness of the proposed technique, which could have significant implications for fields such as document scanning, scene text recognition, and image-based text editing. Further research could explore combining this Wavelet-based approach with deep learning methods to develop even more robust and versatile text detection solutions.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🔎
0
New!A Novel Framework For Text Detection From Natural Scene Images With Complex Background
Basavaraj Kaladagi, Jagadeesh Pujari
Recognizing texts from camera images is a known hard problem because of the difficulties in text detection from the varied and complicated background. In this paper we propose a novel and efficient method to detect text region from images with complex background using Wavelet Transforms. The framework uses Wavelet Transformation of the original image in its grayscale form followed by Sub-band filtering. Then Region clustering technique is applied using centroids of the regions, further Bounding box is fitted to each region thus identifying the text regions. This method is much sophisticated and efficient than the previous methods as it doesn't stick to a particular font size of the text thus, making it generalized. The sample set used for experimental purpose consists of 50 images with varying backgrounds. Images with edge prominence are considered. Furthermore, our method can be easily customized for applications with different scopes.
Read more9/17/2024
🖼️
0
Text-Driven Image Editing via Learnable Regions
Yuanze Lin, Yi-Wen Chen, Yi-Hsuan Tsai, Lu Jiang, Ming-Hsuan Yang
Language has emerged as a natural interface for image editing. In this paper, we introduce a method for region-based image editing driven by textual prompts, without the need for user-provided masks or sketches. Specifically, our approach leverages an existing pre-trained text-to-image model and introduces a bounding box generator to identify the editing regions that are aligned with the textual prompts. We show that this simple approach enables flexible editing that is compatible with current image generation models, and is able to handle complex prompts featuring multiple objects, complex sentences, or lengthy paragraphs. We conduct an extensive user study to compare our method against state-of-the-art methods. The experiments demonstrate the competitive performance of our method in manipulating images with high fidelity and realism that correspond to the provided language descriptions. Our project webpage can be found at: https://yuanze-lin.me/LearnableRegions_page.
Read more4/4/2024
0
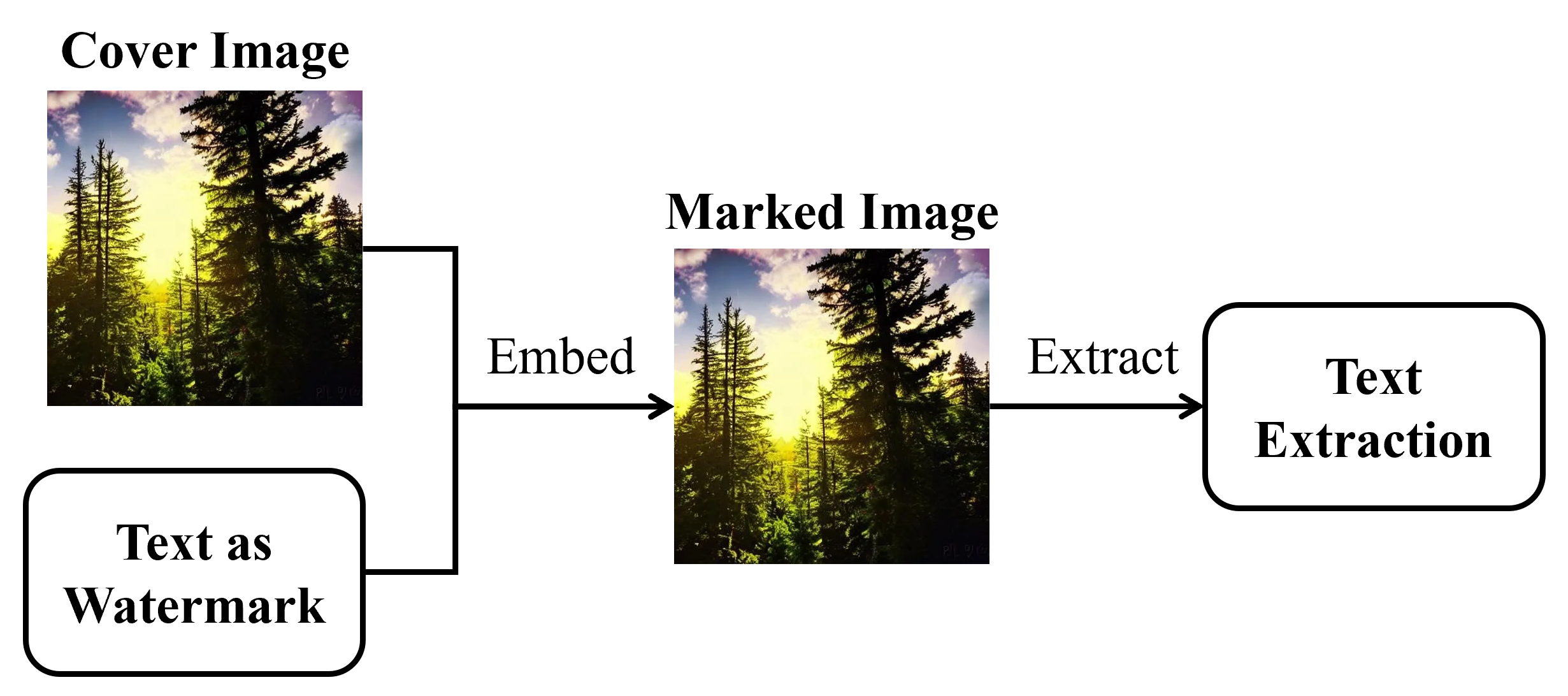
Deep Learning-based Text-in-Image Watermarking
Bishwa Karki, Chun-Hua Tsai, Pei-Chi Huang, Xin Zhong
