HybridOcc: NeRF Enhanced Transformer-based Multi-Camera 3D Occupancy Prediction

0
Sign in to get full access
Overview
- HybridOcc: NeRF Enhanced Transformer-based Multi-Camera 3D Occupancy Prediction
- Proposes a novel 3D occupancy prediction model that combines the strengths of NeRF and Transformer-based neural networks
- Aims to improve upon existing methods for 3D scene understanding, particularly in the context of autonomous driving
Plain English Explanation
HybridOcc is a new AI system that can create 3D models of the world around us, particularly useful for self-driving cars. It takes in multiple camera views and uses a combination of two powerful AI techniques - NeRF (Neural Radiance Fields) and Transformers - to predict the 3D occupancy of the scene.
The key idea is to leverage the strengths of both NeRF and Transformers. NeRF is great at modeling the 3D geometry and appearance of an environment, while Transformers excel at understanding the overall context and relationships within a scene. By combining these two approaches, HybridOcc can build more accurate and comprehensive 3D models that capture both the detailed structure and the high-level semantics of the environment.
This is important for self-driving cars and other autonomous systems that need to understand their surroundings in 3D in order to navigate safely and make informed decisions. The Co-OCC and OffBOARD systems also aim to improve 3D occupancy prediction for autonomous driving, but HybridOcc offers a novel hybrid approach that may yield better results.
Technical Explanation
The HybridOcc model consists of several key components:
- Multi-View Encoder: This encodes the input images from multiple cameras into a shared feature representation.
- NeRF-based Occupancy Decoder: This uses a NeRF-like architecture to predict the 3D occupancy of the scene based on the encoded features.
- Transformer-based Context Encoder: This takes the encoded features and uses a Transformer network to capture the high-level context and relationships in the scene.
- Fusion Module: The outputs of the NeRF-based decoder and Transformer-based encoder are combined to produce the final 3D occupancy prediction.
The researchers trained and evaluated HybridOcc on several 3D scene understanding benchmarks, including PanoSC and OpenOCC. The results show that HybridOcc outperforms previous state-of-the-art methods, demonstrating the benefits of its hybrid architecture.
Critical Analysis
The HybridOcc paper presents a compelling approach to 3D occupancy prediction, but there are a few potential limitations and areas for further research:
- The paper does not provide a thorough analysis of the computational and memory requirements of the HybridOcc model, which could be an important consideration for real-world deployment, especially in resource-constrained autonomous systems.
- While the results on existing benchmarks are promising, it would be valuable to see how HybridOcc performs in more realistic and diverse real-world environments, as well as its robustness to challenging conditions like occlusions, lighting changes, and sensor noise.
- The paper does not explore the potential to incorporate additional modalities, such as LiDAR or radar data, which could further enhance the 3D understanding capabilities of the system.
Overall, the HybridOcc research represents an interesting and potentially impactful contribution to the field of 3D scene understanding, but there are still opportunities to build upon this work and address some of the remaining challenges.
Conclusion
The HybridOcc model proposed in this paper represents a novel approach to 3D occupancy prediction that combines the strengths of NeRF and Transformer-based neural networks. By leveraging both detailed 3D geometry and high-level context, HybridOcc demonstrates superior performance on 3D scene understanding benchmarks compared to previous methods.
