OLiVia-Nav: An Online Lifelong Vision Language Approach for Mobile Robot Social Navigation

0
👀
Sign in to get full access
Overview
- Service robots need to navigate while adhering to social norms in human-centered environments like hospitals and care homes.
- They must adapt to new social scenarios that arise during navigation.
- This paper presents a novel approach called OLiVia-Nav that integrates vision-language models with online lifelong learning for socially-compliant robot navigation.
Plain English Explanation
OLiVia-Nav: Online Lifelong Vision-Language Approach for Socially-Compliant Robot Navigation
When robots operate in public spaces like hospitals or care facilities, they need to be able to move around while respecting social rules and making people feel comfortable. This can be challenging as new situations may come up that the robot hasn't encountered before.
The researchers developed a system called OLiVia-Nav that allows robots to navigate in a socially-appropriate way. It uses vision-language models, which are AI systems trained on images and text, to understand the social context of the robot's environment. This helps the robot generate and select navigation paths that comply with social norms.
Importantly, OLiVia-Nav can continuously learn from new situations it encounters, allowing the robot to adapt and improve its social awareness over time. This is done through a technique called lifelong learning, where the robot updates its knowledge as it experiences more real-world scenarios.
The researchers tested OLiVia-Nav in various social navigation settings and found that it outperformed other state-of-the-art methods. It was able to plan paths that minimized violations of people's personal space and generated more socially-compliant trajectories overall.
Technical Explanation
OLiVia-Nav: Online Lifelong Vision-Language Approach for Socially-Compliant Robot Navigation
OLiVia-Nav integrates vision-language models (VLMs) with an online lifelong learning framework to enable robots to navigate in a socially-aware manner. VLMs are AI systems trained on large datasets of images and text, allowing them to understand visual and language information together.
The key innovation in OLiVia-Nav is a novel distillation approach called Social Context Contrastive Language Image Pre-training (SC-CLIP). This transfers the social reasoning capabilities of large VLMs to a smaller, more lightweight VLM that can be deployed on robots. The lightweight VLM can then directly encode social and environmental context during navigation.
The lifelong learning component of OLiVia-Nav allows the system to continuously update the lightweight VLM as the robot encounters new social scenarios. This enables the robot to adapt and improve its social awareness over time.
Extensive real-world experiments showed that OLiVia-Nav outperformed other state-of-the-art methods in metrics like mean squared error, Hausdorff loss, and personal space violation duration. Ablation studies verified the key design choices behind OLiVia-Nav.
Critical Analysis
OLiVia-Nav: Online Lifelong Vision-Language Approach for Socially-Compliant Robot Navigation
The researchers acknowledge that OLiVia-Nav was only tested in limited real-world environments, and further evaluation in more diverse and complex social scenarios would be beneficial. Additionally, the paper does not discuss potential issues around privacy or data bias that could arise from the continuous learning approach.
While the results demonstrate the effectiveness of OLiVia-Nav, it would be valuable to see comparisons to human-level social navigation performance to better understand the system's capabilities and limitations. The paper also does not explore how OLiVia-Nav might scale to handle large, crowded environments or dynamic social situations.
Overall, the OLiVia-Nav approach is a promising step towards developing more socially-aware robots, but further research is needed to address potential challenges and fully realize the benefits of integrating vision-language models and lifelong learning for robot navigation.
Conclusion
OLiVia-Nav: Online Lifelong Vision-Language Approach for Socially-Compliant Robot Navigation
This paper presents OLiVia-Nav, a novel system that combines vision-language models and online lifelong learning to enable robots to navigate in a socially-aware manner. By encoding social and environmental context, OLiVia-Nav can generate navigation paths that comply with social norms and minimize disruptions to people in human-centered spaces.
The key innovations, such as the SC-CLIP distillation approach and the lifelong learning capabilities, allow OLiVia-Nav to adapt to new social scenarios over time. Experimental results demonstrate the effectiveness of this approach compared to other state-of-the-art methods.
