Constrained Ensemble Exploration for Unsupervised Skill Discovery
2405.16030
0
0

Abstract
Unsupervised Reinforcement Learning (RL) provides a promising paradigm for learning useful behaviors via reward-free per-training. Existing methods for unsupervised RL mainly conduct empowerment-driven skill discovery or entropy-based exploration. However, empowerment often leads to static skills, and pure exploration only maximizes the state coverage rather than learning useful behaviors. In this paper, we propose a novel unsupervised RL framework via an ensemble of skills, where each skill performs partition exploration based on the state prototypes. Thus, each skill can explore the clustered area locally, and the ensemble skills maximize the overall state coverage. We adopt state-distribution constraints for the skill occupancy and the desired cluster for learning distinguishable skills. Theoretical analysis is provided for the state entropy and the resulting skill distributions. Based on extensive experiments on several challenging tasks, we find our method learns well-explored ensemble skills and achieves superior performance in various downstream tasks compared to previous methods.
Create account to get full access
Overview
• This paper introduces a new method called Constrained Ensemble Exploration (CEE) for unsupervised skill discovery in reinforcement learning (RL) environments.
• The key idea is to encourage the agent to explore a diverse set of skills or behaviors by constraining the ensemble of policies to maintain high entropy, while also optimizing for task performance.
• The authors demonstrate that CEE can outperform existing techniques for unsupervised skill discovery and intrinsic motivation on a range of complex environments.
Plain English Explanation
The paper proposes a new way for reinforcement learning agents to discover useful skills on their own, without being directly told what to do. The key insight is to encourage the agent to explore a wide variety of behaviors, while also optimizing for good performance on the overall task.
The method works by training an ensemble of policies, which are different ways the agent can behave. The key innovation is to add a constraint that keeps the ensemble diverse - the policies must maintain high "entropy," meaning they cover a wide range of possible behaviors. This diversity encourages the agent to explore and discover new skills, rather than converging on a single narrow strategy.
At the same time, the agent is still rewarded for good performance on the overall task. So the method balances exploration of new skills with optimization for the task at hand. The authors show this approach outperforms other methods for unsupervised skill discovery and intrinsic motivation on complex environments.
Technical Explanation
The paper introduces Constrained Ensemble Exploration (CEE), a novel method for unsupervised skill discovery in reinforcement learning. The key idea is to train an ensemble of policies that maintain high entropy, or diversity, while also optimizing for task performance.
Specifically, CEE trains a policy ensemble using the following objective:
max Σ reward - λ Σ entropy(πi)
Where πi are the individual policies in the ensemble, and λ is a hyperparameter controlling the trade-off between task performance and policy diversity.
The high-entropy constraint encourages the ensemble to cover a wide range of behaviors, rather than converging to a single narrow strategy. This in turn allows the agent to discover a diverse set of skills through exploration, without requiring any external reward signals or demonstrations.
The authors evaluate CEE on a suite of continuous control environments, comparing to prior methods for unsupervised skill discovery and intrinsic motivation. The results show that CEE can outperform these baselines on both skill discovery and overall task performance.
Critical Analysis
The paper presents a promising new approach for unsupervised skill discovery in RL, with strong empirical results. However, there are a few potential limitations and areas for further research:
-
The authors only evaluate CEE on continuous control tasks, but it's unclear how well the method would scale to more complex environments with higher-dimensional state and action spaces.
-
The hyperparameter
λcontrolling the exploration-exploitation trade-off may require careful tuning for different environments. More principled ways of adapting this trade-off automatically could be investigated. -
The paper does not deeply explore the types of skills discovered by CEE, or how they compare to skills found by other methods like goal exploration or surprise-based intrinsic motivation. A more detailed analysis of the learned skills could provide additional insights.
-
While CEE outperforms prior methods on skill discovery and overall task performance, it's unclear how it would fare in more imbalanced or offline RL settings where the agent has limited data or exploration capabilities.
Overall, the Constrained Ensemble Exploration approach is a promising direction for unsupervised skill discovery, but further research is needed to fully understand its strengths, limitations, and potential applications.
