Novel-View Acoustic Synthesis from 3D Reconstructed Rooms

0
🖼️
Sign in to get full access
Overview
- The paper investigates using 3D scene information to improve the synthesis of audio at novel viewpoints in a scene with multiple unknown sound sources.
- They address the key challenges of sound source localization, separation, and dereverberation.
- Their method, which incorporates room impulse responses derived from 3D reconstructed rooms, outperforms existing methods on these individual tasks.
- In simulated experiments, the model achieves high accuracy on source localization and strong performance on source separation and dereverberation, resulting in high-quality novel-view acoustic synthesis.
Plain English Explanation
The researchers wanted to see if combining audio recordings with 3D information about a scene could help them recreate the sounds you would hear from any location in that scene. They had recordings from 2-4 microphones and knew the 3D shape and materials of the room, but didn't know where the sound sources were.
The main challenges they needed to tackle were figuring out where the sound sources were, separating the different sounds, and removing the effects of the room on the audio (called dereverberation). They found that a simple end-to-end machine learning approach didn't work very well. But by incorporating information about the acoustics of the 3D room, their model was able to jointly solve all these problems.
In their experiments, the model was able to accurately locate the sound sources and then separate and dereverberate the audio, resulting in high-quality audio that matched what you would hear from any spot in the 3D scene. This demonstrates the power of using 3D visual information to improve audio processing tasks.
Technical Explanation
The researchers propose a novel-view acoustic synthesis (NVAS) method that combines blind audio recordings with 3D scene information to enable high-quality audio synthesis from any viewpoint in the scene. They identify the key challenges as sound source localization, separation, and dereverberation.
Their approach builds on an end-to-end neural network architecture, but critically, it incorporates room impulse responses (RIRs) derived from the 3D reconstructed scene. This allows the network to jointly tackle the individual sub-tasks required for NVAS.
In experiments on the Matterport3D-NVAS dataset, the model achieves near-perfect accuracy on source localization. It also demonstrates strong performance on source separation and dereverberation, with a PSNR of 26.44dB and an SDR of 14.23dB. This results in an overall PSNR of 25.55dB and SDR of 14.20dB for the final NVAS task.
By leveraging the 3D scene information, the researchers' approach outperforms existing methods designed for the individual sub-tasks. This highlights the value of incorporating visual data to enhance audio processing capabilities.
Critical Analysis
The paper presents a promising approach for leveraging 3D scene data to tackle the complex task of novel-view acoustic synthesis. However, the experiments are limited to simulated data, and the real-world performance may differ.
Additionally, the paper does not explore the impact of inaccuracies or incompleteness in the 3D scene data, which could be a significant practical limitation. Further research is needed to understand how robust the method is to imperfect 3D information.
Another potential concern is the reliance on room impulse responses, which may not be available or easy to obtain in many real-world scenarios. Investigating alternative approaches to incorporate the 3D scene data could broaden the applicability of the technique.
Despite these caveats, the work demonstrates the value of leveraging visual information to enhance audio processing capabilities, which could have important implications for applications like augmented reality, virtual conferencing, and scene understanding.
Conclusion
This paper introduces a novel-view acoustic synthesis method that combines blind audio recordings with 3D scene information to enable high-quality audio synthesis from any viewpoint in a scene. By incorporating room impulse responses derived from the 3D reconstructed scene, the model is able to jointly tackle the key challenges of sound source localization, separation, and dereverberation.
The researchers' approach outperforms existing methods on these individual sub-tasks, highlighting the power of utilizing 3D visual data to enhance audio processing capabilities. While the current experiments are limited to simulated data, the work opens up exciting possibilities for improving audio-visual scene understanding and synthesis in real-world applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🖼️
0
Novel-View Acoustic Synthesis from 3D Reconstructed Rooms
Byeongjoo Ahn, Karren Yang, Brian Hamilton, Jonathan Sheaffer, Anurag Ranjan, Miguel Sarabia, Oncel Tuzel, Jen-Hao Rick Chang
We investigate the benefit of combining blind audio recordings with 3D scene information for novel-view acoustic synthesis. Given audio recordings from 2-4 microphones and the 3D geometry and material of a scene containing multiple unknown sound sources, we estimate the sound anywhere in the scene. We identify the main challenges of novel-view acoustic synthesis as sound source localization, separation, and dereverberation. While naively training an end-to-end network fails to produce high-quality results, we show that incorporating room impulse responses (RIRs) derived from 3D reconstructed rooms enables the same network to jointly tackle these tasks. Our method outperforms existing methods designed for the individual tasks, demonstrating its effectiveness at utilizing 3D visual information. In a simulated study on the Matterport3D-NVAS dataset, our model achieves near-perfect accuracy on source localization, a PSNR of 26.44dB and a SDR of 14.23dB for source separation and dereverberation, resulting in a PSNR of 25.55 dB and a SDR of 14.20 dB on novel-view acoustic synthesis. We release our code and model on our project website at https://github.com/apple/ml-nvas3d. Please wear headphones when listening to the results.
Read more8/19/2024
0
Hearing Anything Anywhere
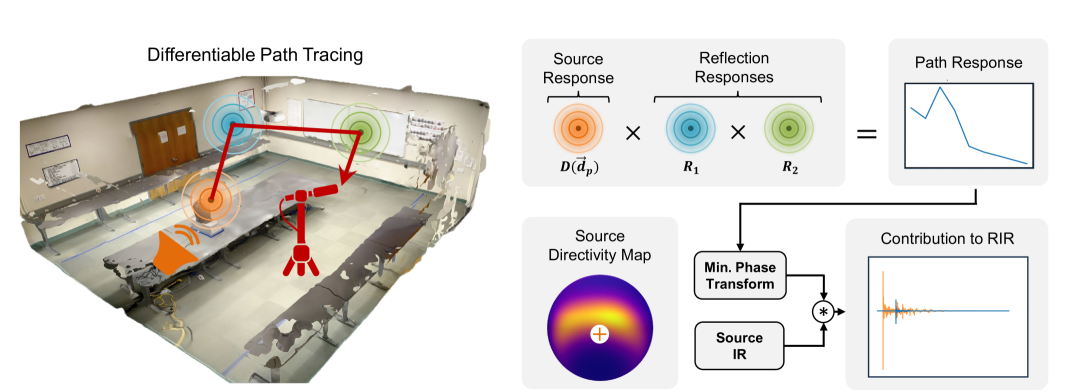
Mason Wang, Ryosuke Sawata, Samuel Clarke, Ruohan Gao, Shangzhe Wu, Jiajun Wu
Recent years have seen immense progress in 3D computer vision and computer graphics, with emerging tools that can virtualize real-world 3D environments for numerous Mixed Reality (XR) applications. However, alongside immersive visual experiences, immersive auditory experiences are equally vital to our holistic perception of an environment. In this paper, we aim to reconstruct the spatial acoustic characteristics of an arbitrary environment given only a sparse set of (roughly 12) room impulse response (RIR) recordings and a planar reconstruction of the scene, a setup that is easily achievable by ordinary users. To this end, we introduce DiffRIR, a differentiable RIR rendering framework with interpretable parametric models of salient acoustic features of the scene, including sound source directivity and surface reflectivity. This allows us to synthesize novel auditory experiences through the space with any source audio. To evaluate our method, we collect a dataset of RIR recordings and music in four diverse, real environments. We show that our model outperforms state-ofthe-art baselines on rendering monaural and binaural RIRs and music at unseen locations, and learns physically interpretable parameters characterizing acoustic properties of the sound source and surfaces in the scene.
Read more6/12/2024

