Text-Driven Image Editing via Learnable Regions
2311.16432
0
0
🖼️
Abstract
Language has emerged as a natural interface for image editing. In this paper, we introduce a method for region-based image editing driven by textual prompts, without the need for user-provided masks or sketches. Specifically, our approach leverages an existing pre-trained text-to-image model and introduces a bounding box generator to identify the editing regions that are aligned with the textual prompts. We show that this simple approach enables flexible editing that is compatible with current image generation models, and is able to handle complex prompts featuring multiple objects, complex sentences, or lengthy paragraphs. We conduct an extensive user study to compare our method against state-of-the-art methods. The experiments demonstrate the competitive performance of our method in manipulating images with high fidelity and realism that correspond to the provided language descriptions. Our project webpage can be found at: https://yuanze-lin.me/LearnableRegions_page.
Create account to get full access
Overview
- This paper introduces a new method for region-based image editing using text prompts, without the need for user-provided masks or sketches.
- The approach leverages an existing text-to-image model and introduces a bounding box generator to identify editing regions aligned with the text.
- This enables flexible editing compatible with current image generation models, handling complex prompts with multiple objects, sentences, or paragraphs.
- The authors conduct a user study to compare their method to state-of-the-art approaches, demonstrating high-fidelity and realistic image manipulation based on language descriptions.
Plain English Explanation
Editing images can be a tricky task, often requiring users to carefully select and mask specific regions they want to change. This new method aims to simplify the process by allowing users to describe in words what they want to edit, without needing to draw boundaries or outlines.
The key idea is to use an existing AI model that can generate images from text descriptions. By coupling this with a "bounding box generator", the system can automatically identify the parts of the image that correspond to the text prompt. This allows users to edit the image in an intuitive, language-driven way, rather than having to manually select areas.
For example, a user could type "make the red car in the background bigger" and the system would know to focus its edits on the car region, without requiring the user to carefully select that area themselves. The authors show this works well even for complex prompts, like "add a cute dog playing with a ball in the foreground."
Overall, this approach makes image editing more accessible and efficient, by allowing users to describe their desired changes in natural language rather than relying on manual selection tools.
Technical Explanation
The core of this work is a two-stage process for region-based image editing:
-
Text-to-Image Modeling: The authors leverage an existing pre-trained text-to-image model, such as DALL-E or Stable Diffusion, which can generate images from textual descriptions.
-
Bounding Box Generation: They introduce a novel "bounding box generator" module, which takes the input image and text prompt and predicts a set of bounding boxes corresponding to the relevant regions to edit.
By combining these components, the system can take a text prompt, identify the relevant image regions, and then apply edits to those regions in a way that is consistent with the language description.
The authors evaluate their approach through extensive user studies, comparing it to state-of-the-art image editing baselines. The results demonstrate that their method can manipulate images with high fidelity and realism, in line with the provided language descriptions.
Critical Analysis
The authors acknowledge several limitations and areas for future work. For instance, the bounding box generator may not always perfectly capture the intended regions, and the system's ability to handle complex, open-ended language prompts is still limited.
Additionally, the reliance on pre-trained text-to-image models means the approach is constrained by the capabilities of those foundational models. As the field of AI-generated imagery continues to rapidly advance, future work could explore more tightly integrated approaches that jointly optimize the text understanding, region detection, and image editing components.
There are also broader questions around the societal implications of such language-driven image editing tools. While they can empower user creativity, they also raise concerns about the potential for misuse, such as the generation of misleading or manipulated imagery.
Overall, this work represents an interesting step forward in bridging the gap between language and image manipulation. However, there remains significant room for improvement and thoughtful consideration of the technology's impacts.
Conclusion
This paper introduces a novel method for region-based image editing driven by textual prompts, without requiring users to provide masks or sketches. By leveraging an existing text-to-image model and introducing a bounding box generator, the system can flexibly edit images in a way that aligns with natural language descriptions.
The authors' extensive user studies demonstrate the competitive performance of their approach, showing it can manipulate images with high fidelity and realism. While the method has some limitations, it represents an important advancement in making image editing more accessible and intuitive for users.
