RL in Latent MDPs is Tractable: Online Guarantees via Off-Policy Evaluation

0
Sign in to get full access
Overview
- Reinforcement learning (RL) in latent Markov decision processes (MDPs) is a challenging problem due to the hidden state space and complex dynamics.
- This paper presents a novel approach called "RL in Latent MDPs is Tractable: Online Guarantees via Off-Policy Evaluation" that aims to make RL in latent MDPs tractable.
- The key idea is to leverage off-policy evaluation techniques to provide online performance guarantees for RL in latent MDPs, without requiring full modeling of the hidden state dynamics.
Plain English Explanation
In many real-world scenarios, the underlying decision-making process is not fully observable - there are hidden or latent states that are not directly accessible. This makes it challenging to apply reinforcement learning (RL), which relies on understanding the dynamics of the environment.
The researchers in this paper propose a new approach to tackle this problem. Instead of trying to model the full hidden state dynamics, they use off-policy evaluation techniques to assess the performance of an RL agent during the learning process. This allows them to provide guarantees about the agent's performance, without needing to completely understand the complex, underlying system.
The key insight is that by leveraging off-policy evaluation, the RL agent can learn effectively in these latent MDP settings, without requiring a complete model of the hidden state space and its dynamics. This makes the RL problem more tractable and practical for real-world applications where the environment is only partially observable.
Technical Explanation
The paper presents a novel approach to tackle the challenge of reinforcement learning (RL) in latent Markov decision processes (MDPs), where the underlying state space is not fully observed. The authors show that RL in latent MDPs can be made tractable by leveraging off-policy evaluation techniques to provide online performance guarantees.
The core idea is to use off-policy evaluation to assess the performance of the RL agent during the learning process, without requiring a complete model of the hidden state dynamics. This allows the RL agent to learn effectively in these partially observable environments, without the need to fully reconstruct the complex underlying system.
The authors provide theoretical guarantees on the performance of their approach, demonstrating that it can achieve near-optimal performance in latent MDP settings. They also validate their method through extensive experiments, showing its practical applicability and advantages over existing techniques.
Critical Analysis
The paper presents a promising approach to making RL in latent MDPs more tractable and practical. By leveraging off-policy evaluation, the researchers are able to provide strong theoretical guarantees on the agent's performance, without requiring a full model of the hidden state dynamics.
One potential limitation of the approach is that it may still require some knowledge or assumptions about the structure of the latent MDP, such as the factorization of the state space or the availability of certain feature representations. The authors acknowledge these assumptions and discuss ways to relax them in future work.
Additionally, the experimental evaluation, while comprehensive, is focused on relatively simple latent MDP environments. It would be valuable to see how the method scales and performs in more complex, real-world-inspired scenarios with richer hidden state spaces and dynamics.
Overall, the paper makes an important contribution to the field of RL in partially observable environments, and the proposed approach shows significant promise for enabling RL to be applied in a wider range of practical applications.
Conclusion
This paper presents a novel approach to making reinforcement learning (RL) in latent Markov decision processes (MDPs) more tractable and practical. By leveraging off-policy evaluation techniques, the researchers are able to provide online performance guarantees for RL agents, without requiring a complete model of the hidden state dynamics.
The key insight is that off-policy evaluation can be used to assess the agent's performance during the learning process, bypassing the need for a full reconstruction of the complex, underlying system. This makes RL in latent MDPs more accessible and opens up new possibilities for applying RL in real-world scenarios where the environment is only partially observable.
