Offline Supervised Learning V.S. Online Direct Policy Optimization: A Comparative Study and A Unified Training Paradigm for Neural Network-Based Optimal Feedback Control

0
👨🏫
Sign in to get full access
Overview
- The paper focuses on efficiently solving neural network-based feedback controllers for optimal control problems.
- It compares two common approaches: offline supervised learning and online direct policy optimization.
- The paper proposes a unified "Pre-train and Fine-tune" strategy to address the challenges in these two approaches.
Plain English Explanation
The paper investigates ways to efficiently solve neural network-based feedback controllers for optimal control problems. Optimal control is about finding the best way to control a system, like a robot or a manufacturing process, to achieve a desired outcome.
The researchers compare two common approaches. The first is offline supervised learning, where the neural network is trained on a dataset of optimal control solutions. This is relatively easy to set up, but the success heavily depends on the quality of the dataset, which comes from separate optimal control solvers.
The second approach is online direct policy optimization, which formulates the optimal control problem as an optimization problem that the neural network can learn directly. This avoids the need for a pre-computed dataset, but the optimization can be challenging, especially for complex problems.
The paper finds that the offline supervised learning approach generally outperforms the online direct policy optimization in terms of solution quality and training time. To build on the strengths of both approaches, the researchers propose a "Pre-train and Fine-tune" strategy. This first pre-trains the neural network using supervised learning, then fine-tunes it through direct policy optimization. This unified approach significantly improves the performance and robustness of the optimal feedback control.
Technical Explanation
The paper conducts a comparative study of two main approaches for solving neural network-based feedback controllers for optimal control problems: offline supervised learning and online direct policy optimization.
In the supervised learning approach, the neural network is trained on a dataset of optimal control solutions generated by separate open-loop optimal control solvers. While the training process is relatively straightforward, the success of this method heavily depends on the quality of the dataset.
In contrast, the direct policy optimization approach formulates the optimal control problem as an optimization problem that the neural network can learn directly, without any pre-computed dataset. However, the dynamics-related objective can be challenging to optimize, especially for complicated problems.
The paper's experimental results show that the offline supervised learning approach outperforms the online direct policy optimization in terms of both solution optimality and training time.
To address the key challenges in these two approaches - the dataset quality in supervised learning and the optimization difficulty in direct policy optimization - the researchers propose a "Pre-train and Fine-tune" strategy as a unified training paradigm. This approach first pre-trains the neural network using supervised learning, then fine-tunes it through direct policy optimization. This combined method significantly improves the performance and robustness of the optimal feedback control.
Critical Analysis
The paper provides a comprehensive comparison of two prevalent approaches for solving optimal control problems using neural network-based feedback controllers. The researchers acknowledge the limitations of each approach and propose a unified strategy to leverage the strengths of both.
One potential area for further research is exploring the scalability and generalization of the "Pre-train and Fine-tune" approach to more complex, high-dimensional optimal control problems. The paper focuses on relatively simple examples, and it would be valuable to investigate how the method performs on real-world, large-scale applications.
Additionally, the paper does not delve into the computational and memory requirements of the different approaches, which could be an important consideration for real-time, resource-constrained control systems. Investigating the trade-offs between solution quality, training time, and computational efficiency would be a valuable addition to the analysis.
Overall, the paper makes a compelling case for the "Pre-train and Fine-tune" strategy as an effective way to combine the benefits of supervised learning and direct policy optimization for optimal feedback control. The findings could have significant implications for the design and deployment of neural network-based control systems in a wide range of cyber-physical and robotic applications.
Conclusion
This paper presents a comparative study of two prevalent approaches for solving neural network-based feedback controllers for optimal control problems: offline supervised learning and online direct policy optimization. The results demonstrate the superiority of the supervised learning approach in terms of solution optimality and training time.
To address the key challenges in these two methods, the researchers propose a "Pre-train and Fine-tune" strategy as a unified training paradigm. This approach first pre-trains the neural network using supervised learning, then fine-tunes it through direct policy optimization. The combined method significantly improves the performance and robustness of the optimal feedback control.
