Offline Diversity Maximization Under Imitation Constraints
2307.11373
0
0
👨🏫
Abstract
There has been significant recent progress in the area of unsupervised skill discovery, utilizing various information-theoretic objectives as measures of diversity. Despite these advances, challenges remain: current methods require significant online interaction, fail to leverage vast amounts of available task-agnostic data and typically lack a quantitative measure of skill utility. We address these challenges by proposing a principled offline algorithm for unsupervised skill discovery that, in addition to maximizing diversity, ensures that each learned skill imitates state-only expert demonstrations to a certain degree. Our main analytical contribution is to connect Fenchel duality, reinforcement learning, and unsupervised skill discovery to maximize a mutual information objective subject to KL-divergence state occupancy constraints. Furthermore, we demonstrate the effectiveness of our method on the standard offline benchmark D4RL and on a custom offline dataset collected from a 12-DoF quadruped robot for which the policies trained in simulation transfer well to the real robotic system.
Create account to get full access
Overview
- Recent progress in unsupervised skill discovery using information-theoretic objectives
- Remaining challenges: high online interaction, lack of leveraging task-agnostic data, and lack of quantitative skill utility measure
- Proposed solution: Offline algorithm that maximizes diversity while ensuring learned skills imitate expert demonstrations
Plain English Explanation
In the field of machine learning, researchers have made significant progress in developing unsupervised skill discovery techniques. These methods use information-theoretic objectives, such as mutual information, to identify a diverse set of skills that an agent can learn without supervision.
Despite these advancements, there are still some challenges that need to be addressed. Current methods require a lot of interaction with the environment during the learning process, which can be time-consuming and impractical in many real-world scenarios. Additionally, these methods often fail to leverage the vast amounts of task-agnostic data that may be available, and they typically lack a quantitative measure of how useful the learned skills are.
To address these challenges, the researchers propose a new offline algorithm for unsupervised skill discovery. This algorithm not only maximizes the diversity of the learned skills but also ensures that each skill imitates expert demonstrations to a certain degree. By incorporating this constraint, the algorithm can produce skills that are both diverse and aligned with demonstrations of high-quality behavior.
The key technical contribution of this work is to connect several mathematical concepts, including Fenchel duality, reinforcement learning, and unsupervised skill discovery, to optimize a mutual information objective subject to constraints on the divergence between the learned skill policies and the expert demonstrations.
The researchers demonstrate the effectiveness of their method on standard offline benchmarks, as well as on a custom dataset collected from a 12-degree-of-freedom quadruped robot. The policies trained in simulation are shown to transfer well to the real robotic system, highlighting the practical applications of this approach.
Technical Explanation
The researchers propose a new offline algorithm for unsupervised skill discovery that aims to address the limitations of existing methods. The core idea is to maximize a mutual information objective, which measures the diversity of the learned skills, subject to constraints on the Kullback-Leibler (KL) divergence between the learned skill policies and expert demonstrations.
Mathematically, the algorithm seeks to solve the following optimization problem:
maximize mutual information(skills, observations) subject to KL-divergence(skills, expert demonstrations) ≤ some constant
By incorporating the KL-divergence constraint, the algorithm ensures that each learned skill imitates the expert demonstrations to a certain degree, while still maintaining diversity.
The researchers connect this optimization problem to Fenchel duality, a powerful mathematical framework, to develop an efficient algorithm for solving it. They show that this approach can be interpreted as a form of constrained reinforcement learning, where the goal is to learn a diverse set of policies that balance both behavioral quality and diversity.
The effectiveness of the proposed method is evaluated on the standard D4RL offline benchmark, as well as on a custom dataset collected from a 12-DoF quadruped robot. The results demonstrate that the learned skills not only exhibit high diversity but also transfer well to the real robotic system, outperforming baseline methods.
Critical Analysis
The researchers have addressed several important challenges in the field of unsupervised skill discovery, and their proposed algorithm represents a significant advancement. However, there are a few potential limitations and areas for further research that are worth considering.
