Object-Centric Diffusion for Efficient Video Editing

0

Sign in to get full access
Overview
- This paper presents a novel object-centric diffusion model for efficient video editing.
- The key idea is to decompose the video into individual objects, apply diffusion-based editing to each object separately, and then recombine the edited objects to produce the final video.
- This approach allows for more fine-grained control and efficient editing of videos compared to traditional, holistic video diffusion models.
Plain English Explanation
The paper introduces a new way to edit videos using a technique called "object-centric diffusion." <a href="https://aimodels.fyi/papers/arxiv/edit-your-motion-space-time-diffusion-decoupling">Traditional video editing models</a> tend to treat the entire video as a single entity, making it difficult to make precise changes. In contrast, the object-centric approach first breaks the video down into its individual components, such as people, objects, and backgrounds.
Then, the researchers apply a <a href="https://aimodels.fyi/papers/arxiv/motion-consistency-model-accelerating-video-diffusion-disentangled">diffusion-based editing process</a> to each object separately. This allows them to make very targeted changes, like changing the color of a car or the position of a person, without affecting the rest of the video. Finally, they recombine all the edited objects back into a single, cohesive video.
The key benefit of this approach is that it gives video editors much more control and flexibility compared to traditional methods. Instead of having to make broad, sweeping changes to an entire video, they can focus in on specific elements and tweak them precisely. This could be particularly useful for tasks like visual effects, where filmmakers need to make delicate adjustments to individual objects.
Technical Explanation
The paper proposes an "object-centric diffusion" model for efficient video editing. The core idea is to decompose the input video into individual objects, apply diffusion-based editing to each object separately, and then recombine the edited objects into the final output video.
The architecture consists of three main components: a Video Encoder, an Object Extractor, and a Diffusion-based Editor. The Video Encoder first converts the input video into a latent representation. The Object Extractor then identifies and segments the individual objects in the video. Finally, the Diffusion-based Editor applies a <a href="https://aimodels.fyi/papers/arxiv/pixel-distillation-new-knowledge-distillation-scheme-low">diffusion process</a> to edit each object independently, before recombining them to produce the edited output video.
The key innovation is performing the diffusion-based editing at the object level, rather than on the entire video holistically. This allows for more fine-grained control and efficient editing, as changes can be precisely targeted to specific elements of the scene. The authors demonstrate the effectiveness of their approach through a series of video editing tasks, including object removal, object insertion, and attribute manipulation.
Critical Analysis
The paper presents a promising approach for efficient video editing, but there are a few potential limitations and areas for further research:
-
<a href="https://aimodels.fyi/papers/arxiv/camera-clustering-scalable-stream-based-active-distillation">Object segmentation accuracy</a>: The performance of the overall system is heavily dependent on the ability of the Object Extractor to accurately identify and segment the individual objects in the video. Errors or inaccuracies in this step could lead to suboptimal editing results.
-
<a href="https://aimodels.fyi/papers/arxiv/teaching-uncertainty-unleashing-potential-knowledge-distillation-object">Handling occlusions and complex scenes</a>: The paper focuses on relatively simple scenes with clearly defined objects. It's unclear how well the approach would scale to more complex, cluttered environments with significant occlusions and overlapping objects.
-
Temporal consistency: While the paper mentions maintaining "motion consistency" during editing, it's unclear how well the approach handles preserving the overall temporal dynamics and flow of the video, particularly for complex motions and interactions between objects.
-
Computational efficiency: Decomposing the video into individual objects and applying separate diffusion processes could potentially be computationally intensive, especially for longer or higher-resolution videos. The paper does not provide a thorough analysis of the runtime performance of the system.
Overall, the object-centric diffusion approach is a promising direction for video editing, but further research is needed to address these limitations and explore the full potential of the technique.
Conclusion
This paper presents a novel object-centric diffusion model for efficient video editing. By decomposing the input video into individual objects, applying diffusion-based editing to each object separately, and then recombining the edited objects, the approach offers significantly more control and flexibility compared to traditional, holistic video diffusion models.
The key benefits of this approach include the ability to make precise, targeted changes to specific elements of a scene, as well as potentially improved computational efficiency by focusing the editing process on the most relevant parts of the video. While the paper identifies some limitations, such as the reliance on accurate object segmentation, the overall concept represents an exciting advancement in the field of video editing and manipulation.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Object-Centric Diffusion for Efficient Video Editing
Kumara Kahatapitiya, Adil Karjauv, Davide Abati, Fatih Porikli, Yuki M. Asano, Amirhossein Habibian
Diffusion-based video editing have reached impressive quality and can transform either the global style, local structure, and attributes of given video inputs, following textual edit prompts. However, such solutions typically incur heavy memory and computational costs to generate temporally-coherent frames, either in the form of diffusion inversion and/or cross-frame attention. In this paper, we conduct an analysis of such inefficiencies, and suggest simple yet effective modifications that allow significant speed-ups whilst maintaining quality. Moreover, we introduce Object-Centric Diffusion, to fix generation artifacts and further reduce latency by allocating more computations towards foreground edited regions, arguably more important for perceptual quality. We achieve this by two novel proposals: i) Object-Centric Sampling, decoupling the diffusion steps spent on salient or background regions and spending most on the former, and ii) Object-Centric Token Merging, which reduces cost of cross-frame attention by fusing redundant tokens in unimportant background regions. Both techniques are readily applicable to a given video editing model without retraining, and can drastically reduce its memory and computational cost. We evaluate our proposals on inversion-based and control-signal-based editing pipelines, and show a latency reduction up to 10x for a comparable synthesis quality. Project page: qualcomm-ai-research.github.io/object-centric-diffusion.
Read more9/2/2024

