OMG-LLaVA: Bridging Image-level, Object-level, Pixel-level Reasoning and Understanding
2406.19389
0
0

Abstract
Current universal segmentation methods demonstrate strong capabilities in pixel-level image and video understanding. However, they lack reasoning abilities and cannot be controlled via text instructions. In contrast, large vision-language multimodal models exhibit powerful vision-based conversation and reasoning capabilities but lack pixel-level understanding and have difficulty accepting visual prompts for flexible user interaction. This paper proposes OMG-LLaVA, a new and elegant framework combining powerful pixel-level vision understanding with reasoning abilities. It can accept various visual and text prompts for flexible user interaction. Specifically, we use a universal segmentation method as the visual encoder, integrating image information, perception priors, and visual prompts into visual tokens provided to the LLM. The LLM is responsible for understanding the user's text instructions and providing text responses and pixel-level segmentation results based on the visual information. We propose perception prior embedding to better integrate perception priors with image features. OMG-LLaVA achieves image-level, object-level, and pixel-level reasoning and understanding in a single model, matching or surpassing the performance of specialized methods on multiple benchmarks. Rather than using LLM to connect each specialist, our work aims at end-to-end training on one encoder, one decoder, and one LLM. The code and model have been released for further research.
Create account to get full access
Overview
- This paper introduces OMG-LLaVA, a novel model that bridges image-level, object-level, and pixel-level reasoning and understanding.
- OMG-LLaVA leverages large language models and vision transformers to perform diverse visual tasks, including image classification, object detection, and semantic segmentation.
- The model aims to overcome the limitations of existing approaches by integrating multiple levels of visual understanding into a single, unified system.
Plain English Explanation
OMG-LLaVA is a new AI model that can analyze images in a more comprehensive way than previous models. It can not only classify the overall image, but also detect and identify specific objects within the image, and even understand the detailed pixel-level features of the image.
This is important because different visual tasks, such as image classification, object detection, and semantic segmentation, have traditionally been treated as separate problems, each requiring their own specialized models. OMG-LLaVA tries to bridge these different levels of visual understanding into a single, more powerful system.
By leveraging large language models and vision transformers, OMG-LLaVA can perform a wide range of visual tasks, from classifying the overall image to detecting individual objects to understanding the detailed pixel-level features of an image. This integrated approach can lead to more accurate and holistic understanding of visual scenes.
Technical Explanation
OMG-LLaVA builds on recent advancements in large language models and vision transformers to create a unified model that can perform a variety of visual tasks. The key innovation of OMG-LLaVA is its ability to seamlessly integrate image-level, object-level, and pixel-level reasoning within a single framework.
The model comprises several interconnected modules, each responsible for a specific visual task. The image-level module handles high-level image classification, the object-level module focuses on object detection and recognition, and the pixel-level module performs detailed semantic segmentation. These modules are designed to share and exchange information, allowing the model to leverage insights from multiple levels of visual understanding.
The researchers extensively evaluated OMG-LLaVA on a range of standard benchmarks, demonstrating state-of-the-art performance across image classification, object detection, and semantic segmentation tasks. The model's ability to jointly reason about images at different levels of granularity sets it apart from previous approaches that treated these tasks in isolation.
Critical Analysis
The researchers have made a compelling case for the benefits of integrating multiple levels of visual reasoning within a single model. OMG-LLaVA's strong performance on established benchmarks suggests that this approach can lead to more accurate and holistic understanding of visual scenes.
However, the paper does not address the potential computational and memory overhead associated with such a comprehensive model. Integrating image-level, object-level, and pixel-level reasoning may require significant resources, which could limit the model's deployment in real-world applications with resource constraints.
Additionally, the paper does not delve into the interpretability and explainability of OMG-LLaVA's decision-making process. As the model becomes more complex, understanding how it arrives at its predictions may become increasingly important, especially in sensitive domains like healthcare or autonomous systems.
Further research could explore ways to improve the efficiency and interpretability of OMG-LLaVA, potentially through the use of knowledge distillation or modular architectures. Investigating the model's performance on a wider range of real-world tasks and datasets would also help validate its broader applicability.
Conclusion
OMG-LLaVA represents an important step forward in the field of computer vision by bridging image-level, object-level, and pixel-level reasoning and understanding. By leveraging large language models and vision transformers, the model can perform a diverse array of visual tasks with state-of-the-art accuracy.
