Offline Oracle-Efficient Learning for Contextual MDPs via Layerwise Exploration-Exploitation Tradeoff

0
🏅
Sign in to get full access
Overview
- The paper proposes a new algorithm for efficient offline learning in contextual Markov Decision Processes (MDPs).
- It introduces a layerwise exploration-exploitation tradeoff to balance learning the transition function and learning the reward function.
- The algorithm is shown to be "oracle-efficient," meaning it can match the performance of an ideal learner with perfect knowledge.
Plain English Explanation
The paper tackles the challenge of learning in contextual MDPs in an offline setting, where the agent does not actively interact with the environment but instead learns from a fixed dataset. The key idea is to split the learning process into different "layers" that focus on learning the transition function (how the environment evolves) and the reward function (what the agent should optimize for) separately, rather than trying to learn both simultaneously.
By adjusting the tradeoff between exploring the environment to learn the transition function and exploiting the current reward function knowledge, the algorithm can efficiently learn a near-optimal policy without requiring the agent to actively interact with the environment. This "layerwise exploration-exploitation tradeoff" allows the algorithm to match the performance of an "ideal learner" who has perfect knowledge of the MDP, making it "oracle-efficient."
Technical Explanation
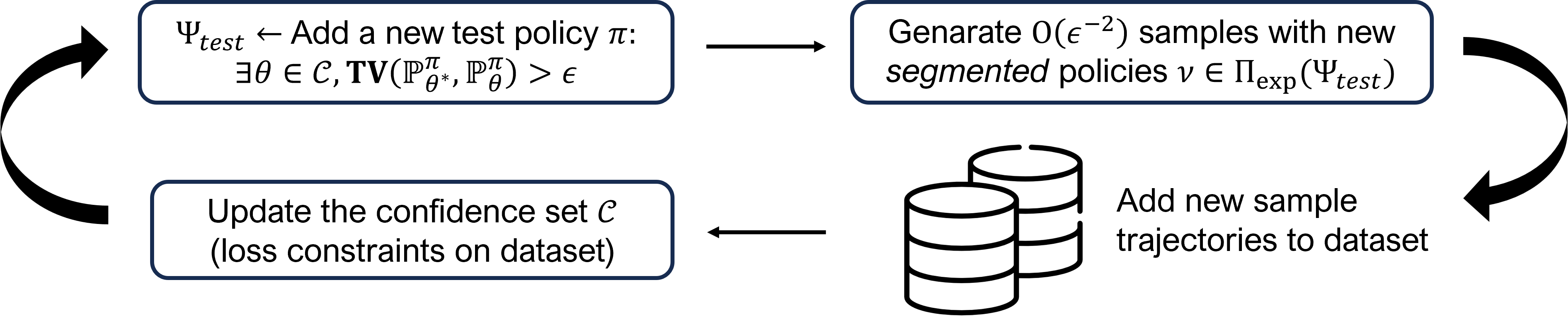
The paper formulates the contextual MDP learning problem and proposes a new algorithm called "Offline Oracle-Efficient Learning" (OOEL) to solve it. OOEL works by alternating between two phases: a transition learning phase that focuses on estimating the environment's transition dynamics, and a reward learning phase that focuses on optimizing the agent's policy based on the current reward function estimate.
The key technical innovation is the layerwise exploration-exploitation tradeoff, where the algorithm dynamically adjusts the balance between exploration (learning the transition function) and exploitation (optimizing the policy) at each layer of the learning process. This allows OOEL to efficiently learn a near-optimal policy while avoiding the need for active interaction with the environment, as would be required in a traditional reinforcement learning setting.
The paper provides theoretical analysis to show that OOEL is "oracle-efficient," meaning its performance matches that of an ideal learner with perfect knowledge of the MDP. This is achieved by carefully managing the exploration-exploitation tradeoff and leveraging techniques like approximate dynamic programming and minimax optimization.
Critical Analysis
The paper makes a compelling contribution to the field of offline reinforcement learning, addressing an important practical problem of learning in contextual MDPs without the need for active interaction with the environment. The layerwise exploration-exploitation tradeoff is a novel and promising approach that could have broader applicability beyond the specific OOEL algorithm.
However, the paper does not address some potential limitations and areas for further research. For example, the analysis assumes the transition and reward functions are Lipschitz continuous, which may not hold in all real-world scenarios. Additionally, the computational complexity of the OOEL algorithm, while polynomial in the relevant parameters, could still be prohibitive for large-scale problems.
Future work could explore ways to relax the assumptions, improve the computational efficiency, or extend the ideas to other offline RL settings, such as partially observable or multi-agent environments. Incorporating additional practical considerations, like robustness to distribution shift or safety constraints, could also enhance the real-world applicability of the approach.
Conclusion
The "Offline Oracle-Efficient Learning for Contextual MDPs via Layerwise Exploration-Exploitation Tradeoff" paper presents a novel algorithm that can efficiently learn near-optimal policies in contextual MDPs using only offline data, without the need for active interaction with the environment. By cleverly balancing the exploration of the transition function and the exploitation of the reward function, the algorithm can match the performance of an ideal learner with perfect knowledge of the MDP.