One concern is the reliance on expert demonstrations, which may not always be available or easily obtained in real-world scenarios. While the KL-divergence constraint helps ensure the learned skills imitate the expert behavior, it would be valuable to explore ways to relax this requirement or incorporate additional sources of information, such as task-agnostic data, to further improve the method's applicability.
Additionally, the researchers mention that their algorithm requires solving a complex optimization problem, which may be computationally expensive, especially for large-scale problems. Exploring more efficient optimization strategies or approximation techniques could help make the method more scalable and practical.
Finally, while the researchers demonstrate the effectiveness of their method on specific benchmarks and a custom robotics dataset, it would be valuable to see the algorithm evaluated on a broader range of tasks and environments to better understand its generalization capabilities and limitations.
Conclusion
The proposed offline algorithm for unsupervised skill discovery represents an important step forward in addressing key challenges in this field. By leveraging Fenchel duality, reinforcement learning, and a mutual information objective with KL-divergence constraints, the researchers have developed a principled approach that can learn a diverse set of skills while ensuring they imitate expert demonstrations to a certain degree.
The demonstrated success on both standard benchmarks and a real-world robotic dataset suggests that this method has the potential to significantly impact the development of more versatile and capable AI systems. As the field of unsupervised skill discovery continues to evolve, further research exploring ways to relax the reliance on expert data and improve computational efficiency could further enhance the practical applicability of this approach.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Balancing Both Behavioral Quality and Diversity in Unsupervised Skill Discovery
Xin Liu, Yaran Chen, Dongbin Zhao
0
0
This work has been submitted to the IEEE for possible publication. Copyright may be transferred without notice, after which this version may no longer be accessible. Unsupervised skill discovery seeks to dig out diverse and exploratory skills without extrinsic reward, with the discovered skills efficiently adapting to multiple downstream tasks in various ways. However, recent advanced methods struggle to well balance behavioral exploration and diversity, particularly when the agent dynamics are complex and potential skills are hard to discern (e.g., robot behavior discovery). In this paper, we propose textbf{Co}ntrastive textbf{m}ulti-objective textbf{S}kill textbf{D}iscovery textbf{(ComSD)} which discovers exploratory and diverse behaviors through a novel intrinsic incentive, named contrastive multi-objective reward. It contains a novel diversity reward based on contrastive learning to effectively drive agents to discern existing skills, and a particle-based exploration reward to access and learn new behaviors. Moreover, a novel dynamic weighting mechanism between the above two rewards is proposed for diversity-exploration balance, which further improves behavioral quality. Extensive experiments and analysis demonstrate that ComSD can generate diverse behaviors at different exploratory levels for complex multi-joint robots, enabling state-of-the-art performance across 32 challenging downstream adaptation tasks, which recent advanced methods cannot. Codes will be opened after publication.
5/21/2024

Constrained Ensemble Exploration for Unsupervised Skill Discovery
Chenjia Bai, Rushuai Yang, Qiaosheng Zhang, Kang Xu, Yi Chen, Ting Xiao, Xuelong Li
0
0
Unsupervised Reinforcement Learning (RL) provides a promising paradigm for learning useful behaviors via reward-free per-training. Existing methods for unsupervised RL mainly conduct empowerment-driven skill discovery or entropy-based exploration. However, empowerment often leads to static skills, and pure exploration only maximizes the state coverage rather than learning useful behaviors. In this paper, we propose a novel unsupervised RL framework via an ensemble of skills, where each skill performs partition exploration based on the state prototypes. Thus, each skill can explore the clustered area locally, and the ensemble skills maximize the overall state coverage. We adopt state-distribution constraints for the skill occupancy and the desired cluster for learning distinguishable skills. Theoretical analysis is provided for the state entropy and the resulting skill distributions. Based on extensive experiments on several challenging tasks, we find our method learns well-explored ensemble skills and achieves superior performance in various downstream tasks compared to previous methods.