This integrated approach to visual understanding has the potential to enable more robust and comprehensive analysis of complex scenes, with applications in areas like autonomous driving, medical imaging, and smart surveillance. As the field of AI continues to evolve, models like OMG-LLaVA that can seamlessly combine multiple levels of visual reasoning may become increasingly valuable tools for unlocking new insights from the visual world.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
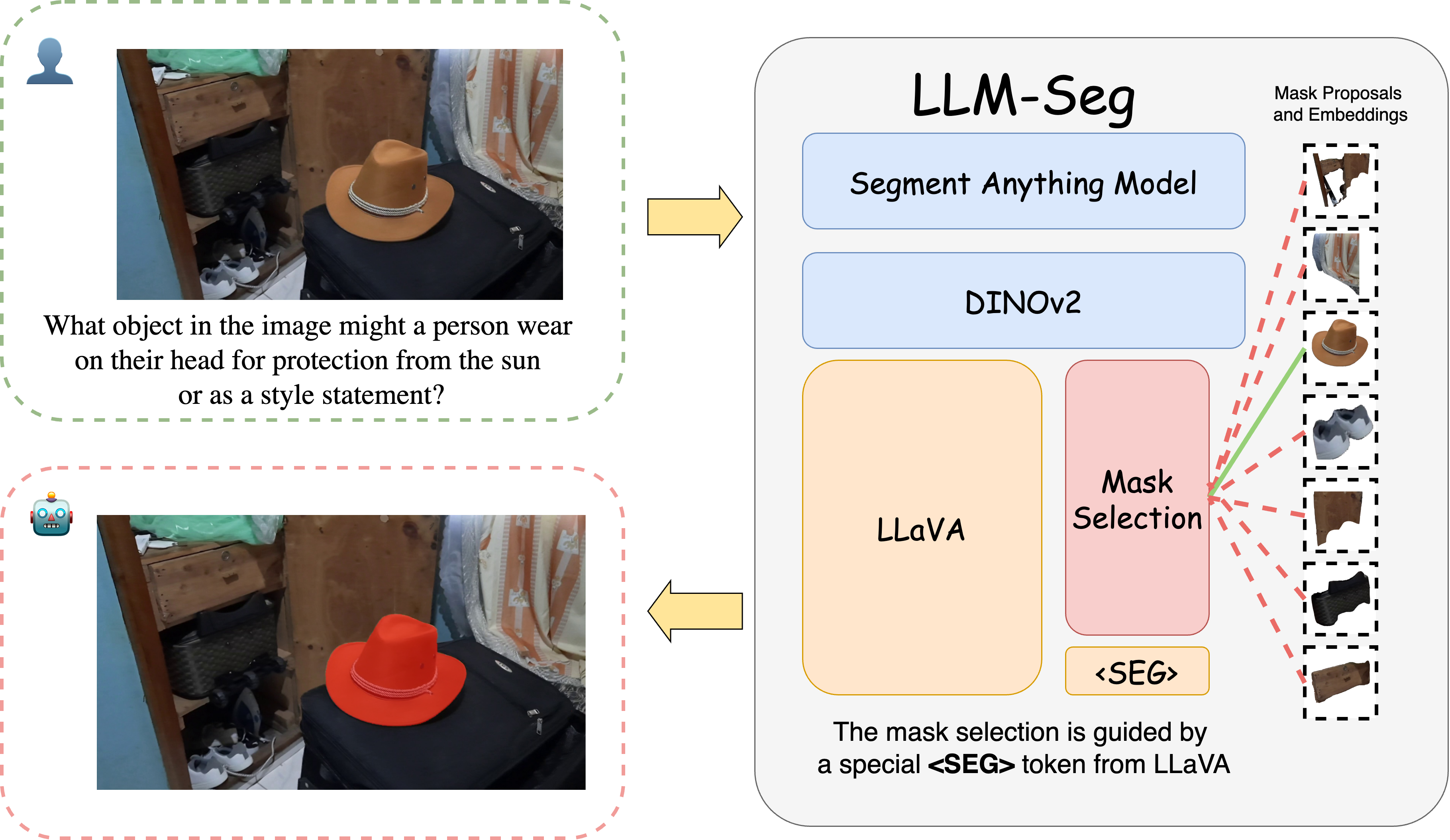
LLM-Seg: Bridging Image Segmentation and Large Language Model Reasoning
Junchi Wang, Lei Ke
0
0
Understanding human instructions to identify the target objects is vital for perception systems. In recent years, the advancements of Large Language Models (LLMs) have introduced new possibilities for image segmentation. In this work, we delve into reasoning segmentation, a novel task that enables segmentation system to reason and interpret implicit user intention via large language model reasoning and then segment the corresponding target. Our work on reasoning segmentation contributes on both the methodological design and dataset labeling. For the model, we propose a new framework named LLM-Seg. LLM-Seg effectively connects the current foundational Segmentation Anything Model and the LLM by mask proposals selection. For the dataset, we propose an automatic data generation pipeline and construct a new reasoning segmentation dataset named LLM-Seg40K. Experiments demonstrate that our LLM-Seg exhibits competitive performance compared with existing methods. Furthermore, our proposed pipeline can efficiently produce high-quality reasoning segmentation datasets. The LLM-Seg40K dataset, developed through this pipeline, serves as a new benchmark for training and evaluating various reasoning segmentation approaches. Our code, models and dataset are at https://github.com/wangjunchi/LLMSeg.
