OccNeRF: Advancing 3D Occupancy Prediction in LiDAR-Free Environments

0

Sign in to get full access
Overview
- OccNeRF is a self-supervised approach for multi-camera occupancy prediction using neural radiance fields
- It learns a 3D occupancy representation from multi-view camera images without explicit 3D supervision
- The model can predict future occupancy and inpaint occluded regions in the scene
Plain English Explanation
OccNeRF: Self-Supervised Multi-Camera Occupancy Prediction with Neural Radiance Fields is a new technique that allows computers to understand the 3D structure of a scene by looking at images from multiple cameras.
Rather than requiring the computer to be explicitly shown a 3D model of the scene, OccNeRF can learn the 3D structure just by looking at the camera images. This is useful because building 3D models manually is time-consuming and expensive.
The key idea is to use a neural radiance field, which is a machine learning model that can represent the 3D structure of a scene in a very flexible and powerful way. OccNeRF builds on this by also learning to predict the occupancy of the 3D space - that is, where objects are located and how they might move over time.
This allows the system to not only understand the current 3D scene, but also predict how it might change in the future. It can also fill in missing information, like inferring what's behind occlusions in the camera views.
Overall, OccNeRF is an important step forward in enabling computers to build rich 3D representations of the world around them in a self-supervised way, without needing extensive manual labeling or modeling.
Technical Explanation
OccNeRF is a self-supervised approach for learning 3D occupancy prediction from multi-view camera images. It builds upon the neural radiance field (NeRF) representation, which can compactly encode the 3D structure of a scene.
The key insight of OccNeRF is to jointly learn both the static 3D radiance field and a dynamic 3D occupancy field from the multi-view camera observations. This allows the model to not only reconstruct the current scene, but also predict how the 3D occupancy will evolve over time.
The NeRF component of the model learns to represent the static 3D geometry and appearance of the scene. The occupancy component then models the dynamic 3D occupancy state, which can be used to predict future occupancy or fill in occluded regions.
The model is trained in a self-supervised manner, using only the multi-view camera observations without any explicit 3D supervision. This makes it more scalable and practical than approaches requiring dense 3D annotations.
Experiments demonstrate that OccNeRF can effectively predict future occupancy and inpaint occluded regions, outperforming prior methods for 3D occupancy forecasting. The authors also show that the learned occupancy representations are useful for downstream tasks like motion planning.
Critical Analysis
The OccNeRF paper presents a compelling approach for self-supervised 3D occupancy prediction, but there are some potential limitations and areas for further research:
- Scalability: While the self-supervised training is a strength, scaling the approach to large, complex scenes may still be challenging. The authors note the model has high memory and compute requirements.
- Handling Dynamics: The current occupancy prediction is limited to short-term forecasting. Extending the model to handle longer-term, more complex scene dynamics could be an interesting direction.
- Evaluation Metrics: The occupancy prediction is evaluated using proxy metrics like occupancy IoU. More direct evaluations of the model's utility for downstream tasks like motion planning could provide additional insights.
- Real-World Deployment: The experiments are conducted on synthetic datasets. Demonstrating the approach's performance on real-world multi-camera setups would help validate its practical applicability.
Overall, OccNeRF represents an important step forward in enabling computers to build rich 3D scene representations in a self-supervised manner. Addressing the limitations above could further enhance the model's capabilities and real-world impact.
Conclusion
OccNeRF introduces a novel self-supervised approach for learning 3D occupancy prediction from multi-view camera images. By combining neural radiance fields with dynamic occupancy modeling, the system can not only reconstruct the current 3D scene, but also forecast how the occupancy will change over time and inpaint occluded regions.