In this work, we introduce a novel deep learning-based approach to text-in-image watermarking, a method that embeds and extracts textual information within images to enhance data security and integrity. Leveraging the capabilities of deep learning, specifically through the use of Transformer-based architectures for text processing and Vision Transformers for image feature extraction, our method sets new benchmarks in the domain. The proposed method represents the first application of deep learning in text-in-image watermarking that improves adaptivity, allowing the model to intelligently adjust to specific image characteristics and emerging threats. Through testing and evaluation, our method has demonstrated superior robustness compared to traditional watermarking techniques, achieving enhanced imperceptibility that ensures the watermark remains undetectable across various image contents.
Read more4/23/2024

0
Seeing Text in the Dark: Algorithm and Benchmark
Chengpei Xu, Hao Fu, Long Ma, Wenjing Jia, Chengqi Zhang, Feng Xia, Xiaoyu Ai, Binghao Li, Wenjie Zhang
Localizing text in low-light environments is challenging due to visual degradations. Although a straightforward solution involves a two-stage pipeline with low-light image enhancement (LLE) as the initial step followed by detector, LLE is primarily designed for human vision instead of machine and can accumulate errors. In this work, we propose an efficient and effective single-stage approach for localizing text in dark that circumvents the need for LLE. We introduce a constrained learning module as an auxiliary mechanism during the training stage of the text detector. This module is designed to guide the text detector in preserving textual spatial features amidst feature map resizing, thus minimizing the loss of spatial information in texts under low-light visual degradations. Specifically, we incorporate spatial reconstruction and spatial semantic constraints within this module to ensure the text detector acquires essential positional and contextual range knowledge. Our approach enhances the original text detector's ability to identify text's local topological features using a dynamic snake feature pyramid network and adopts a bottom-up contour shaping strategy with a novel rectangular accumulation technique for accurate delineation of streamlined text features. In addition, we present a comprehensive low-light dataset for arbitrary-shaped text, encompassing diverse scenes and languages. Notably, our method achieves state-of-the-art results on this low-light dataset and exhibits comparable performance on standard normal light datasets. The code and dataset will be released.
Read more4/23/2024