4/16/2024

MG-LLaVA: Towards Multi-Granularity Visual Instruction Tuning
Xiangyu Zhao, Xiangtai Li, Haodong Duan, Haian Huang, Yining Li, Kai Chen, Hua Yang
0
0
Multi-modal large language models (MLLMs) have made significant strides in various visual understanding tasks. However, the majority of these models are constrained to process low-resolution images, which limits their effectiveness in perception tasks that necessitate detailed visual information. In our study, we present MG-LLaVA, an innovative MLLM that enhances the model's visual processing capabilities by incorporating a multi-granularity vision flow, which includes low-resolution, high-resolution, and object-centric features. We propose the integration of an additional high-resolution visual encoder to capture fine-grained details, which are then fused with base visual features through a Conv-Gate fusion network. To further refine the model's object recognition abilities, we incorporate object-level features derived from bounding boxes identified by offline detectors. Being trained solely on publicly available multimodal data through instruction tuning, MG-LLaVA demonstrates exceptional perception skills. We instantiate MG-LLaVA with a wide variety of language encoders, ranging from 3.8B to 34B, to evaluate the model's performance comprehensively. Extensive evaluations across multiple benchmarks demonstrate that MG-LLaVA outperforms existing MLLMs of comparable parameter sizes, showcasing its remarkable efficacy. The code will be available at https://github.com/PhoenixZ810/MG-LLaVA.
6/28/2024
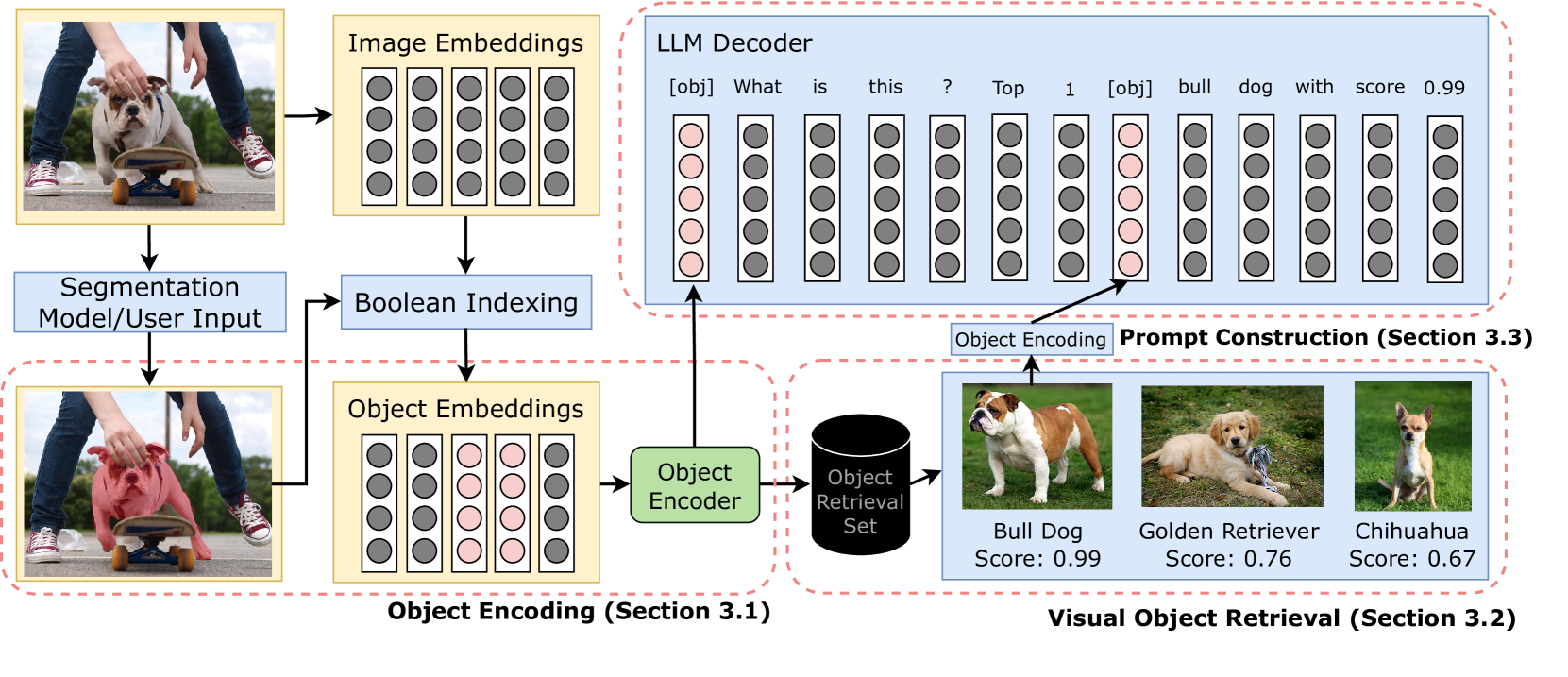
OLIVE: Object Level In-Context Visual Embeddings
Timothy Ossowski, Junjie Hu
0
0
Recent generalist vision-language models (VLMs) have demonstrated impressive reasoning capabilities across diverse multimodal tasks. However, these models still struggle with fine-grained object-level understanding and grounding. In terms of modeling, existing VLMs implicitly align text tokens with image patch tokens, which is ineffective for embedding alignment at the same granularity and inevitably introduces noisy spurious background features. Additionally, these models struggle when generalizing to unseen visual