The findings of this work could have important implications for the development of efficient and reliable neural network-based control systems in a variety of applications, from robotics and manufacturing to energy systems and transportation.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
👨🏫
0
Offline Supervised Learning V.S. Online Direct Policy Optimization: A Comparative Study and A Unified Training Paradigm for Neural Network-Based Optimal Feedback Control
Yue Zhao, Jiequn Han
This work is concerned with solving neural network-based feedback controllers efficiently for optimal control problems. We first conduct a comparative study of two prevalent approaches: offline supervised learning and online direct policy optimization. Albeit the training part of the supervised learning approach is relatively easy, the success of the method heavily depends on the optimal control dataset generated by open-loop optimal control solvers. In contrast, direct policy optimization turns the optimal control problem into an optimization problem directly without any requirement of pre-computing, but the dynamics-related objective can be hard to optimize when the problem is complicated. Our results underscore the superiority of offline supervised learning in terms of both optimality and training time. To overcome the main challenges, dataset and optimization, in the two approaches respectively, we complement them and propose the Pre-train and Fine-tune strategy as a unified training paradigm for optimal feedback control, which further improves the performance and robustness significantly. Our code is accessible at https://github.com/yzhao98/DeepOptimalControl.
Read more4/10/2024
0
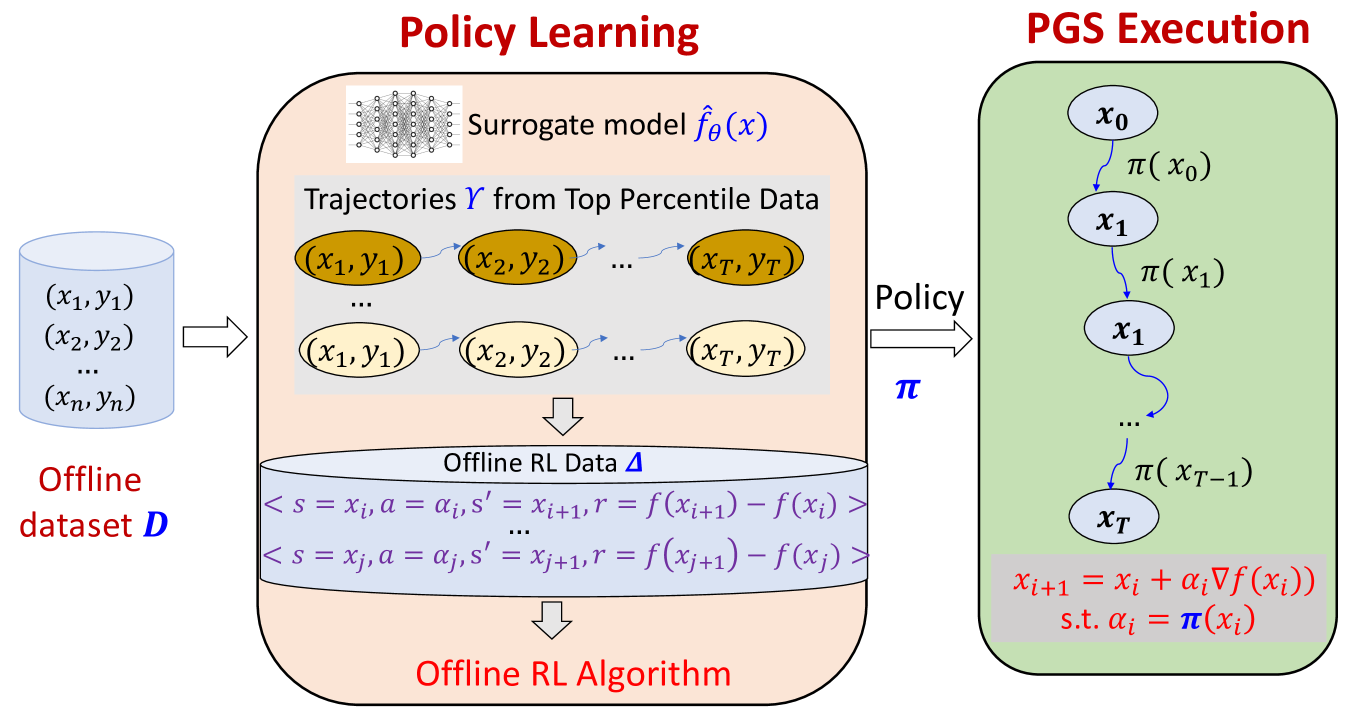
Offline Model-Based Optimization via Policy-Guided Gradient Search
Yassine Chemingui, Aryan Deshwal, Trong Nghia Hoang, Janardhan Rao Doppa
Offline optimization is an emerging problem in many experimental engineering domains including protein, drug or aircraft design, where online experimentation to collect evaluation data is too expensive or dangerous. To avoid that, one has to optimize an unknown function given only its offline evaluation at a fixed set of inputs. A naive solution to this problem is to learn a surrogate model of the unknown function and optimize this surrogate instead. However, such a naive optimizer is prone to erroneous overestimation of the surrogate (possibly due to over-fitting on a biased sample of function evaluation) on inputs outside the offline dataset. Prior approaches addressing this challenge have primarily focused on learning robust surrogate models. However, their search strategies are derived from the surrogate model rather than the actual offline data. To fill this important gap, we introduce a new learning-to-search perspective for offline optimization by reformulating it as an offline reinforcement learning problem. Our proposed policy-guided gradient search approach explicitly learns the best policy for a given surrogate model created from the offline data. Our empirical results on multiple benchmarks demonstrate that the learned optimization policy can be combined with existing offline surrogates to significantly improve the optimization performance.