Conclusion
This paper introduces Constrained Ensemble Exploration (CEE), a novel method for unsupervised skill discovery in reinforcement learning. The key idea is to train an ensemble of policies that maintain high entropy, or diversity, while also optimizing for task performance.
The authors show that CEE can outperform existing techniques for unsupervised skill discovery and intrinsic motivation on a range of complex environments. This suggests CEE is a promising approach for enabling RL agents to autonomously discover a diverse set of useful skills, without relying on external reward signals or demonstrations.
While the paper presents compelling results, there are still open questions and potential limitations that warrant further investigation. Exploring the scalability of CEE, its performance in more challenging RL settings, and a deeper analysis of the discovered skills could all be fruitful areas for future research.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
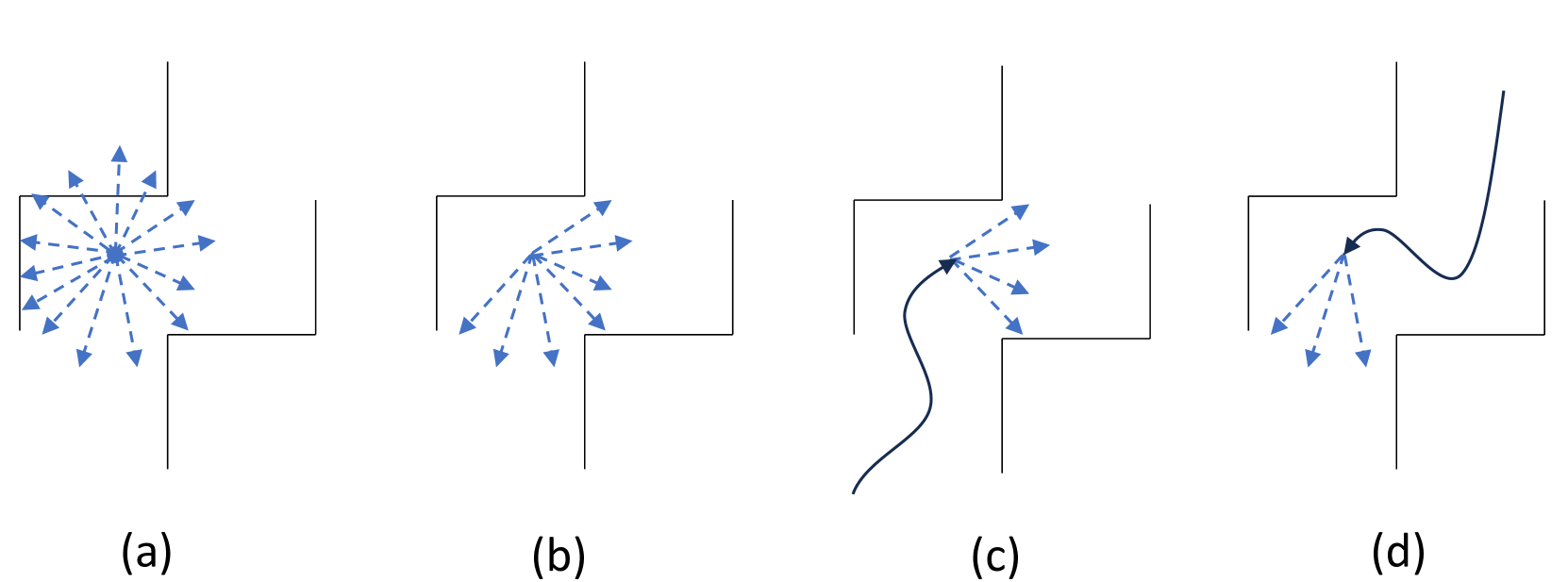
Goal Exploration via Adaptive Skill Distribution for Goal-Conditioned Reinforcement Learning
Lisheng Wu, Ke Chen
0
0
Exploration efficiency poses a significant challenge in goal-conditioned reinforcement learning (GCRL) tasks, particularly those with long horizons and sparse rewards. A primary limitation to exploration efficiency is the agent's inability to leverage environmental structural patterns. In this study, we introduce a novel framework, GEASD, designed to capture these patterns through an adaptive skill distribution during the learning process. This distribution optimizes the local entropy of achieved goals within a contextual horizon, enhancing goal-spreading behaviors and facilitating deep exploration in states containing familiar structural patterns. Our experiments reveal marked improvements in exploration efficiency using the adaptive skill distribution compared to a uniform skill distribution. Additionally, the learned skill distribution demonstrates robust generalization capabilities, achieving substantial exploration progress in unseen tasks containing similar local structures.