This work has significant implications for autonomous driving and other applications that require accurate and comprehensive 3D models of the environment. While the current research shows promise, there are still opportunities to further refine and expand the HybridOcc approach to address remaining challenges and unlock its full potential for real-world deployment.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
HybridOcc: NeRF Enhanced Transformer-based Multi-Camera 3D Occupancy Prediction
Xiao Zhao, Bo Chen, Mingyang Sun, Dingkang Yang, Youxing Wang, Xukun Zhang, Mingcheng Li, Dongliang Kou, Xiaoyi Wei, Lihua Zhang
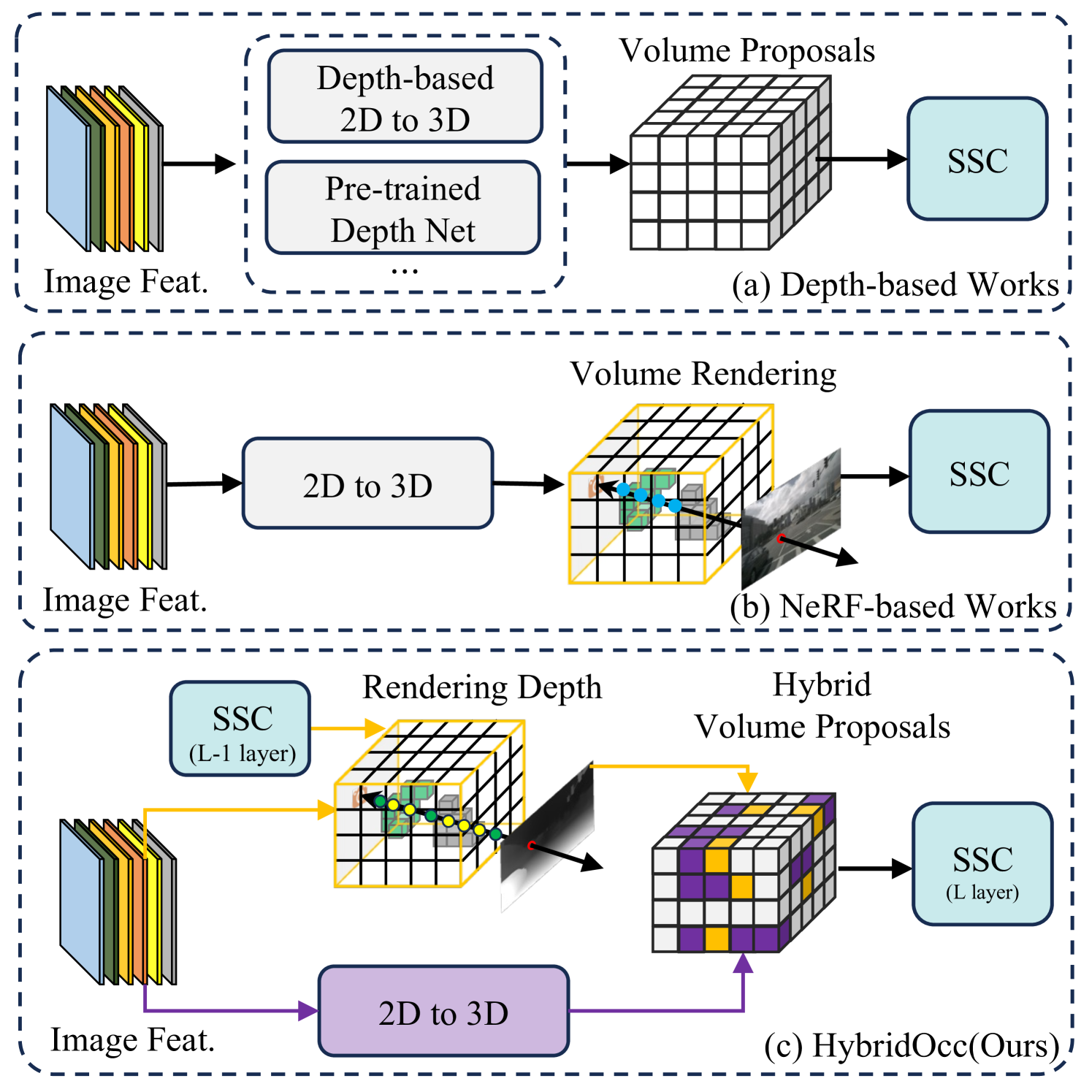
Vision-based 3D semantic scene completion (SSC) describes autonomous driving scenes through 3D volume representations. However, the occlusion of invisible voxels by scene surfaces poses challenges to current SSC methods in hallucinating refined 3D geometry. This paper proposes HybridOcc, a hybrid 3D volume query proposal method generated by Transformer framework and NeRF representation and refined in a coarse-to-fine SSC prediction framework. HybridOcc aggregates contextual features through the Transformer paradigm based on hybrid query proposals while combining it with NeRF representation to obtain depth supervision. The Transformer branch contains multiple scales and uses spatial cross-attention for 2D to 3D transformation. The newly designed NeRF branch implicitly infers scene occupancy through volume rendering, including visible and invisible voxels, and explicitly captures scene depth rather than generating RGB color. Furthermore, we present an innovative occupancy-aware ray sampling method to orient the SSC task instead of focusing on the scene surface, further improving the overall performance. Extensive experiments on nuScenes and SemanticKITTI datasets demonstrate the effectiveness of our HybridOcc on the SSC task.
