Reminding Multimodal Large Language Models of Object-aware Knowledge with Retrieved Tags
2406.10839
0
0
Abstract
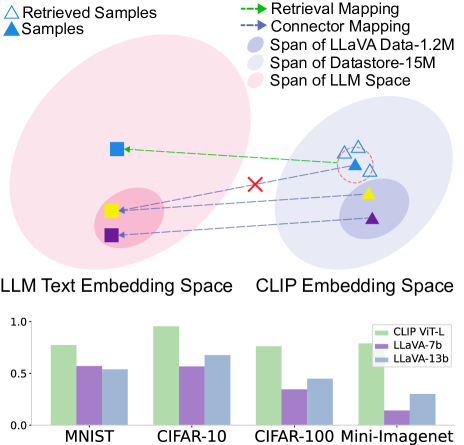
Despite recent advances in the general visual instruction-following ability of Multimodal Large Language Models (MLLMs), they still struggle with critical problems when required to provide a precise and detailed response to a visual instruction: (1) failure to identify novel objects or entities, (2) mention of non-existent objects, and (3) neglect of object's attributed details. Intuitive solutions include improving the size and quality of data or using larger foundation models. They show effectiveness in mitigating these issues, but at an expensive cost of collecting a vast amount of new data and introducing a significantly larger model. Standing at the intersection of these approaches, we examine the three object-oriented problems from the perspective of the image-to-text mapping process by the multimodal connector. In this paper, we first identify the limitations of multimodal connectors stemming from insufficient training data. Driven by this, we propose to enhance the mapping with retrieval-augmented tag tokens, which contain rich object-aware information such as object names and attributes. With our Tag-grounded visual instruction tuning with retrieval Augmentation (TUNA), we outperform baselines that share the same language model and training data on 12 benchmarks. Furthermore, we show the zero-shot capability of TUNA when provided with specific datastores.
Create account to get full access
Overview
- The research paper explores how to "remind" large language models of object-aware knowledge using retrieved tags.
- It aims to enhance the performance of multimodal large language models by incorporating object-level visual cues and information.
- The approach involves retrieving relevant object tags and integrating them with the language model to improve its understanding and reasoning about visual concepts.
Plain English Explanation
Large language models have become incredibly powerful, but they can sometimes lack a deep understanding of the visual world. This paper proposes a way to "remind" these models of object-level knowledge by retrieving relevant tags and incorporating them into the language model.
The key idea is that by adding object-level information, the language model can better understand and reason about visual concepts. For example, if the model is processing text about a dog, retrieving tags related to the visual attributes of dogs (e.g., fur, tail, paws) could help the model have a more nuanced understanding of the topic.
The researchers tested this approach on various tasks, such as visual question answering and image-text retrieval, and found that it led to improved performance compared to using the language model alone. This suggests that reminding large language models of object-level knowledge can be a valuable technique for enhancing their multimodal capabilities.
Technical Explanation
The paper proposes a method called "Reminding Multimodal Large Language Models of Object-aware Knowledge with Retrieved Tags" (REMINDER) to enhance the performance of multimodal large language models. The core idea is to retrieve relevant object tags and integrate them with the language model to improve its understanding and reasoning about visual concepts.
The REMINDER approach involves three main components:
-
Object Tag Retrieval: The method retrieves a set of object tags that are relevant to the input text or image. This is done by using a separate object detection model to identify the objects in the image, and then matching the detected objects to a large set of predefined object tags.
-
Object Tag Integration: The retrieved object tags are then integrated with the language model's input, either by concatenating them with the text or by incorporating them into the model's attention mechanism.
-
Multimodal Fine-tuning: The language model is fine-tuned on multimodal tasks, such as visual question answering and image-text retrieval, to enable it to better leverage the object-level information.
The researchers evaluated REMINDER on a range of multimodal benchmarks and found that it consistently outperformed the baseline language model, demonstrating the value of reminding large language models of object-aware knowledge.
Critical Analysis
The paper presents a compelling approach to enhancing multimodal large language models by incorporating object-level visual information. The key strength of the REMINDER method is its simplicity and flexibility, as it can be easily integrated with existing language models without requiring major architectural changes.
However, one potential limitation of the approach is that it relies on the accuracy and completeness of the predefined object tag set. If the tag set does not cover the full range of relevant visual concepts, the model may still struggle to fully understand certain visual aspects. Additionally, the paper does not explore the impact of the size and quality of the object tag set on the model's performance.
Another area for further research could be investigating more sophisticated ways of integrating the object tags with the language model, beyond simple concatenation or attention integration. For example, Exploring Multi-Modal Large Language Models suggests that deeper integration of visual and textual representations may be beneficial.
