OLIVE: Object Level In-Context Visual Embeddings
2406.00872
0
0
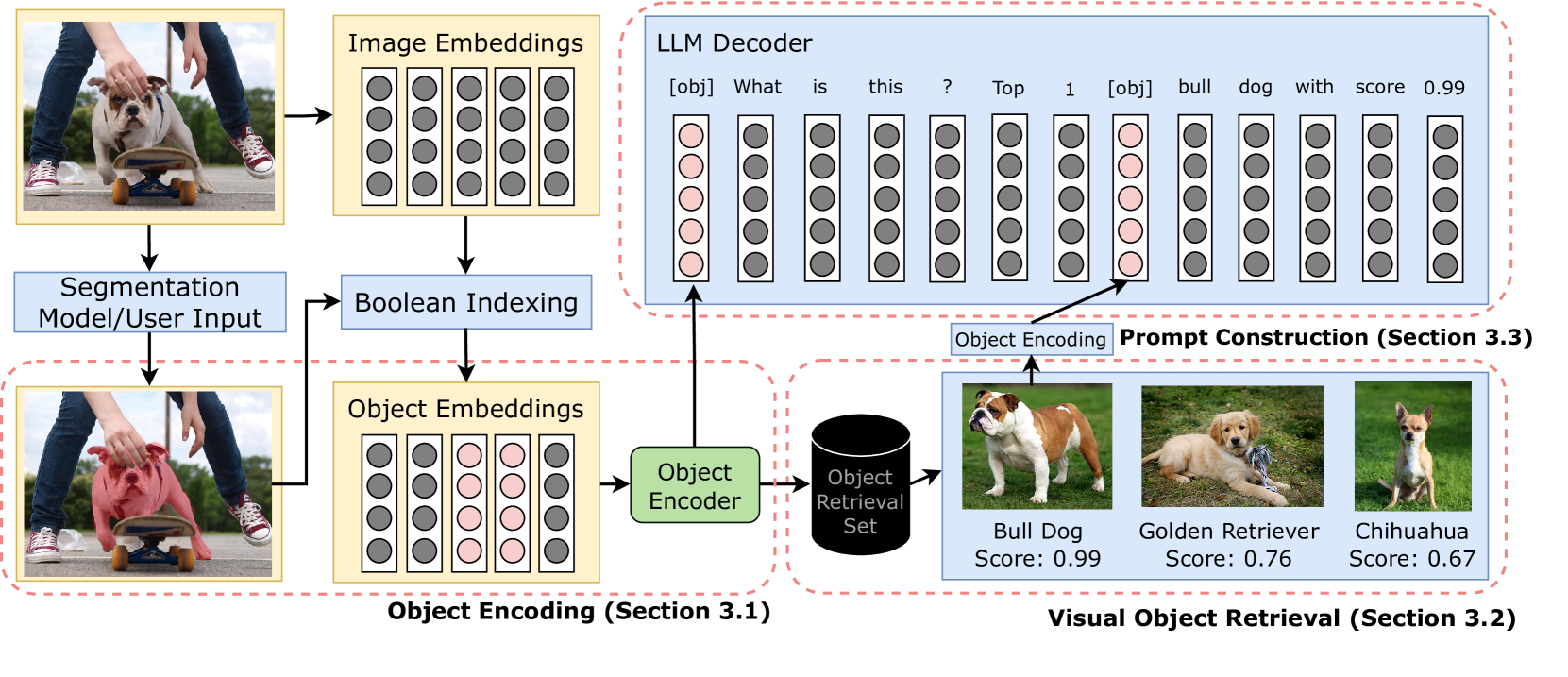
Abstract
Recent generalist vision-language models (VLMs) have demonstrated impressive reasoning capabilities across diverse multimodal tasks. However, these models still struggle with fine-grained object-level understanding and grounding. In terms of modeling, existing VLMs implicitly align text tokens with image patch tokens, which is ineffective for embedding alignment at the same granularity and inevitably introduces noisy spurious background features. Additionally, these models struggle when generalizing to unseen visual concepts and may not be reliable for domain-specific tasks without further fine-tuning. To address these limitations, we propose a novel method to prompt large language models with in-context visual object vectors, thereby enabling controllable object-level reasoning. This eliminates the necessity of fusing a lengthy array of image patch features and significantly speeds up training. Furthermore, we propose region-level retrieval using our object representations, facilitating rapid adaptation to new objects without additional training. Our experiments reveal that our method achieves competitive referring object classification and captioning performance, while also offering zero-shot generalization and robustness to visually challenging contexts.
Create account to get full access
Overview
- The paper presents OLIVE (Object Level In-Context Visual Embeddings), a novel approach to generating visual embeddings that capture the relationships between objects in an image.