As AI-generated imagery continues to evolve, approaches like this could have significant implications for creative workflows, visual communication, and the spread of information online. However, the technology also raises important questions about the potential for misuse and the need for responsible development.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
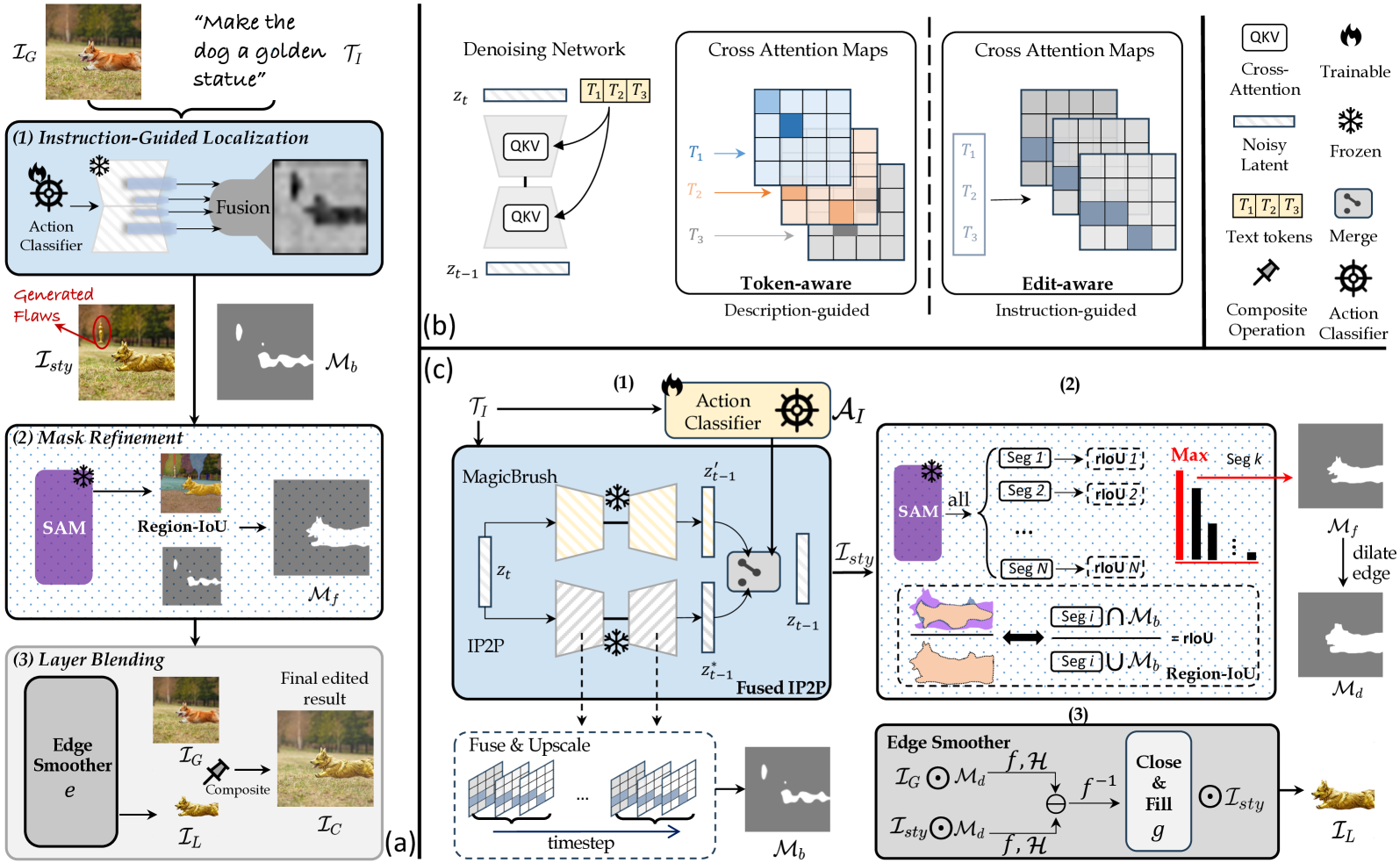
ZONE: Zero-Shot Instruction-Guided Local Editing
Shanglin Li, Bohan Zeng, Yutang Feng, Sicheng Gao, Xuhui Liu, Jiaming Liu, Li Lin, Xu Tang, Yao Hu, Jianzhuang Liu, Baochang Zhang
0
0
Recent advances in vision-language models like Stable Diffusion have shown remarkable power in creative image synthesis and editing.However, most existing text-to-image editing methods encounter two obstacles: First, the text prompt needs to be carefully crafted to achieve good results, which is not intuitive or user-friendly. Second, they are insensitive to local edits and can irreversibly affect non-edited regions, leaving obvious editing traces. To tackle these problems, we propose a Zero-shot instructiON-guided local image Editing approach, termed ZONE. We first convert the editing intent from the user-provided instruction (e.g., make his tie blue) into specific image editing regions through InstructPix2Pix. We then propose a Region-IoU scheme for precise image layer extraction from an off-the-shelf segment model. We further develop an edge smoother based on FFT for seamless blending between the layer and the image.Our method allows for arbitrary manipulation of a specific region with a single instruction while preserving the rest. Extensive experiments demonstrate that our ZONE achieves remarkable local editing results and user-friendliness, outperforming state-of-the-art methods. Code is available at https://github.com/lsl001006/ZONE.
4/15/2024

Text Guided Image Editing with Automatic Concept Locating and Forgetting
Jia Li, Lijie Hu, Zhixian He, Jingfeng Zhang, Tianhang Zheng, Di Wang
0
0
With the advancement of image-to-image diffusion models guided by text, significant progress has been made in image editing. However, a persistent challenge remains in seamlessly incorporating objects into images based on textual instructions, without relying on extra user-provided guidance. Text and images are inherently distinct modalities, bringing out difficulties in fully capturing the semantic intent conveyed through language and accurately translating that into the desired visual modifications. Therefore, text-guided image editing models often produce generations with residual object attributes that do not fully align with human expectations. To address this challenge, the models should comprehend the image content effectively away from a disconnect between the provided textual editing prompts and the actual modifications made to the image. In our paper, we propose a novel method called Locate and Forget (LaF), which effectively locates potential target concepts in the image for modification by comparing the syntactic trees of the target prompt and scene descriptions in the input image, intending to forget their existence clues in the generated image. Compared to the baselines, our method demonstrates its superiority in text-guided image editing tasks both qualitatively and quantitatively.
