O-Mamba: O-shape State-Space Model for Underwater Image Enhancement

0

Sign in to get full access
Overview
- Introduces a novel underwater image enhancement model called O-Mamba
- Uses an O-shape state-space model to capture the complex relationships between underwater image factors
- Aims to improve visual quality and remove haze and color distortion
Plain English Explanation
The paper presents a new technique called O-Mamba for enhancing underwater images. Underwater photos often suffer from haze, color distortion, and other visual issues due to the effects of water on light.
O-Mamba uses a special type of mathematical model called an "O-shape state-space model" to better represent the complex relationships between different factors that impact the quality of underwater images. This allows the system to more effectively correct common problems and produce clearer, more natural-looking results.
The key innovation is the O-shape design of the state-space model, which can capture intricate interdependencies in the underwater environment that affect image quality. This is an advance over previous approaches that relied on simpler models.
Technical Explanation
The paper introduces the O-Mamba underwater image enhancement framework, which leverages an O-shape state-space model. This model is designed to effectively represent the complex relationships between various factors that impact underwater image quality, such as water turbidity, light scattering, and color distortion.
The O-Mamba architecture consists of an encoder network that extracts features from the input image, an O-shape state-space module that models the underlying image formation process, and a decoder network that generates the enhanced output. The state-space module uses a novel O-shaped structure to capture the interdependencies between different image degradation factors.
Experiments demonstrate that O-Mamba outperforms prior underwater image enhancement methods in terms of both quantitative metrics and qualitative visual assessment. The model is able to effectively remove haze, restore colors, and improve overall image clarity compared to existing techniques.
Critical Analysis
The paper provides a thorough technical explanation of the O-Mamba framework and validates its performance through extensive experiments. However, the authors do not discuss any potential limitations or caveats of the approach.
One area that could be explored further is the robustness of O-Mamba to different underwater environments and image capture conditions. The paper focuses on a specific dataset, and it would be valuable to assess the model's generalization capabilities across a wider range of underwater scenarios.
Additionally, the paper does not compare O-Mamba to the latest state-of-the-art deep learning-based methods for underwater image enhancement. It would be insightful to understand how O-Mamba's performance compares to these more recent techniques.
Conclusion
The O-Mamba paper presents a novel underwater image enhancement framework that leverages an O-shape state-space model to effectively capture the complex relationships between various degradation factors. The model demonstrates promising results in improving visual quality, removing haze, and restoring colors in underwater images.
While the technical explanation and experimental validation are thorough, the paper could benefit from a more comprehensive discussion of potential limitations and a broader comparison to the latest developments in the field. Nonetheless, the O-Mamba approach represents an interesting advancement in the challenging problem of underwater image enhancement.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
O-Mamba: O-shape State-Space Model for Underwater Image Enhancement
Chenyu Dong, Chen Zhao, Weiling Cai, Bo Yang
Underwater image enhancement (UIE) face significant challenges due to complex underwater lighting conditions. Recently, mamba-based methods have achieved promising results in image enhancement tasks. However, these methods commonly rely on Vmamba, which focuses only on spatial information modeling and struggles to deal with the cross-color channel dependency problem in underwater images caused by the differential attenuation of light wavelengths, limiting the effective use of deep networks. In this paper, we propose a novel UIE framework called O-mamba. O-mamba employs an O-shaped dual-branch network to separately model spatial and cross-channel information, utilizing the efficient global receptive field of state-space models optimized for underwater images. To enhance information interaction between the two branches and effectively utilize multi-scale information, we design a Multi-scale Bi-mutual Promotion Module. This branch includes MS-MoE for fusing multi-scale information within branches, Mutual Promotion module for interaction between spatial and channel information across branches, and Cyclic Multi-scale optimization strategy to maximize the use of multi-scale information. Extensive experiments demonstrate that our method achieves state-of-the-art (SOTA) results.The code is available at https://github.com/chenydong/O-Mamba.