Overall, the REMINDER method presents a promising direction for enhancing the multimodal capabilities of large language models, and the results are compelling. However, continued research and exploration of related approaches, such as Leveraging Multimodal Retrieval for Augmentation and Object-Level Context Visual Embeddings, could lead to further advancements in this important area.
Conclusion
This paper introduces a novel approach called REMINDER that aims to enhance the performance of multimodal large language models by reminding them of object-aware knowledge through the integration of retrieved object tags. The results demonstrate the value of this technique, which can improve the models' understanding and reasoning about visual concepts.
As the field of multimodal large language models continues to advance, approaches like REMINDER that leverage object-level information could play an increasingly important role in developing more capable and versatile AI systems. The insights and techniques presented in this paper could inspire further research and innovation in this exciting and rapidly evolving area of artificial intelligence.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Enhancing Multimodal Large Language Models with Vision Detection Models: An Empirical Study
Qirui Jiao, Daoyuan Chen, Yilun Huang, Yaliang Li, Ying Shen
0
0
Despite the impressive capabilities of Multimodal Large Language Models (MLLMs) in integrating text and image modalities, challenges remain in accurately interpreting detailed visual elements. This paper presents an empirical study on enhancing MLLMs with state-of-the-art (SOTA) object detection and Optical Character Recognition (OCR) models to improve fine-grained understanding and reduce hallucination in responses. We investigate the embedding-based infusion of textual detection information, the impact of such infusion on MLLMs' original abilities, and the interchangeability of detection models. We conduct systematic and extensive experiments with representative models such as LLaVA-1.5, DINO, PaddleOCRv2, and Grounding DINO, revealing that our simple yet general approach not only refines MLLMs' performance in fine-grained visual tasks but also maintains their original strengths. Notably, the enhanced LLaVA-1.5 outperforms its original 7B/13B models on all 10 benchmarks, achieving an improvement of up to 12.5% on the normalized average score. We release our codes to facilitate further exploration into the fine-grained multimodal capabilities of MLLMs.
5/31/2024
💬
Explaining Multi-modal Large Language Models by Analyzing their Vision Perception
Loris Giulivi, Giacomo Boracchi
0
0
Multi-modal Large Language Models (MLLMs) have demonstrated remarkable capabilities in understanding and generating content across various modalities, such as images and text. However, their interpretability remains a challenge, hindering their adoption in critical applications. This research proposes a novel approach to enhance the interpretability of MLLMs by focusing on the image embedding component. We combine an open-world localization model with a MLLM, thus creating a new architecture able to simultaneously produce text and object localization outputs from the same vision embedding. The proposed architecture greatly promotes interpretability, enabling us to design a novel saliency map to explain any output token, to identify model hallucinations, and to assess model biases through semantic adversarial perturbations.
5/29/2024

The Revolution of Multimodal Large Language Models: A Survey
Davide Caffagni, Federico Cocchi, Luca Barsellotti, Nicholas Moratelli, Sara Sarto, Lorenzo Baraldi, Lorenzo Baraldi, Marcella Cornia, Rita Cucchiara
0
0
Connecting text and visual modalities plays an essential role in generative intelligence. For this reason, inspired by the success of large language models, significant research efforts are being devoted to the development of Multimodal Large Language Models (MLLMs). These models can seamlessly integrate visual and textual modalities, while providing a dialogue-based interface and instruction-following capabilities. In this paper, we provide a comprehensive review of recent visual-based MLLMs, analyzing their architectural choices, multimodal alignment strategies, and training techniques. We also conduct a detailed analysis of these models across a wide range of tasks, including visual grounding, image generation and editing, visual understanding, and domain-specific applications. Additionally, we compile and describe training datasets and evaluation benchmarks, conducting comparisons among existing models in terms of performance and computational requirements. Overall, this survey offers a comprehensive overview of the current state of the art, laying the groundwork for future MLLMs.
6/7/2024
OLIVE: Object Level In-Context Visual Embeddings
Timothy Ossowski, Junjie Hu
0
0
Recent generalist vision-language models (VLMs) have demonstrated impressive reasoning capabilities across diverse multimodal tasks. However, these models still struggle with fine-grained object-level understanding and grounding. In terms of modeling, existing VLMs implicitly align text tokens with image patch tokens, which is ineffective for embedding alignment at the same granularity and inevitably introduces noisy spurious background features. Additionally, these models struggle when generalizing to unseen visual concepts and may not be reliable for domain-specific tasks without further fine-tuning. To address these limitations, we propose a novel method to prompt large language models with in-context visual object vectors, thereby enabling controllable object-level reasoning. This eliminates the necessity of fusing a lengthy array of image patch features and significantly speeds up training. Furthermore, we propose region-level retrieval using our object representations, facilitating rapid adaptation to new objects without additional training. Our experiments reveal that our method achieves competitive referring object classification and captioning performance, while also offering zero-shot generalization and robustness to visually challenging contexts.
6/4/2024