- OLIVE aims to improve performance on downstream tasks like visual question answering and image retrieval by incorporating object-level information into the visual embeddings.
- The model uses a generative vision-language architecture to learn visual embeddings that are aligned with natural language descriptions of the objects and their relationships.
Plain English Explanation
OLIVE is a new way of creating visual embeddings, which are numerical representations of images that can be used for various AI tasks. The key idea behind OLIVE is to capture not just individual objects in an image, but also how those objects relate to each other.
Traditional visual embeddings might represent an image as a collection of separate objects, like a person, a dog, and a ball. OLIVE goes further by also representing how those objects are connected - for example, that the person is petting the dog, or that the ball is next to the dog.
By incorporating this object-level context, OLIVE aims to produce visual embeddings that are more informative and useful for tasks like answering questions about an image or finding similar images. The model is trained using a combination of visual and language data, learning to align the visual embeddings with natural language descriptions of the scenes.
The researchers believe that this richer representation of the visual world will lead to improved performance on a variety of computer vision and multimodal AI applications. [link to https://aimodels.fyi/papers/arxiv/learning-to-localize-objects-improves-spatial-reasoning]
Technical Explanation
OLIVE uses a generative vision-language architecture to learn visual embeddings that capture object-level relationships. The model takes an input image and generates a set of object embeddings, which represent the individual objects present. It also generates a scene embedding, which encodes the overall context and relationships between the objects.
These visual embeddings are trained to align with textual descriptions of the images, by optimizing a contrastive loss function that encourages the model to match the correct text to the corresponding visual input. This allows OLIVE to learn visual representations that are grounded in natural language.
The researchers experiment with different architectural choices, such as the use of attention mechanisms and various ways of fusing the object and scene embeddings. They evaluate OLIVE on tasks like visual question answering and image retrieval, and find that it outperforms previous approaches that do not explicitly model object-level relationships. [link to https://aimodels.fyi/papers/arxiv/refining-skewed-perceptions-vision-language-models-through]
Critical Analysis
The OLIVE paper makes a compelling case for the importance of incorporating object-level context into visual embeddings. By going beyond just representing individual objects, the model is able to capture richer and more nuanced information about the visual world.
However, one potential limitation is the reliance on textual descriptions to learn the visual-language alignment. While this approach has been effective, it may miss certain nuances or implicit relationships that are not easily expressed in language. [link to https://aimodels.fyi/papers/arxiv/lyrics-boosting-fine-grained-language-vision-alignment]
Additionally, the paper does not explore the scalability of the OLIVE approach to larger and more diverse datasets. As the number of objects and their relationships grows, the complexity of the model and the amount of training data required may become a significant challenge.
Further research could also investigate ways to make the OLIVE embeddings more promptable and adaptable to various downstream tasks, rather than requiring retraining for each application. [link to https://aimodels.fyi/papers/arxiv/vision-language-models-provide-promptable-representations-reinforcement]
Conclusion
The OLIVE paper presents a novel approach to generating visual embeddings that capture object-level relationships, which the researchers show can lead to improved performance on tasks like visual question answering and image retrieval. By incorporating this richer object-centric representation of the visual world, OLIVE offers a promising direction for advancing the capabilities of multimodal AI systems.
While the current implementation has some limitations, the core idea of leveraging object-level context to enhance visual embeddings is a valuable contribution to the field. Further research and refinement of the OLIVE approach could lead to even more powerful and versatile visual representations that can benefit a wide range of computer vision and multimodal applications. [link to https://aimodels.fyi/papers/arxiv/collavo-crayon-large-language-vision-model]
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
💬
CoLLaVO: Crayon Large Language and Vision mOdel
Byung-Kwan Lee, Beomchan Park, Chae Won Kim, Yong Man Ro
0
0
The remarkable success of Large Language Models (LLMs) and instruction tuning drives the evolution of Vision Language Models (VLMs) towards a versatile general-purpose model. Yet, it remains unexplored whether current VLMs genuinely possess quality object-level image understanding capabilities determined from 'what objects are in the image?' or 'which object corresponds to a specified bounding box?'. Our findings reveal that the image understanding capabilities of current VLMs are strongly correlated with their zero-shot performance on vision language (VL) tasks. This suggests that prioritizing basic image understanding is crucial for VLMs to excel at VL tasks. To enhance object-level image understanding, we propose Crayon Large Language and Vision mOdel (CoLLaVO), which incorporates instruction tuning with Crayon Prompt as a new visual prompt tuning scheme based on panoptic color maps. Furthermore, we present a learning strategy of Dual QLoRA to preserve object-level image understanding without forgetting it during visual instruction tuning, thereby achieving a significant leap in numerous VL benchmarks in a zero-shot setting.