0
Domain-invariant Progressive Knowledge Distillation for UAV-based Object Detection
Liang Yao, Fan Liu, Chuanyi Zhang, Zhiquan Ou, Ting Wu
Knowledge distillation (KD) is an effective method for compressing models in object detection tasks. Due to limited computational capability, UAV-based object detection (UAV-OD) widely adopt the KD technique to obtain lightweight detectors. Existing methods often overlook the significant differences in feature space caused by the large gap in scale between the teacher and student models. This limitation hampers the efficiency of knowledge transfer during the distillation process. Furthermore, the complex backgrounds in UAV images make it challenging for the student model to efficiently learn the object features. In this paper, we propose a novel knowledge distillation framework for UAV-OD. Specifically, a progressive distillation approach is designed to alleviate the feature gap between teacher and student models. Then a new feature alignment method is provided to extract object-related features for enhancing student model's knowledge reception efficiency. Finally, extensive experiments are conducted to validate the effectiveness of our proposed approach. The results demonstrate that our proposed method achieves state-of-the-art (SoTA) performance in two UAV-OD datasets.
Read more8/22/2024
🖼️
0
Pixel Distillation: A New Knowledge Distillation Scheme for Low-Resolution Image Recognition
Guangyu Guo, Dingwen Zhang, Longfei Han, Nian Liu, Ming-Ming Cheng, Junwei Han
Previous knowledge distillation (KD) methods mostly focus on compressing network architectures, which is not thorough enough in deployment as some costs like transmission bandwidth and imaging equipment are related to the image size. Therefore, we propose Pixel Distillation that extends knowledge distillation into the input level while simultaneously breaking architecture constraints. Such a scheme can achieve flexible cost control for deployment, as it allows the system to adjust both network architecture and image quality according to the overall requirement of resources. Specifically, we first propose an input spatial representation distillation (ISRD) mechanism to transfer spatial knowledge from large images to student's input module, which can facilitate stable knowledge transfer between CNN and ViT. Then, a Teacher-Assistant-Student (TAS) framework is further established to disentangle pixel distillation into the model compression stage and input compression stage, which significantly reduces the overall complexity of pixel distillation and the difficulty of distilling intermediate knowledge. Finally, we adapt pixel distillation to object detection via an aligned feature for preservation (AFP) strategy for TAS, which aligns output dimensions of detectors at each stage by manipulating features and anchors of the assistant. Comprehensive experiments on image classification and object detection demonstrate the effectiveness of our method. Code is available at https://github.com/gyguo/PixelDistillation.
Read more7/11/2024
0
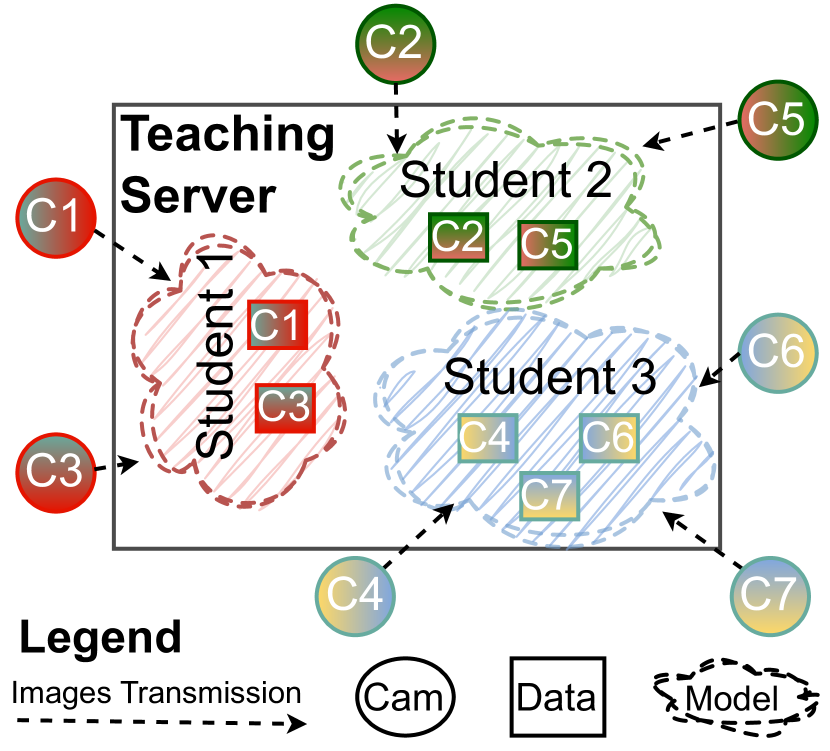
Camera clustering for scalable stream-based active distillation
Dani Manjah, Davide Cacciarelli, Christophe De Vleeschouwer, Benoit Macq
We present a scalable framework designed to craft efficient lightweight models for video object detection utilizing self-training and knowledge distillation techniques. We scrutinize methodologies for the ideal selection of training images from video streams and the efficacy of model sharing across numerous cameras. By advocating for a camera clustering methodology, we aim to diminish the requisite number of models for training while augmenting the distillation dataset. The findings affirm that proper camera clustering notably amplifies the accuracy of distilled models, eclipsing the methodologies that employ distinct models for each camera or a universal model trained on the aggregate camera data.
Read more4/17/2024