5/28/2024

How to Leverage Diverse Demonstrations in Offline Imitation Learning
Sheng Yue, Jiani Liu, Xingyuan Hua, Ju Ren, Sen Lin, Junshan Zhang, Yaoxue Zhang
0
0
Offline Imitation Learning (IL) with imperfect demonstrations has garnered increasing attention owing to the scarcity of expert data in many real-world domains. A fundamental problem in this scenario is how to extract positive behaviors from noisy data. In general, current approaches to the problem select data building on state-action similarity to given expert demonstrations, neglecting precious information in (potentially abundant) $textit{diverse}$ state-actions that deviate from expert ones. In this paper, we introduce a simple yet effective data selection method that identifies positive behaviors based on their resultant states -- a more informative criterion enabling explicit utilization of dynamics information and effective extraction of both expert and beneficial diverse behaviors. Further, we devise a lightweight behavior cloning algorithm capable of leveraging the expert and selected data correctly. In the experiments, we evaluate our method on a suite of complex and high-dimensional offline IL benchmarks, including continuous-control and vision-based tasks. The results demonstrate that our method achieves state-of-the-art performance, outperforming existing methods on $textbf{20/21}$ benchmarks, typically by $textbf{2-5x}$, while maintaining a comparable runtime to Behavior Cloning ($texttt{BC}$).
5/31/2024
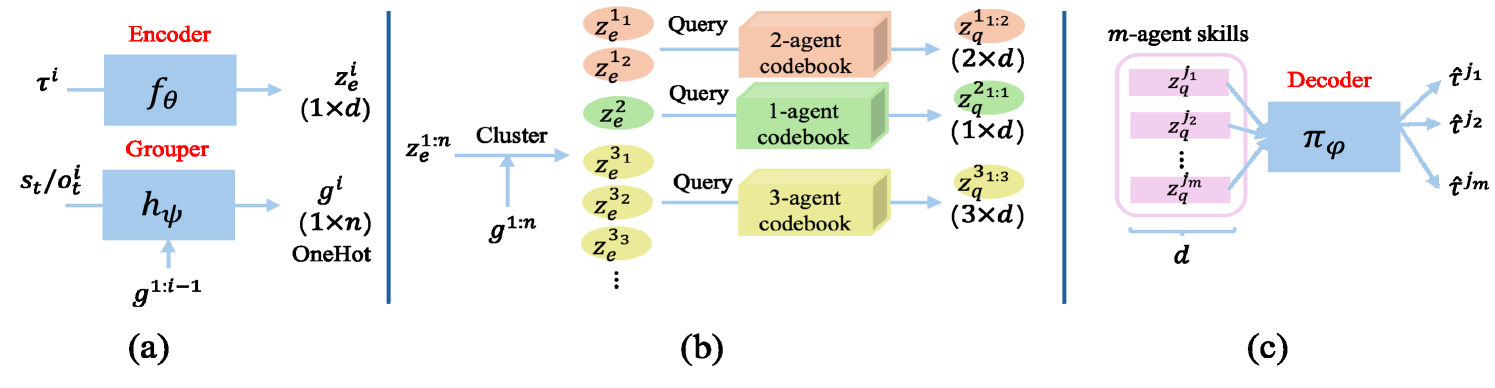
Variational Offline Multi-agent Skill Discovery
Jiayu Chen, Bhargav Ganguly, Tian Lan, Vaneet Aggarwal
0
0
Skills are effective temporal abstractions established for sequential decision making tasks, which enable efficient hierarchical learning for long-horizon tasks and facilitate multi-task learning through their transferability. Despite extensive research, research gaps remain in multi-agent scenarios, particularly for automatically extracting subgroup coordination patterns in a multi-agent task. In this case, we propose two novel auto-encoder schemes: VO-MASD-3D and VO-MASD-Hier, to simultaneously capture subgroup- and temporal-level abstractions and form multi-agent skills, which firstly solves the aforementioned challenge. An essential algorithm component of these schemes is a dynamic grouping function that can automatically detect latent subgroups based on agent interactions in a task. Notably, our method can be applied to offline multi-task data, and the discovered subgroup skills can be transferred across relevant tasks without retraining. Empirical evaluations on StarCraft tasks indicate that our approach significantly outperforms existing methods regarding applying skills in multi-agent reinforcement learning (MARL). Moreover, skills discovered using our method can effectively reduce the learning difficulty in MARL scenarios with delayed and sparse reward signals.
5/28/2024