This advance in self-supervised 3D scene understanding has important implications for a wide range of applications, from autonomous navigation and robotics to AR/VR and urban planning. As the authors note, further research is needed to address scalability, long-term dynamics, and real-world deployment, but the core ideas of OccNeRF represent an exciting step forward in this rapidly progressing field.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
OccNeRF: Advancing 3D Occupancy Prediction in LiDAR-Free Environments
Chubin Zhang, Juncheng Yan, Yi Wei, Jiaxin Li, Li Liu, Yansong Tang, Yueqi Duan, Jiwen Lu
Occupancy prediction reconstructs 3D structures of surrounding environments. It provides detailed information for autonomous driving planning and navigation. However, most existing methods heavily rely on the LiDAR point clouds to generate occupancy ground truth, which is not available in the vision-based system. In this paper, we propose an OccNeRF method for training occupancy networks without 3D supervision. Different from previous works which consider a bounded scene, we parameterize the reconstructed occupancy fields and reorganize the sampling strategy to align with the cameras' infinite perceptive range. The neural rendering is adopted to convert occupancy fields to multi-camera depth maps, supervised by multi-frame photometric consistency. Moreover, for semantic occupancy prediction, we design several strategies to polish the prompts and filter the outputs of a pretrained open-vocabulary 2D segmentation model. Extensive experiments for both self-supervised depth estimation and 3D occupancy prediction tasks on nuScenes and SemanticKITTI datasets demonstrate the effectiveness of our method.
Read more8/22/2024

0
OccFusion: Depth Estimation Free Multi-sensor Fusion for 3D Occupancy Prediction
Ji Zhang, Yiran Ding, Zixin Liu
3D occupancy prediction based on multi-sensor fusion,crucial for a reliable autonomous driving system, enables fine-grained understanding of 3D scenes. Previous fusion-based 3D occupancy predictions relied on depth estimation for processing 2D image features. However, depth estimation is an ill-posed problem, hindering the accuracy and robustness of these methods. Furthermore, fine-grained occupancy prediction demands extensive computational resources. To address these issues, we propose OccFusion, a depth estimation free multi-modal fusion framework. Additionally, we introduce a generalizable active training method and an active decoder that can be applied to any occupancy prediction model, with the potential to enhance their performance. Experiments conducted on nuScenes-Occupancy and nuScenes-Occ3D demonstrate our framework's superior performance. Detailed ablation studies highlight the effectiveness of each proposed method.
Read more7/11/2024
0
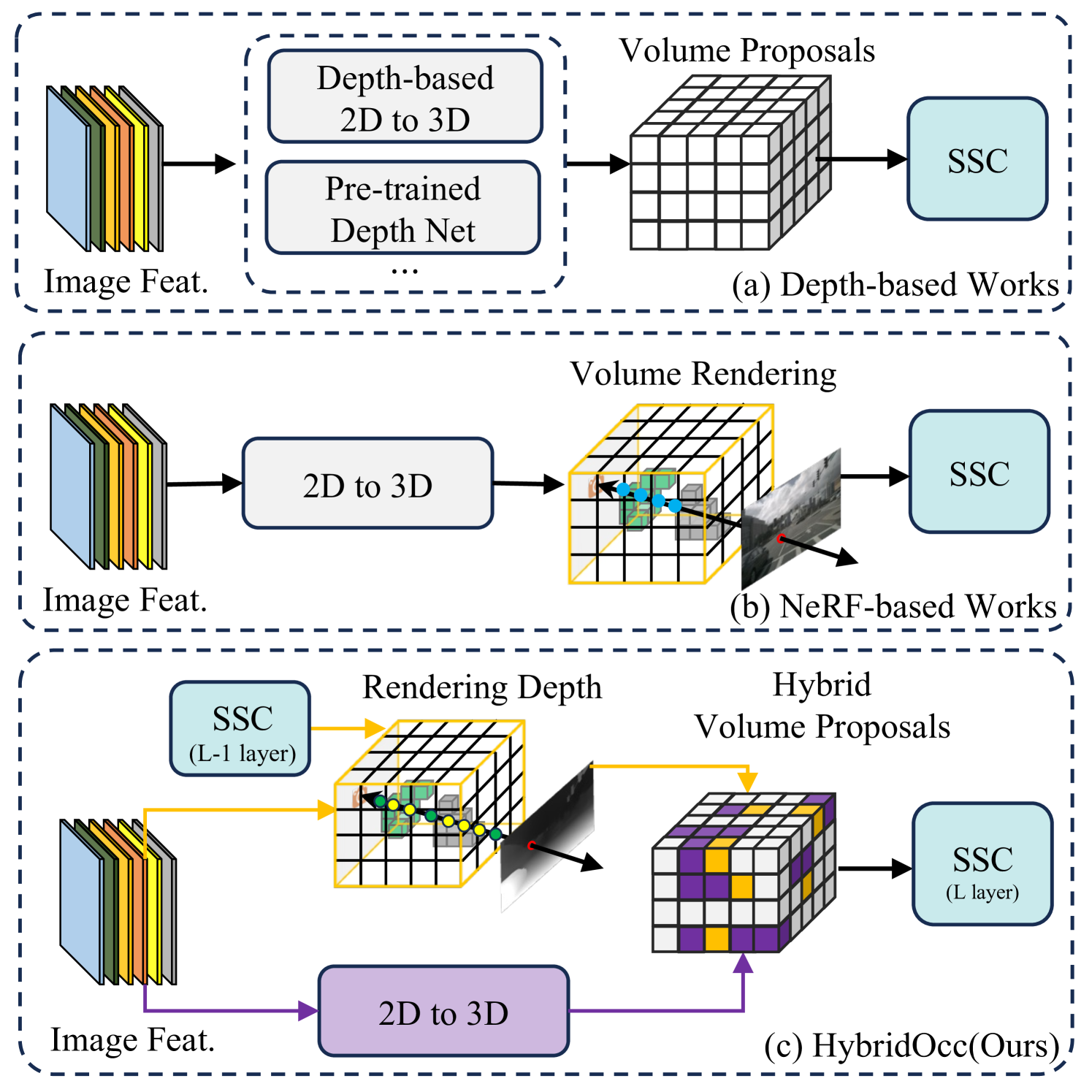