The theoretical analysis and experimental results in the paper demonstrate the effectiveness of this approach, paving the way for more widespread adoption of RL in a variety of applications where the decision-making process is not fully transparent. As the field of RL continues to evolve, techniques like the one presented in this work will be crucial for expanding the reach and applicability of these powerful learning algorithms.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
RL in Latent MDPs is Tractable: Online Guarantees via Off-Policy Evaluation
Jeongyeol Kwon, Shie Mannor, Constantine Caramanis, Yonathan Efroni
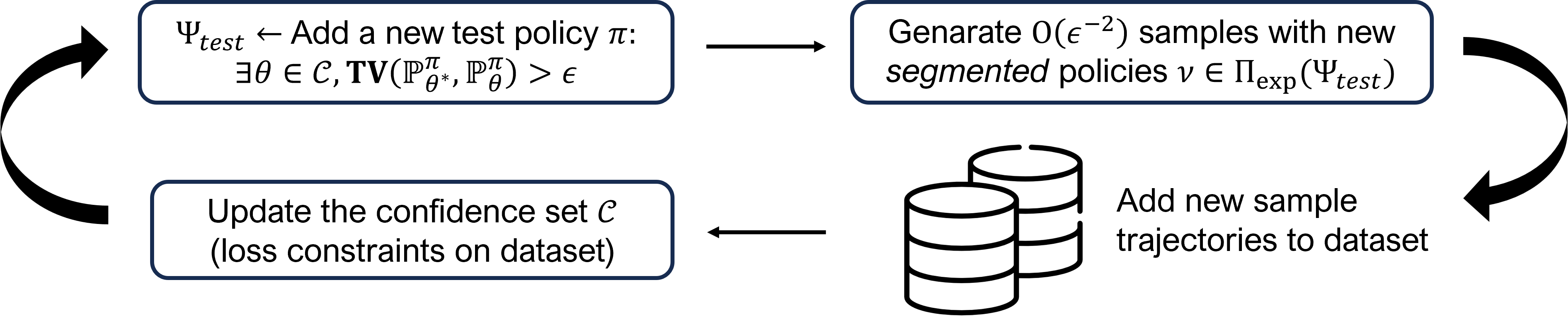
In many real-world decision problems there is partially observed, hidden or latent information that remains fixed throughout an interaction. Such decision problems can be modeled as Latent Markov Decision Processes (LMDPs), where a latent variable is selected at the beginning of an interaction and is not disclosed to the agent. In the last decade, there has been significant progress in solving LMDPs under different structural assumptions. However, for general LMDPs, there is no known learning algorithm that provably matches the existing lower bound (Kwon et al., 2021). We introduce the first sample-efficient algorithm for LMDPs without any additional structural assumptions. Our result builds off a new perspective on the role of off-policy evaluation guarantees and coverage coefficients in LMDPs, a perspective, that has been overlooked in the context of exploration in partially observed environments. Specifically, we establish a novel off-policy evaluation lemma and introduce a new coverage coefficient for LMDPs. Then, we show how these can be used to derive near-optimal guarantees of an optimistic exploration algorithm. These results, we believe, can be valuable for a wide range of interactive learning problems beyond LMDPs, and especially, for partially observed environments.
Read more6/27/2024
🤿
0
Near-Optimal Learning and Planning in Separated Latent MDPs
Fan Chen, Constantinos Daskalakis, Noah Golowich, Alexander Rakhlin
We study computational and statistical aspects of learning Latent Markov Decision Processes (LMDPs). In this model, the learner interacts with an MDP drawn at the beginning of each epoch from an unknown mixture of MDPs. To sidestep known impossibility results, we consider several notions of separation of the constituent MDPs. The main thrust of this paper is in establishing a nearly-sharp *statistical threshold* for the horizon length necessary for efficient learning. On the computational side, we show that under a weaker assumption of separability under the optimal policy, there is a quasi-polynomial algorithm with time complexity scaling in terms of the statistical threshold. We further show a near-matching time complexity lower bound under the exponential time hypothesis.
Read more6/13/2024
🐍
0
Sample Complexity of Offline Distributionally Robust Linear Markov Decision Processes
He Wang, Laixi Shi, Yuejie Chi
In offline reinforcement learning (RL), the absence of active exploration calls for attention on the model robustness to tackle the sim-to-real gap, where the discrepancy between the simulated and deployed environments can significantly undermine the performance of the learned policy. To endow the learned policy with robustness in a sample-efficient manner in the presence of high-dimensional state-action space, this paper considers the sample complexity of distributionally robust linear Markov decision processes (MDPs) with an uncertainty set characterized by the total variation distance using offline data. We develop a pessimistic model-based algorithm and establish its sample complexity bound under minimal data coverage assumptions, which outperforms prior art by at least $widetilde{O}(d)$, where $d$ is the feature dimension. We further improve the performance guarantee of the proposed algorithm by incorporating a carefully-designed variance estimator.
Read more6/28/2024
🔍
0
A Primal-Dual Algorithm for Offline Constrained Reinforcement Learning with Linear MDPs
Kihyuk Hong, Ambuj Tewari
We study offline reinforcement learning (RL) with linear MDPs under the infinite-horizon discounted setting which aims to learn a policy that maximizes the expected discounted cumulative reward using a pre-collected dataset. Existing algorithms for this setting either require a uniform data coverage assumptions or are computationally inefficient for finding an $epsilon$-optimal policy with $O(epsilon^{-2})$ sample complexity. In this paper, we propose a primal dual algorithm for offline RL with linear MDPs in the infinite-horizon discounted setting. Our algorithm is the first computationally efficient algorithm in this setting that achieves sample complexity of $O(epsilon^{-2})$ with partial data coverage assumption. Our work is an improvement upon a recent work that requires $O(epsilon^{-4})$ samples. Moreover, we extend our algorithm to work in the offline constrained RL setting that enforces constraints on additional reward signals.
Read more6/4/2024