4/22/2024
👨🏫
Offline Diversity Maximization Under Imitation Constraints
Marin Vlastelica, Jin Cheng, Georg Martius, Pavel Kolev
0
0
There has been significant recent progress in the area of unsupervised skill discovery, utilizing various information-theoretic objectives as measures of diversity. Despite these advances, challenges remain: current methods require significant online interaction, fail to leverage vast amounts of available task-agnostic data and typically lack a quantitative measure of skill utility. We address these challenges by proposing a principled offline algorithm for unsupervised skill discovery that, in addition to maximizing diversity, ensures that each learned skill imitates state-only expert demonstrations to a certain degree. Our main analytical contribution is to connect Fenchel duality, reinforcement learning, and unsupervised skill discovery to maximize a mutual information objective subject to KL-divergence state occupancy constraints. Furthermore, we demonstrate the effectiveness of our method on the standard offline benchmark D4RL and on a custom offline dataset collected from a 12-DoF quadruped robot for which the policies trained in simulation transfer well to the real robotic system.
6/24/2024
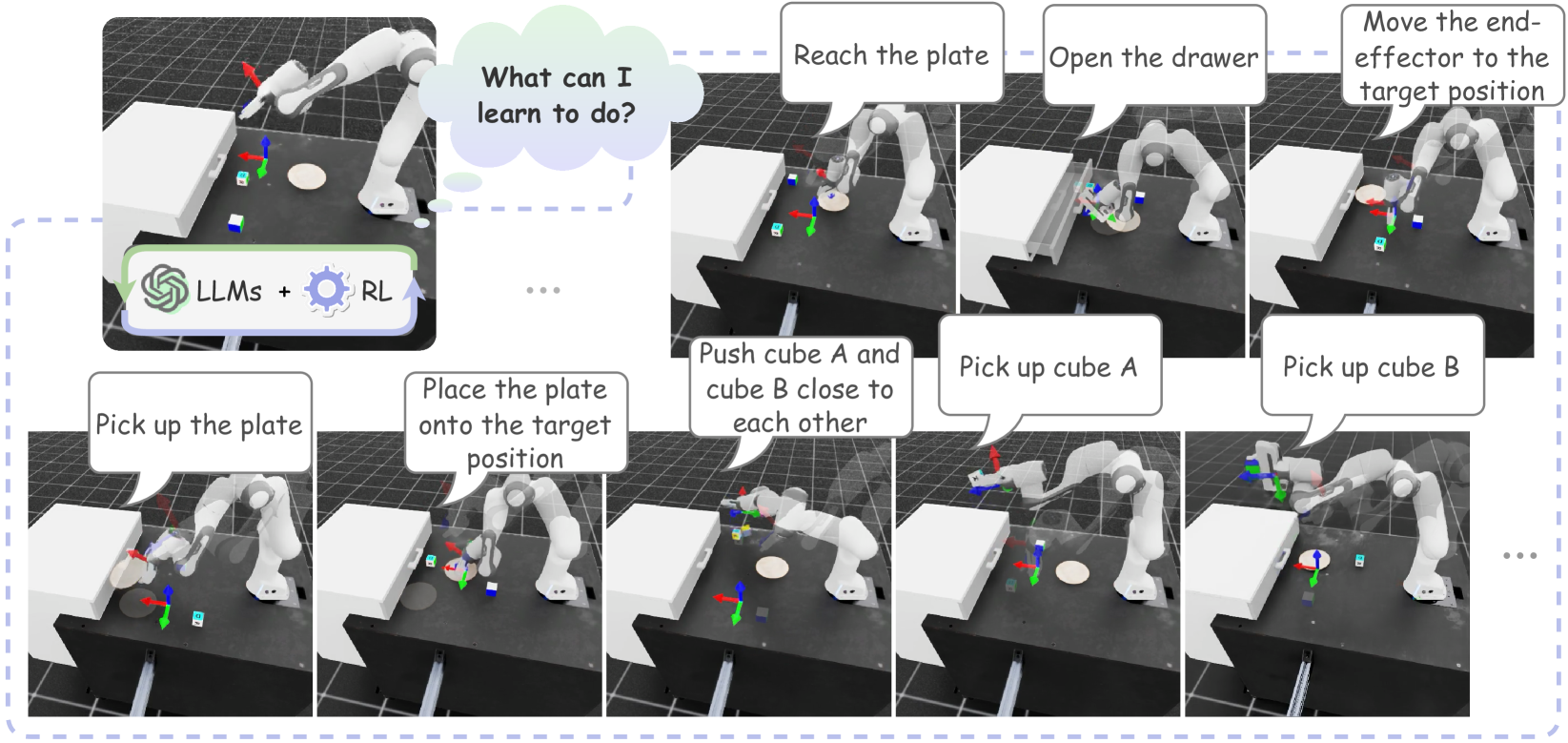
Agentic Skill Discovery
Xufeng Zhao, Cornelius Weber, Stefan Wermter
0
0
Language-conditioned robotic skills make it possible to apply the high-level reasoning of Large Language Models (LLMs) to low-level robotic control. A remaining challenge is to acquire a diverse set of fundamental skills. Existing approaches either manually decompose a complex task into atomic robotic actions in a top-down fashion, or bootstrap as many combinations as possible in a bottom-up fashion to cover a wider range of task possibilities. These decompositions or combinations, however, require an initial skill library. For example, a grasping capability can never emerge from a skill library containing only diverse pushing skills. Existing skill discovery techniques with reinforcement learning acquire skills by an exhaustive exploration but often yield non-meaningful