HybridOcc: NeRF Enhanced Transformer-based Multi-Camera 3D Occupancy Prediction
Xiao Zhao, Bo Chen, Mingyang Sun, Dingkang Yang, Youxing Wang, Xukun Zhang, Mingcheng Li, Dongliang Kou, Xiaoyi Wei, Lihua Zhang
Vision-based 3D semantic scene completion (SSC) describes autonomous driving scenes through 3D volume representations. However, the occlusion of invisible voxels by scene surfaces poses challenges to current SSC methods in hallucinating refined 3D geometry. This paper proposes HybridOcc, a hybrid 3D volume query proposal method generated by Transformer framework and NeRF representation and refined in a coarse-to-fine SSC prediction framework. HybridOcc aggregates contextual features through the Transformer paradigm based on hybrid query proposals while combining it with NeRF representation to obtain depth supervision. The Transformer branch contains multiple scales and uses spatial cross-attention for 2D to 3D transformation. The newly designed NeRF branch implicitly infers scene occupancy through volume rendering, including visible and invisible voxels, and explicitly captures scene depth rather than generating RGB color. Furthermore, we present an innovative occupancy-aware ray sampling method to orient the SSC task instead of focusing on the scene surface, further improving the overall performance. Extensive experiments on nuScenes and SemanticKITTI datasets demonstrate the effectiveness of our HybridOcc on the SSC task.
Read more8/20/2024

0
UnO: Unsupervised Occupancy Fields for Perception and Forecasting
Ben Agro, Quinlan Sykora, Sergio Casas, Thomas Gilles, Raquel Urtasun
Perceiving the world and forecasting its future state is a critical task for self-driving. Supervised approaches leverage annotated object labels to learn a model of the world -- traditionally with object detections and trajectory predictions, or temporal bird's-eye-view (BEV) occupancy fields. However, these annotations are expensive and typically limited to a set of predefined categories that do not cover everything we might encounter on the road. Instead, we learn to perceive and forecast a continuous 4D (spatio-temporal) occupancy field with self-supervision from LiDAR data. This unsupervised world model can be easily and effectively transferred to downstream tasks. We tackle point cloud forecasting by adding a lightweight learned renderer and achieve state-of-the-art performance in Argoverse 2, nuScenes, and KITTI. To further showcase its transferability, we fine-tune our model for BEV semantic occupancy forecasting and show that it outperforms the fully supervised state-of-the-art, especially when labeled data is scarce. Finally, when compared to prior state-of-the-art on spatio-temporal geometric occupancy prediction, our 4D world model achieves a much higher recall of objects from classes relevant to self-driving.
Read more6/14/2024