concepts and may not be reliable for domain-specific tasks without further fine-tuning. To address these limitations, we propose a novel method to prompt large language models with in-context visual object vectors, thereby enabling controllable object-level reasoning. This eliminates the necessity of fusing a lengthy array of image patch features and significantly speeds up training. Furthermore, we propose region-level retrieval using our object representations, facilitating rapid adaptation to new objects without additional training. Our experiments reveal that our method achieves competitive referring object classification and captioning performance, while also offering zero-shot generalization and robustness to visually challenging contexts.
6/4/2024
📈
PixelLM: Pixel Reasoning with Large Multimodal Model
Zhongwei Ren, Zhicheng Huang, Yunchao Wei, Yao Zhao, Dongmei Fu, Jiashi Feng, Xiaojie Jin
0
0
While large multimodal models (LMMs) have achieved remarkable progress, generating pixel-level masks for image reasoning tasks involving multiple open-world targets remains a challenge. To bridge this gap, we introduce PixelLM, an effective and efficient LMM for pixel-level reasoning and understanding. Central to PixelLM is a novel, lightweight pixel decoder and a comprehensive segmentation codebook. The decoder efficiently produces masks from the hidden embeddings of the codebook tokens, which encode detailed target-relevant information. With this design, PixelLM harmonizes with the structure of popular LMMs and avoids the need for additional costly segmentation models. Furthermore, we propose a target refinement loss to enhance the model's ability to differentiate between multiple targets, leading to substantially improved mask quality. To advance research in this area, we construct MUSE, a high-quality multi-target reasoning segmentation benchmark. PixelLM excels across various pixel-level image reasoning and understanding tasks, outperforming well-established methods in multiple benchmarks, including MUSE, single- and multi-referring segmentation. Comprehensive ablations confirm the efficacy of each proposed component. All code, models, and datasets will be publicly available.
6/6/2024