behaviors. In this study, we introduce a novel framework for skill discovery that is entirely driven by LLMs. The framework begins with an LLM generating task proposals based on the provided scene description and the robot's configurations, aiming to incrementally acquire new skills upon task completion. For each proposed task, a series of reinforcement learning processes are initiated, utilizing reward and success determination functions sampled by the LLM to develop the corresponding policy. The reliability and trustworthiness of learned behaviors are further ensured by an independent vision-language model. We show that starting with zero skill, the ASD skill library emerges and expands to more and more meaningful and reliable skills, enabling the robot to efficiently further propose and complete advanced tasks. The project page can be found at: https://agentic-skill-discovery.github.io.
5/27/2024

Surprise-Adaptive Intrinsic Motivation for Unsupervised Reinforcement Learning
Adriana Hugessen, Roger Creus Castanyer, Faisal Mohamed, Glen Berseth
0
0
Both entropy-minimizing and entropy-maximizing (curiosity) objectives for unsupervised reinforcement learning (RL) have been shown to be effective in different environments, depending on the environment's level of natural entropy. However, neither method alone results in an agent that will consistently learn intelligent behavior across environments. In an effort to find a single entropy-based method that will encourage emergent behaviors in any environment, we propose an agent that can adapt its objective online, depending on the entropy conditions by framing the choice as a multi-armed bandit problem. We devise a novel intrinsic feedback signal for the bandit, which captures the agent's ability to control the entropy in its environment. We demonstrate that such agents can learn to control entropy and exhibit emergent behaviors in both high- and low-entropy regimes and can learn skillful behaviors in benchmark tasks. Videos of the trained agents and summarized findings can be found on our project page https://sites.google.com/view/surprise-adaptive-agents
5/28/2024