0
AV-GS: Learning Material and Geometry Aware Priors for Novel View Acoustic Synthesis
Swapnil Bhosale, Haosen Yang, Diptesh Kanojia, Jiankang Deng, Xiatian Zhu
Novel view acoustic synthesis (NVAS) aims to render binaural audio at any target viewpoint, given a mono audio emitted by a sound source at a 3D scene. Existing methods have proposed NeRF-based implicit models to exploit visual cues as a condition for synthesizing binaural audio. However, in addition to low efficiency originating from heavy NeRF rendering, these methods all have a limited ability of characterizing the entire scene environment such as room geometry, material properties, and the spatial relation between the listener and sound source. To address these issues, we propose a novel Audio-Visual Gaussian Splatting (AV-GS) model. To obtain a material-aware and geometry-aware condition for audio synthesis, we learn an explicit point-based scene representation with an audio-guidance parameter on locally initialized Gaussian points, taking into account the space relation from the listener and sound source. To make the visual scene model audio adaptive, we propose a point densification and pruning strategy to optimally distribute the Gaussian points, with the per-point contribution in sound propagation (e.g., more points needed for texture-less wall surfaces as they affect sound path diversion). Extensive experiments validate the superiority of our AV-GS over existing alternatives on the real-world RWAS and simulation-based SoundSpaces datasets.
Read more6/17/2024

0
Pano2Room: Novel View Synthesis from a Single Indoor Panorama
Guo Pu, Yiming Zhao, Zhouhui Lian
Recent single-view 3D generative methods have made significant advancements by leveraging knowledge distilled from extensive 3D object datasets. However, challenges persist in the synthesis of 3D scenes from a single view, primarily due to the complexity of real-world environments and the limited availability of high-quality prior resources. In this paper, we introduce a novel approach called Pano2Room, designed to automatically reconstruct high-quality 3D indoor scenes from a single panoramic image. These panoramic images can be easily generated using a panoramic RGBD inpainter from captures at a single location with any camera. The key idea is to initially construct a preliminary mesh from the input panorama, and iteratively refine this mesh using a panoramic RGBD inpainter while collecting photo-realistic 3D-consistent pseudo novel views. Finally, the refined mesh is converted into a 3D Gaussian Splatting field and trained with the collected pseudo novel views. This pipeline enables the reconstruction of real-world 3D scenes, even in the presence of large occlusions, and facilitates the synthesis of photo-realistic novel views with detailed geometry. Extensive qualitative and quantitative experiments have been conducted to validate the superiority of our method in single-panorama indoor novel synthesis compared to the state-of-the-art. Our code and data are available at url{https://github.com/TrickyGo/Pano2Room}.
Read more8/28/2024