This work represents an important step forward in the field of offline reinforcement learning, with potential applications in domains where interactive learning is infeasible or undesirable, such as healthcare, finance, or robotics. While the approach has some limitations, the core ideas and techniques could inspire further research to expand the capabilities and applicability of offline RL algorithms.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🏅
0
Offline Oracle-Efficient Learning for Contextual MDPs via Layerwise Exploration-Exploitation Tradeoff
Jian Qian, Haichen Hu, David Simchi-Levi
Motivated by the recent discovery of a statistical and computational reduction from contextual bandits to offline regression (Simchi-Levi and Xu, 2021), we address the general (stochastic) Contextual Markov Decision Process (CMDP) problem with horizon H (as known as CMDP with H layers). In this paper, we introduce a reduction from CMDPs to offline density estimation under the realizability assumption, i.e., a model class M containing the true underlying CMDP is provided in advance. We develop an efficient, statistically near-optimal algorithm requiring only O(HlogT) calls to an offline density estimation algorithm (or oracle) across all T rounds of interaction. This number can be further reduced to O(HloglogT) if T is known in advance. Our results mark the first efficient and near-optimal reduction from CMDPs to offline density estimation without imposing any structural assumptions on the model class. A notable feature of our algorithm is the design of a layerwise exploration-exploitation tradeoff tailored to address the layerwise structure of CMDPs. Additionally, our algorithm is versatile and applicable to pure exploration tasks in reward-free reinforcement learning.
Read more5/29/2024
🏷️
0
Eluder-based Regret for Stochastic Contextual MDPs
Orin Levy, Asaf Cassel, Alon Cohen, Yishay Mansour
We present the E-UC$^3$RL algorithm for regret minimization in Stochastic Contextual Markov Decision Processes (CMDPs). The algorithm operates under the minimal assumptions of realizable function class and access to emph{offline} least squares and log loss regression oracles. Our algorithm is efficient (assuming efficient offline regression oracles) and enjoys a regret guarantee of $ widetilde{O}(H^3 sqrt{T |S| |A|d_{mathrm{E}}(mathcal{P}) log (|mathcal{F}| |mathcal{P}|/ delta) )}) , $ with $T$ being the number of episodes, $S$ the state space, $A$ the action space, $H$ the horizon, $mathcal{P}$ and $mathcal{F}$ are finite function classes used to approximate the context-dependent dynamics and rewards, respectively, and $d_{mathrm{E}}(mathcal{P})$ is the Eluder dimension of $mathcal{P}$ w.r.t the Hellinger distance. To the best of our knowledge, our algorithm is the first efficient and rate-optimal regret minimization algorithm for CMDPs that operates under the general offline function approximation setting. In addition, we extend the Eluder dimension to general bounded metrics which may be of separate interest.
Read more5/30/2024
0
RL in Latent MDPs is Tractable: Online Guarantees via Off-Policy Evaluation
Jeongyeol Kwon, Shie Mannor, Constantine Caramanis, Yonathan Efroni
In many real-world decision problems there is partially observed, hidden or latent information that remains fixed throughout an interaction. Such decision problems can be modeled as Latent Markov Decision Processes (LMDPs), where a latent variable is selected at the beginning of an interaction and is not disclosed to the agent. In the last decade, there has been significant progress in solving LMDPs under different structural assumptions. However, for general LMDPs, there is no known learning algorithm that provably matches the existing lower bound (Kwon et al., 2021). We introduce the first sample-efficient algorithm for LMDPs without any additional structural assumptions. Our result builds off a new perspective on the role of off-policy evaluation guarantees and coverage coefficients in LMDPs, a perspective, that has been overlooked in the context of exploration in partially observed environments. Specifically, we establish a novel off-policy evaluation lemma and introduce a new coverage coefficient for LMDPs. Then, we show how these can be used to derive near-optimal guarantees of an optimistic exploration algorithm. These results, we believe, can be valuable for a wide range of interactive learning problems beyond LMDPs, and especially, for partially observed environments.
Read more6/27/2024
🛠️
0
Stochastic Bilevel Optimization with Lower-Level Contextual Markov Decision Processes
Vinzenz Thoma, Barna Pasztor, Andreas Krause, Giorgia Ramponi, Yifan Hu
In various applications, the optimal policy in a strategic decision-making problem depends both on the environmental configuration and exogenous events. For these settings, we introduce Bilevel Optimization with Contextual Markov Decision Processes (BO-CMDP), a stochastic bilevel decision-making model, where the lower level consists of solving a contextual Markov Decision Process (CMDP). BO-CMDP can be viewed as a Stackelberg Game where the leader and a random context beyond the leader's control together decide the setup of (many) MDPs that (potentially multiple) followers best respond to. This framework extends beyond traditional bilevel optimization and finds relevance in diverse fields such as model design for MDPs, tax design, reward shaping and dynamic mechanism design. We propose a stochastic Hyper Policy Gradient Descent (HPGD) algorithm to solve BO-CMDP, and demonstrate its convergence. Notably, HPGD only utilizes observations of the followers' trajectories. Therefore, it allows followers to use any training procedure and the leader to be agnostic of the specific algorithm used, which aligns with various real-world scenarios. We further consider the setting when the leader can influence the training of followers and propose an accelerated algorithm. We empirically demonstrate the performance of our algorithm.
Read more6/4/2024