Read more8/26/2024

0
WaterMamba: Visual State Space Model for Underwater Image Enhancement
Meisheng Guan, Haiyong Xu, Gangyi Jiang, Mei Yu, Yeyao Chen, Ting Luo, Yang Song
Underwater imaging often suffers from low quality due to factors affecting light propagation and absorption in water. To improve image quality, some underwater image enhancement (UIE) methods based on convolutional neural networks (CNN) and Transformer have been proposed. However, CNN-based UIE methods are limited in modeling long-range dependencies, and Transformer-based methods involve a large number of parameters and complex self-attention mechanisms, posing efficiency challenges. Considering computational complexity and severe underwater image degradation, a state space model (SSM) with linear computational complexity for UIE, named WaterMamba, is proposed. We propose spatial-channel omnidirectional selective scan (SCOSS) blocks comprising spatial-channel coordinate omnidirectional selective scan (SCCOSS) modules and a multi-scale feedforward network (MSFFN). The SCOSS block models pixel and channel information flow, addressing dependencies. The MSFFN facilitates information flow adjustment and promotes synchronized operations within SCCOSS modules. Extensive experiments showcase WaterMamba's cutting-edge performance with reduced parameters and computational resources, outperforming state-of-the-art methods on various datasets, validating its effectiveness and generalizability. The code will be released on GitHub after acceptance.
Read more5/15/2024
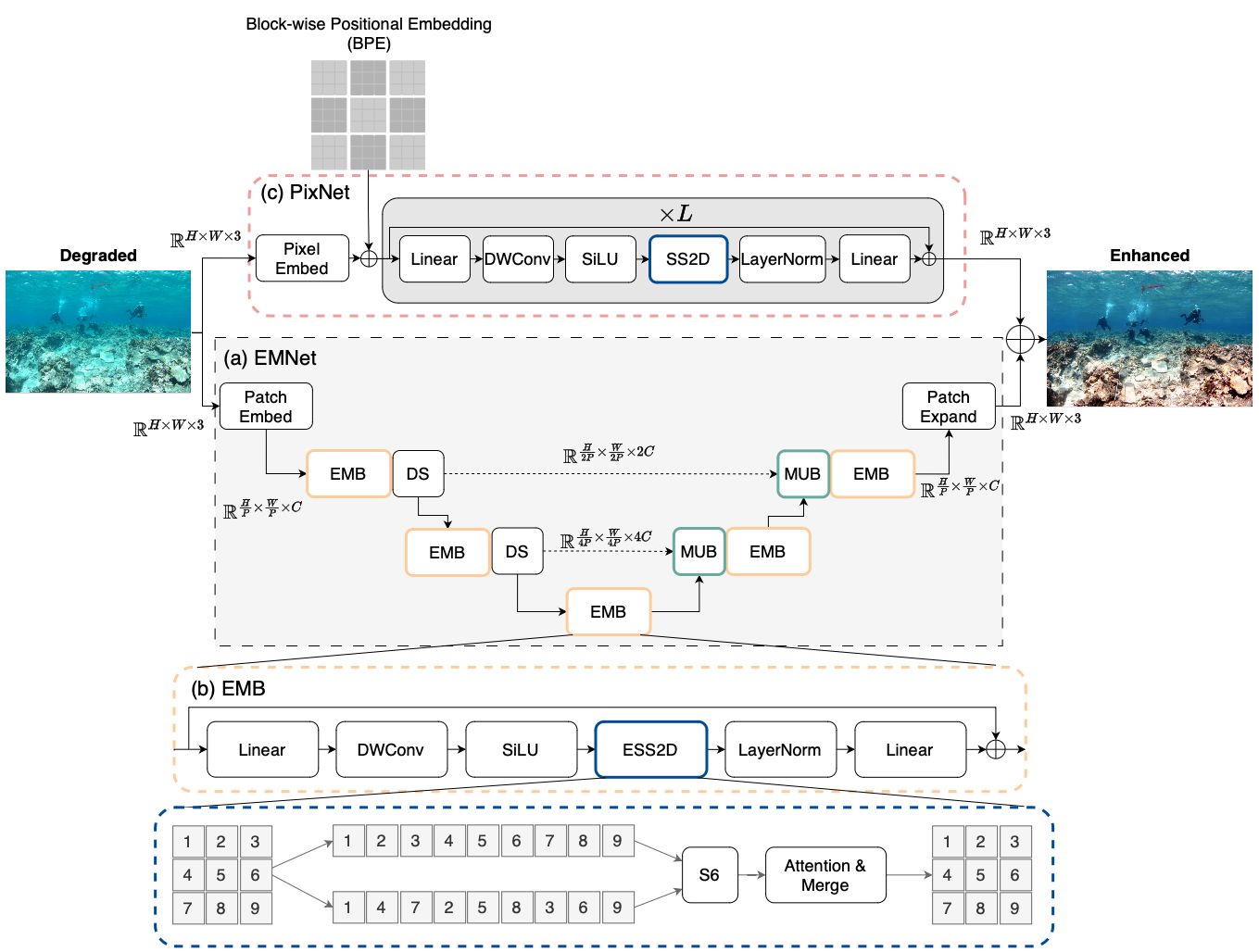
0
PixMamba: Leveraging State Space Models in a Dual-Level Architecture for Underwater Image Enhancement
Wei-Tung Lin, Yong-Xiang Lin, Jyun-Wei Chen, Kai-Lung Hua
Underwater Image Enhancement (UIE) is critical for marine research and exploration but hindered by complex color distortions and severe blurring. Recent deep learning-based methods have achieved remarkable results, yet these methods struggle with high computational costs and insufficient global modeling, resulting in locally under- or over- adjusted regions. We present PixMamba, a novel architecture, designed to overcome these challenges by leveraging State Space Models (SSMs) for efficient global dependency modeling. Unlike convolutional neural networks (CNNs) with limited receptive fields and transformer networks with high computational costs, PixMamba efficiently captures global contextual information