Hearing Anything Anywhere
2406.07532
0
0
Abstract
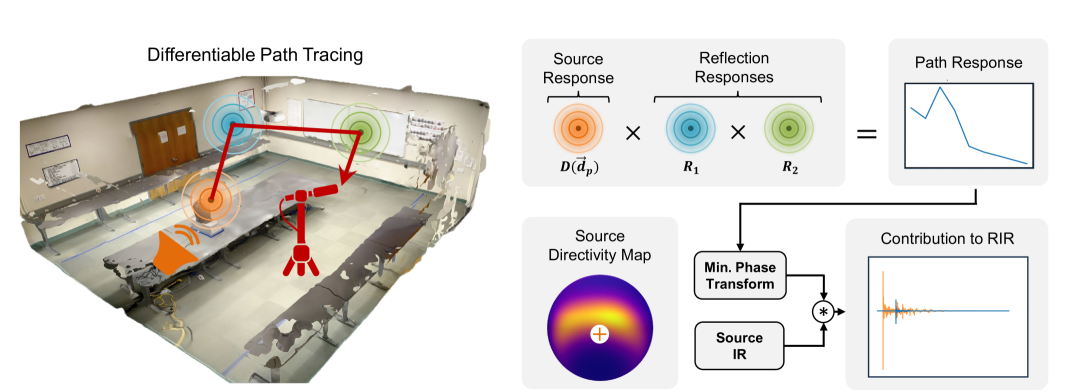
Recent years have seen immense progress in 3D computer vision and computer graphics, with emerging tools that can virtualize real-world 3D environments for numerous Mixed Reality (XR) applications. However, alongside immersive visual experiences, immersive auditory experiences are equally vital to our holistic perception of an environment. In this paper, we aim to reconstruct the spatial acoustic characteristics of an arbitrary environment given only a sparse set of (roughly 12) room impulse response (RIR) recordings and a planar reconstruction of the scene, a setup that is easily achievable by ordinary users. To this end, we introduce DiffRIR, a differentiable RIR rendering framework with interpretable parametric models of salient acoustic features of the scene, including sound source directivity and surface reflectivity. This allows us to synthesize novel auditory experiences through the space with any source audio. To evaluate our method, we collect a dataset of RIR recordings and music in four diverse, real environments. We show that our model outperforms state-ofthe-art baselines on rendering monaural and binaural RIRs and music at unseen locations, and learns physically interpretable parameters characterizing acoustic properties of the sound source and surfaces in the scene.
Create account to get full access
Overview
- This paper presents a novel method for "hearing anything anywhere" by leveraging active audio-visual exploration of acoustic environments.
- The proposed approach combines techniques from audio-visual scene understanding, room impulse response modeling, and spatial audio simulation to enable users to aurally experience any real-world space.
- Key innovations include an active exploration strategy for rapidly capturing room acoustics, and a 3D room geometry inference model for generalizing to unseen environments.
Plain English Explanation
The paper describes a system that allows you to "hear" what any real-world space would sound like, even if you've never been there before. It does this by combining a few different technologies:
- Audio-visual Scene Understanding: The system can analyze images and videos of a space to understand its physical layout and acoustic properties.
- Room Impulse Response Modeling: It can create a model of how sound waves would bounce around and interact with the surfaces in that space.
- Spatial Audio Simulation: Using this model, the system can then generate an audio simulation of what it would sound like to be in that space, as if you were actually there.
The key innovation is an "active exploration" strategy, where the system can quickly capture the essential acoustic details of a space by intelligently moving a microphone and camera around. It also has a 3D room geometry inference model that allows it to generalize to new spaces it hasn't directly measured.
So in essence, this technology allows you to "visit" and experience the acoustics of any real-world location, even if you've never been there before. You could, for example, virtually "walk through" a concert hall, museum, or even a friend's living room and hear how sound would propagate throughout the space.
Technical Explanation
The paper presents a novel approach for capturing and simulating the acoustic properties of real-world environments, enabling users to virtually "hear" any space.
At the core of the system is an active audio-visual exploration strategy for rapidly acquiring room impulse responses (RIRs) - the acoustic "fingerprints" that characterize how sound waves interact with a space. This involves strategically moving a microphone and camera through the environment to efficiently capture the essential acoustic details.
The acquired RIR data is then used to train a 3D room geometry inference model that can generalize to predict the acoustic properties of unseen spaces from visual inputs alone. This allows the system to simulate the acoustics of a new environment without requiring direct in-situ measurements.
The predicted room acoustics are then used to drive a spatial audio simulation that allows users to virtually "hear" what any real-world space would sound like. This leverages techniques from audio-visual scene understanding and reverberant speech modeling to generate immersive aural experiences.