6/4/2024

OMG-LLaVA: Bridging Image-level, Object-level, Pixel-level Reasoning and Understanding
Tao Zhang, Xiangtai Li, Hao Fei, Haobo Yuan, Shengqiong Wu, Shunping Ji, Chen Change Loy, Shuicheng Yan
0
0
Current universal segmentation methods demonstrate strong capabilities in pixel-level image and video understanding. However, they lack reasoning abilities and cannot be controlled via text instructions. In contrast, large vision-language multimodal models exhibit powerful vision-based conversation and reasoning capabilities but lack pixel-level understanding and have difficulty accepting visual prompts for flexible user interaction. This paper proposes OMG-LLaVA, a new and elegant framework combining powerful pixel-level vision understanding with reasoning abilities. It can accept various visual and text prompts for flexible user interaction. Specifically, we use a universal segmentation method as the visual encoder, integrating image information, perception priors, and visual prompts into visual tokens provided to the LLM. The LLM is responsible for understanding the user's text instructions and providing text responses and pixel-level segmentation results based on the visual information. We propose perception prior embedding to better integrate perception priors with image features. OMG-LLaVA achieves image-level, object-level, and pixel-level reasoning and understanding in a single model, matching or surpassing the performance of specialized methods on multiple benchmarks. Rather than using LLM to connect each specialist, our work aims at end-to-end training on one encoder, one decoder, and one LLM. The code and model have been released for further research.
6/28/2024

Learning to Localize Objects Improves Spatial Reasoning in Visual-LLMs
Kanchana Ranasinghe, Satya Narayan Shukla, Omid Poursaeed, Michael S. Ryoo, Tsung-Yu Lin
0
0
Integration of Large Language Models (LLMs) into visual domain tasks, resulting in visual-LLMs (V-LLMs), has enabled exceptional performance in vision-language tasks, particularly for visual question answering (VQA). However, existing V-LLMs (e.g. BLIP-2, LLaVA) demonstrate weak spatial reasoning and localization awareness. Despite generating highly descriptive and elaborate textual answers, these models fail at simple tasks like distinguishing a left vs right location. In this work, we explore how image-space coordinate based instruction fine-tuning objectives could inject spatial awareness into V-LLMs. We discover optimal coordinate representations, data-efficient instruction fine-tuning objectives, and pseudo-data generation strategies that lead to improved spatial awareness in V-LLMs. Additionally, our resulting model improves VQA across image and video domains, reduces undesired hallucination, and generates better contextual object descriptions. Experiments across 5 vision-language tasks involving 14 different datasets establish the clear performance improvements achieved by our proposed framework.
4/12/2024
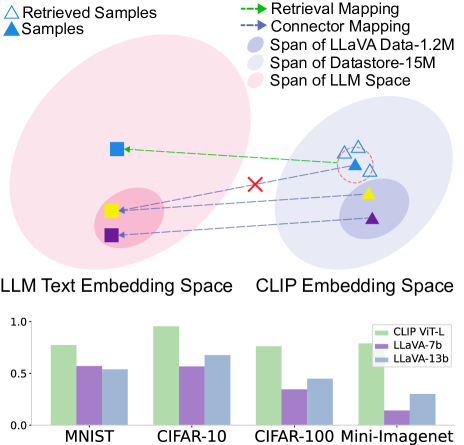
Reminding Multimodal Large Language Models of Object-aware Knowledge with Retrieved Tags
Daiqing Qi, Handong Zhao, Zijun Wei, Sheng Li
0
0
Despite recent advances in the general visual instruction-following ability of Multimodal Large Language Models (MLLMs), they still struggle with critical problems when required to provide a precise and detailed response to a visual instruction: (1) failure to identify novel objects or entities, (2) mention of non-existent objects, and (3) neglect of object's attributed details. Intuitive solutions include improving the size and quality of data or using larger foundation models. They show effectiveness in mitigating these issues, but at an expensive cost of collecting a vast amount of new data and introducing a significantly larger model. Standing at the intersection of these approaches, we examine the three object-oriented problems from the perspective of the image-to-text mapping process by the multimodal connector. In this paper, we first identify the limitations of multimodal connectors stemming from insufficient training data. Driven by this, we propose to enhance the mapping with retrieval-augmented tag tokens, which contain rich object-aware information such as object names and attributes. With our Tag-grounded visual instruction tuning with retrieval Augmentation (TUNA), we outperform baselines that share the same language model and training data on 12 benchmarks. Furthermore, we show the zero-shot capability of TUNA when provided with specific datastores.
6/18/2024