Read more5/10/2024

0
On Building Myopic MPC Policies using Supervised Learning
Christopher A. Orrico, Bokan Yang, Dinesh Krishnamoorthy
The application of supervised learning techniques in combination with model predictive control (MPC) has recently generated significant interest, particularly in the area of approximate explicit MPC, where function approximators like deep neural networks are used to learn the MPC policy via optimal state-action pairs generated offline. While the aim of approximate explicit MPC is to closely replicate the MPC policy, substituting online optimization with a trained neural network, the performance guarantees that come with solving the online optimization problem are typically lost. This paper considers an alternative strategy, where supervised learning is used to learn the optimal value function offline instead of learning the optimal policy. This can then be used as the cost-to-go function in a myopic MPC with a very short prediction horizon, such that the online computation burden reduces significantly without affecting the controller performance. This approach differs from existing work on value function approximations in the sense that it learns the cost-to-go function by using offline-collected state-value pairs, rather than closed-loop performance data. The cost of generating the state-value pairs used for training is addressed using a sensitivity-based data augmentation scheme.
Read more8/12/2024

0
Unsupervised-to-Online Reinforcement Learning
Junsu Kim, Seohong Park, Sergey Levine
Offline-to-online reinforcement learning (RL), a framework that trains a policy with offline RL and then further fine-tunes it with online RL, has been considered a promising recipe for data-driven decision-making. While sensible, this framework has drawbacks: it requires domain-specific offline RL pre-training for each task, and is often brittle in practice. In this work, we propose unsupervised-to-online RL (U2O RL), which replaces domain-specific supervised offline RL with unsupervised offline RL, as a better alternative to offline-to-online RL. U2O RL not only enables reusing a single pre-trained model for multiple downstream tasks, but also learns better representations, which often result in even better performance and stability than supervised offline-to-online RL. To instantiate U2O RL in practice, we propose a general recipe for U2O RL to bridge task-agnostic unsupervised offline skill-based policy pre-training and supervised online fine-tuning. Throughout our experiments in nine state-based and pixel-based environments, we empirically demonstrate that U2O RL achieves strong performance that matches or even outperforms previous offline-to-online RL approaches, while being able to reuse a single pre-trained model for a number of different downstream tasks.
Read more8/28/2024