Critical Analysis
The paper presents a compelling technical approach for enabling virtual acoustic experiences of real-world environments. The active exploration strategy and 3D room geometry inference model are innovative contributions that address the challenge of efficiently capturing and generalizing room acoustics.
However, the paper does not address potential limitations or caveats of the proposed system. For example, it is unclear how the system would perform in highly complex or dynamic environments, or how accurately it can reproduce nuanced acoustic details. Additionally, the paper does not discuss privacy or ethical considerations around virtually "accessing" private spaces.
Further research is needed to validate the system's robustness, accuracy, and generalizability across a wider range of real-world scenarios. Potential future work could also explore applications beyond just audio simulation, such as using the inferred room acoustics for tasks like sound source localization or speech enhancement.
Conclusion
This paper introduces a novel method for "hearing anything anywhere" by combining techniques from audio-visual scene understanding, room impulse response modeling, and spatial audio simulation. The key innovations are an active exploration strategy for rapidly capturing room acoustics and a 3D room geometry inference model for generalizing to unseen environments.
This technology has the potential to enable immersive virtual experiences of real-world spaces, allowing users to aurally "visit" and explore any location. While further research is needed to address limitations, this work represents an exciting step towards more perceptually-faithful digital representations of the physical world.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

ActiveRIR: Active Audio-Visual Exploration for Acoustic Environment Modeling
Arjun Somayazulu, Sagnik Majumder, Changan Chen, Kristen Grauman
0
0
An environment acoustic model represents how sound is transformed by the physical characteristics of an indoor environment, for any given source/receiver location. Traditional methods for constructing acoustic models involve expensive and time-consuming collection of large quantities of acoustic data at dense spatial locations in the space, or rely on privileged knowledge of scene geometry to intelligently select acoustic data sampling locations. We propose active acoustic sampling, a new task for efficiently building an environment acoustic model of an unmapped environment in which a mobile agent equipped with visual and acoustic sensors jointly constructs the environment acoustic model and the occupancy map on-the-fly. We introduce ActiveRIR, a reinforcement learning (RL) policy that leverages information from audio-visual sensor streams to guide agent navigation and determine optimal acoustic data sampling positions, yielding a high quality acoustic model of the environment from a minimal set of acoustic samples. We train our policy with a novel RL reward based on information gain in the environment acoustic model. Evaluating on diverse unseen indoor environments from a state-of-the-art acoustic simulation platform, ActiveRIR outperforms an array of methods--both traditional navigation agents based on spatial novelty and visual exploration as well as existing state-of-the-art methods.
4/26/2024

RevRIR: Joint Reverberant Speech and Room Impulse Response Embedding using Contrastive Learning with Application to Room Shape Classification
Jacob Bitterman, Daniel Levi, Hilel Hagai Diamandi, Sharon Gannot, Tal Rosenwein
0
0
This paper focuses on room fingerprinting, a task involving the analysis of an audio recording to determine the specific volume and shape of the room in which it was captured. While it is relatively straightforward to determine the basic room parameters from the Room Impulse Responses (RIR), doing so from a speech signal is a cumbersome task. To address this challenge, we introduce a dual-encoder architecture that facilitates the estimation of room parameters directly from speech utterances. During pre-training, one encoder receives the RIR while the other processes the reverberant speech signal. A contrastive loss function is employed to embed the speech and the acoustic response jointly. In the fine-tuning stage, the specific classification task is trained. In the test phase, only the reverberant utterance is available, and its embedding is used for the task of room shape classification. The proposed scheme is extensively evaluated using simulated acoustic environments.
6/6/2024
✨
RIR-SF: Room Impulse Response Based Spatial Feature for Target Speech Recognition in Multi-Channel Multi-Speaker Scenarios
Yiwen Shao, Shi-Xiong Zhang, Dong Yu
0
0
Automatic speech recognition (ASR) on multi-talker recordings is challenging. Current methods using 3D spatial data from multi-channel audio and visual cues focus mainly on direct waves from the target speaker, overlooking reflection wave impacts, which hinders performance in reverberant environments. Our research introduces RIR-SF, a novel spatial feature based on room impulse response (RIR) that leverages the speaker's position, room acoustics, and reflection dynamics. RIR-SF significantly outperforms traditional 3D spatial features, showing superior theoretical and empirical performance. We also propose an optimized all-neural multi-channel ASR framework for RIR-SF, achieving a relative 21.3% reduction in CER for target speaker ASR in multi-channel settings. RIR-SF enhances recognition accuracy and demonstrates robustness in high-reverberation scenarios, overcoming the limitations of previous methods.