Read more8/20/2024

0
GEOcc: Geometrically Enhanced 3D Occupancy Network with Implicit-Explicit Depth Fusion and Contextual Self-Supervision
Xin Tan, Wenbin Wu, Zhiwei Zhang, Chaojie Fan, Yong Peng, Zhizhong Zhang, Yuan Xie, Lizhuang Ma
3D occupancy perception holds a pivotal role in recent vision-centric autonomous driving systems by converting surround-view images into integrated geometric and semantic representations within dense 3D grids. Nevertheless, current models still encounter two main challenges: modeling depth accurately in the 2D-3D view transformation stage, and overcoming the lack of generalizability issues due to sparse LiDAR supervision. To address these issues, this paper presents GEOcc, a Geometric-Enhanced Occupancy network tailored for vision-only surround-view perception. Our approach is three-fold: 1) Integration of explicit lift-based depth prediction and implicit projection-based transformers for depth modeling, enhancing the density and robustness of view transformation. 2) Utilization of mask-based encoder-decoder architecture for fine-grained semantic predictions; 3) Adoption of context-aware self-training loss functions in the pertaining stage to complement LiDAR supervision, involving the re-rendering of 2D depth maps from 3D occupancy features and leveraging image reconstruction loss to obtain denser depth supervision besides sparse LiDAR ground-truths. Our approach achieves State-Of-The-Art performance on the Occ3D-nuScenes dataset with the least image resolution needed and the most weightless image backbone compared with current models, marking an improvement of 3.3% due to our proposed contributions. Comprehensive experimentation also demonstrates the consistent superiority of our method over baselines and alternative approaches.
Read more5/20/2024

0
Co-Occ: Coupling Explicit Feature Fusion with Volume Rendering Regularization for Multi-Modal 3D Semantic Occupancy Prediction
Jingyi Pan, Zipeng Wang, Lin Wang
3D semantic occupancy prediction is a pivotal task in the field of autonomous driving. Recent approaches have made great advances in 3D semantic occupancy predictions on a single modality. However, multi-modal semantic occupancy prediction approaches have encountered difficulties in dealing with the modality heterogeneity, modality misalignment, and insufficient modality interactions that arise during the fusion of different modalities data, which may result in the loss of important geometric and semantic information. This letter presents a novel multi-modal, i.e., LiDAR-camera 3D semantic occupancy prediction framework, dubbed Co-Occ, which couples explicit LiDAR-camera feature fusion with implicit volume rendering regularization. The key insight is that volume rendering in the feature space can proficiently bridge the gap between 3D LiDAR sweeps and 2D images while serving as a physical regularization to enhance LiDAR-camera fused volumetric representation. Specifically, we first propose a Geometric- and Semantic-aware Fusion (GSFusion) module to explicitly enhance LiDAR features by incorporating neighboring camera features through a K-nearest neighbors (KNN) search. Then, we employ volume rendering to project the fused feature back to the image planes for reconstructing color and depth maps. These maps are then supervised by input images from the camera and depth estimations derived from LiDAR, respectively. Extensive experiments on the popular nuScenes and SemanticKITTI benchmarks verify the effectiveness of our Co-Occ for 3D semantic occupancy prediction. The project page is available at https://rorisis.github.io/Co-Occ_project-page/.
Read more5/24/2024

0
OccNeRF: Advancing 3D Occupancy Prediction in LiDAR-Free Environments
Chubin Zhang, Juncheng Yan, Yi Wei, Jiaxin Li, Li Liu, Yansong Tang, Yueqi Duan, Jiwen Lu
Occupancy prediction reconstructs 3D structures of surrounding environments. It provides detailed information for autonomous driving planning and navigation. However, most existing methods heavily rely on the LiDAR point clouds to generate occupancy ground truth, which is not available in the vision-based system. In this paper, we propose an OccNeRF method for training occupancy networks without 3D supervision. Different from previous works which consider a bounded scene, we parameterize the reconstructed occupancy fields and reorganize the sampling strategy to align with the cameras' infinite perceptive range. The neural rendering is adopted to convert occupancy fields to multi-camera depth maps, supervised by multi-frame photometric consistency. Moreover, for semantic occupancy prediction, we design several strategies to polish the prompts and filter the outputs of a pretrained open-vocabulary 2D segmentation model. Extensive experiments for both self-supervised depth estimation and 3D occupancy prediction tasks on nuScenes and SemanticKITTI datasets demonstrate the effectiveness of our method.
Read more8/22/2024