while maintaining computational efficiency. Our dual-level strategy features the patch-level Efficient Mamba Net (EMNet) for reconstructing enhanced image feature and the pixel-level PixMamba Net (PixNet) to ensure fine-grained feature capturing and global consistency of enhanced image that were previously difficult to obtain. PixMamba achieves state-of-the-art performance across various underwater image datasets and delivers visually superior results. Code is available at: https://github.com/weitunglin/pixmamba.
Read more6/13/2024
📈
0
Mamba-UIE: Enhancing Underwater Images with Physical Model Constraint
Song Zhang, Yuqing Duan, Daoliang Li, Ran Zhao
In underwater image enhancement (UIE), convolutional neural networks (CNN) have inherent limitations in modeling long-range dependencies and are less effective in recovering global features. While Transformers excel at modeling long-range dependencies, their quadratic computational complexity with increasing image resolution presents significant efficiency challenges. Additionally, most supervised learning methods lack effective physical model constraint, which can lead to insufficient realism and overfitting in generated images. To address these issues, we propose a physical model constraint-based underwater image enhancement framework, Mamba-UIE. Specifically, we decompose the input image into four components: underwater scene radiance, direct transmission map, backscatter transmission map, and global background light. These components are reassembled according to the revised underwater image formation model, and the reconstruction consistency constraint is applied between the reconstructed image and the original image, thereby achieving effective physical constraint on the underwater image enhancement process. To tackle the quadratic computational complexity of Transformers when handling long sequences, we introduce the Mamba-UIE network based on linear complexity state space models. By incorporating the Mamba in Convolution block, long-range dependencies are modeled at both the channel and spatial levels, while the CNN backbone is retained to recover local features and details. Extensive experiments on three public datasets demonstrate that our proposed Mamba-UIE outperforms existing state-of-the-art methods, achieving a PSNR of 27.13 and an SSIM of 0.93 on the UIEB dataset. Our method is available at https://github.com/zhangsong1213/Mamba-UIE.
Read more8/1/2024