6/13/2024
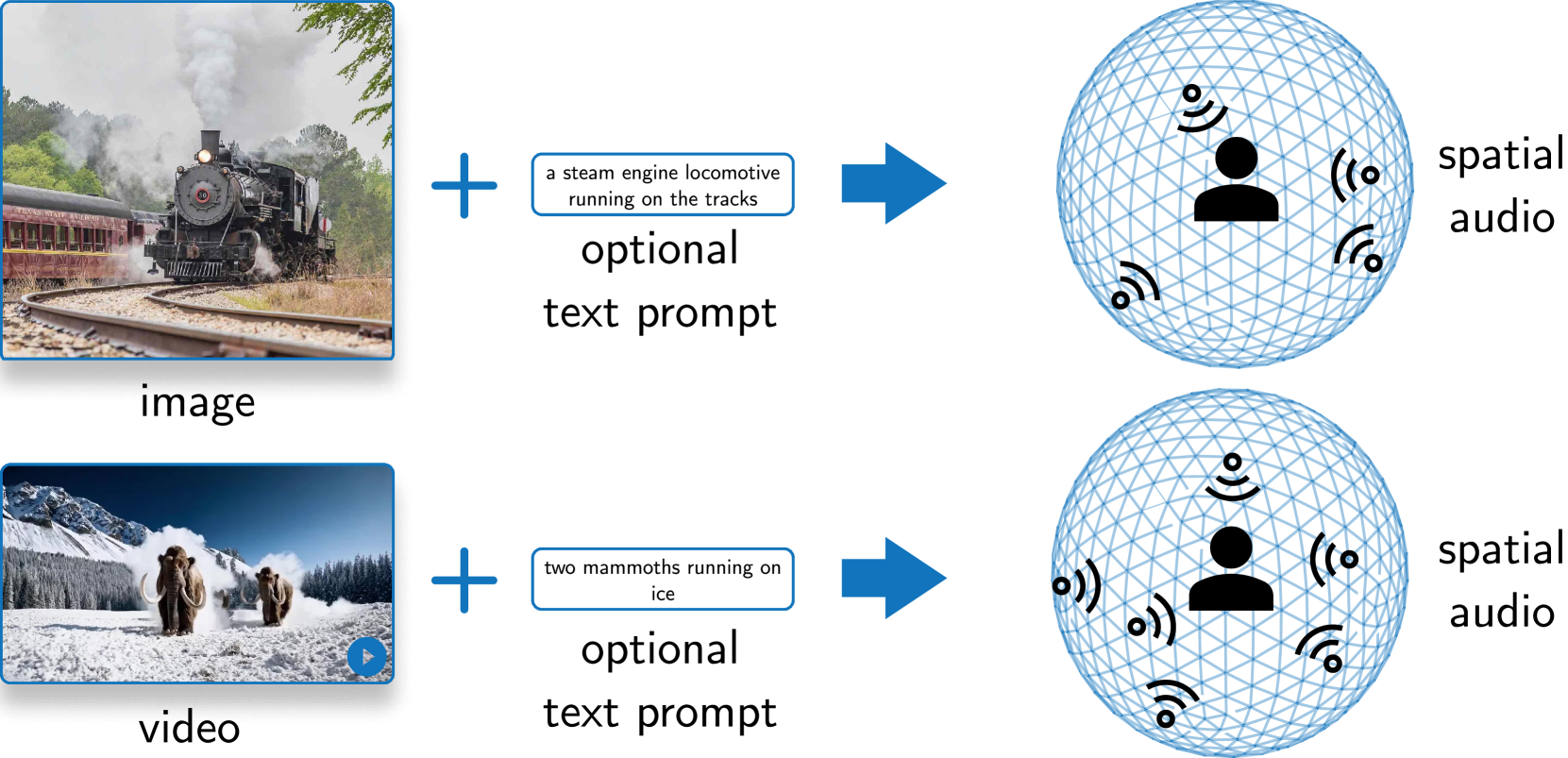
SEE-2-SOUND: Zero-Shot Spatial Environment-to-Spatial Sound
Rishit Dagli, Shivesh Prakash, Robert Wu, Houman Khosravani
0
0
Generating combined visual and auditory sensory experiences is critical for the consumption of immersive content. Recent advances in neural generative models have enabled the creation of high-resolution content across multiple modalities such as images, text, speech, and videos. Despite these successes, there remains a significant gap in the generation of high-quality spatial audio that complements generated visual content. Furthermore, current audio generation models excel in either generating natural audio or speech or music but fall short in integrating spatial audio cues necessary for immersive experiences. In this work, we introduce SEE-2-SOUND, a zero-shot approach that decomposes the task into (1) identifying visual regions of interest; (2) locating these elements in 3D space; (3) generating mono-audio for each; and (4) integrating them into spatial audio. Using our framework, we demonstrate compelling results for generating spatial audio for high-quality videos, images, and dynamic images from the internet, as well as media generated by learned approaches.
6/12/2024