5/31/2024
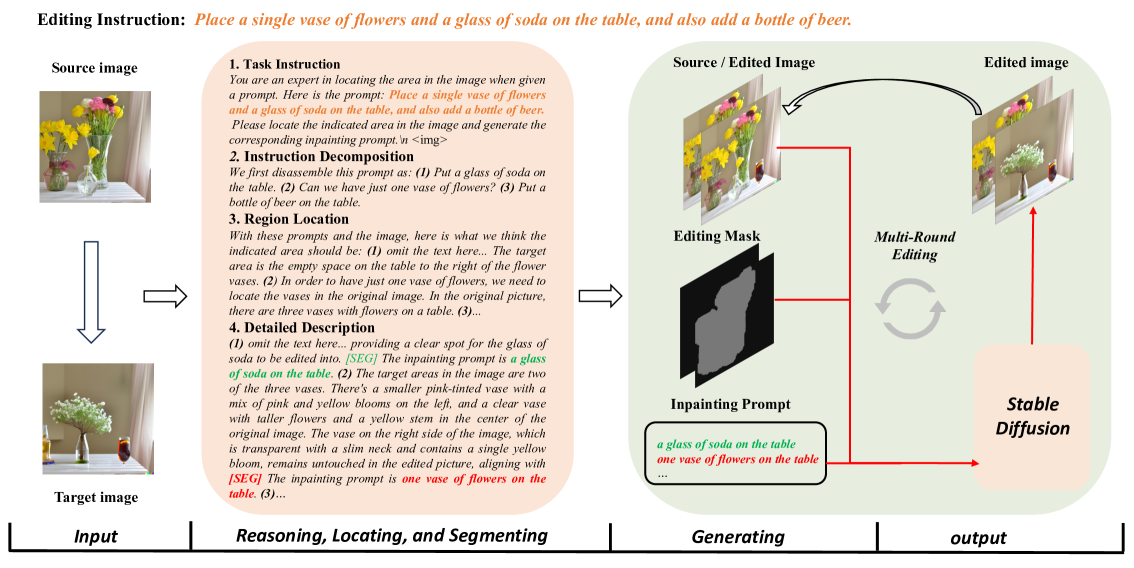
TIE: Revolutionizing Text-based Image Editing for Complex-Prompt Following and High-Fidelity Editing
Xinyu Zhang, Mengxue Kang, Fei Wei, Shuang Xu, Yuhe Liu, Lin Ma
0
0
As the field of image generation rapidly advances, traditional diffusion models and those integrated with multimodal large language models (LLMs) still encounter limitations in interpreting complex prompts and preserving image consistency pre and post-editing. To tackle these challenges, we present an innovative image editing framework that employs the robust Chain-of-Thought (CoT) reasoning and localizing capabilities of multimodal LLMs to aid diffusion models in generating more refined images. We first meticulously design a CoT process comprising instruction decomposition, region localization, and detailed description. Subsequently, we fine-tune the LISA model, a lightweight multimodal LLM, using the CoT process of Multimodal LLMs and the mask of the edited image. By providing the diffusion models with knowledge of the generated prompt and image mask, our models generate images with a superior understanding of instructions. Through extensive experiments, our model has demonstrated superior performance in image generation, surpassing existing state-of-the-art models. Notably, our model exhibits an enhanced ability to understand complex prompts and generate corresponding images, while maintaining high fidelity and consistency in images before and after generation.
5/28/2024
🛸
Expressive Text-to-Image Generation with Rich Text
Songwei Ge, Taesung Park, Jun-Yan Zhu, Jia-Bin Huang
0
0
Plain text has become a prevalent interface for text-to-image synthesis. However, its limited customization options hinder users from accurately describing desired outputs. For example, plain text makes it hard to specify continuous quantities, such as the precise RGB color value or importance of each word. Furthermore, creating detailed text prompts for complex scenes is tedious for humans to write and challenging for text encoders to interpret. To address these challenges, we propose using a rich-text editor supporting formats such as font style, size, color, and footnote. We extract each word's attributes from rich text to enable local style control, explicit token reweighting, precise color rendering, and detailed region synthesis. We achieve these capabilities through a region-based diffusion process. We first obtain each word's region based on attention maps of a diffusion process using plain text. For each region, we enforce its text attributes by creating region-specific detailed prompts and applying region-specific guidance, and maintain its fidelity against plain-text generation through region-based injections. We present various examples of image generation from rich text and demonstrate that our method outperforms strong baselines with quantitative evaluations.
5/30/2024