As robots become more prevalent in public spaces, developing socially-compliant navigation systems like OLiVia-Nav will be crucial for ensuring the safe and comfortable integration of these technologies into our daily lives. Further research to enhance the scalability and robustness of such systems will be an important next step.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
👀
0
OLiVia-Nav: An Online Lifelong Vision Language Approach for Mobile Robot Social Navigation
Siddarth Narasimhan, Aaron Hao Tan, Daniel Choi, Goldie Nejat
Service robots in human-centered environments such as hospitals, office buildings, and long-term care homes need to navigate while adhering to social norms to ensure the safety and comfortability of the people they are sharing the space with. Furthermore, they need to adapt to new social scenarios that can arise during robot navigation. In this paper, we present a novel Online Lifelong Vision Language architecture, OLiVia-Nav, which uniquely integrates vision-language models (VLMs) with an online lifelong learning framework for robot social navigation. We introduce a unique distillation approach, Social Context Contrastive Language Image Pre-training (SC-CLIP), to transfer the social reasoning capabilities of large VLMs to a lightweight VLM, in order for OLiVia-Nav to directly encode social and environment context during robot navigation. These encoded embeddings are used to generate and select robot social compliant trajectories. The lifelong learning capabilities of SC-CLIP enable OLiVia-Nav to update the lightweight VLM with robot trajectory predictions overtime as new social scenarios are encountered. We conducted extensive real-world experiments in diverse social navigation scenarios. The results showed that OLiVia-Nav outperformed existing state-of-the-art DRL and VLM methods in terms of mean squared error, Hausdorff loss, and personal space violation duration. Ablation studies also verified the design choices for OLiVia-Nav.
Read more9/23/2024
0
VLM-Social-Nav: Socially Aware Robot Navigation through Scoring using Vision-Language Models
Daeun Song, Jing Liang, Amirreza Payandeh, Xuesu Xiao, Dinesh Manocha
We propose VLM-Social-Nav, a novel Vision-Language Model (VLM) based navigation approach to compute a robot's motion in human-centered environments. Our goal is to make real-time decisions on robot actions that are socially compliant with human expectations. We utilize a perception model to detect important social entities and prompt a VLM to generate guidance for socially compliant robot behavior. VLM-Social-Nav uses a VLM-based scoring module that computes a cost term that ensures socially appropriate and effective robot actions generated by the underlying planner. Our overall approach reduces reliance on large training datasets and enhances adaptability in decision-making. In practice, it results in improved socially compliant navigation in human-shared environments. We demonstrate and evaluate our system in four different real-world social navigation scenarios with a Turtlebot robot. We observe at least 27.38% improvement in the average success rate and 19.05% improvement in the average collision rate in the four social navigation scenarios. Our user study score shows that VLM-Social-Nav generates the most socially compliant navigation behavior.
Read more7/9/2024

0
NaVid: Video-based VLM Plans the Next Step for Vision-and-Language Navigation
Jiazhao Zhang, Kunyu Wang, Rongtao Xu, Gengze Zhou, Yicong Hong, Xiaomeng Fang, Qi Wu, Zhizheng Zhang, He Wang
Vision-and-language navigation (VLN) stands as a key research problem of Embodied AI, aiming at enabling agents to navigate in unseen environments following linguistic instructions. In this field, generalization is a long-standing challenge, either to out-of-distribution scenes or from Sim to Real. In this paper, we propose NaVid, a video-based large vision language model (VLM), to mitigate such a generalization gap. NaVid makes the first endeavor to showcase the capability of VLMs to achieve state-of-the-art level navigation performance without any maps, odometers, or depth inputs. Following human instruction, NaVid only requires an on-the-fly video stream from a monocular RGB camera equipped on the robot to output the next-step action. Our formulation mimics how humans navigate and naturally gets rid of the problems introduced by odometer noises, and the Sim2Real gaps from map or depth inputs. Moreover, our video-based approach can effectively encode the historical observations of robots as spatio-temporal contexts for decision making and instruction following. We train NaVid with 510k navigation samples collected from continuous environments, including action-planning and instruction-reasoning samples, along with 763k large-scale web data. Extensive experiments show that NaVid achieves state-of-the-art performance in simulation environments and the real world, demonstrating superior cross-dataset and Sim2Real transfer. We thus believe our proposed VLM approach plans the next step for not only the navigation agents but also this research field.
Read more5/28/2024
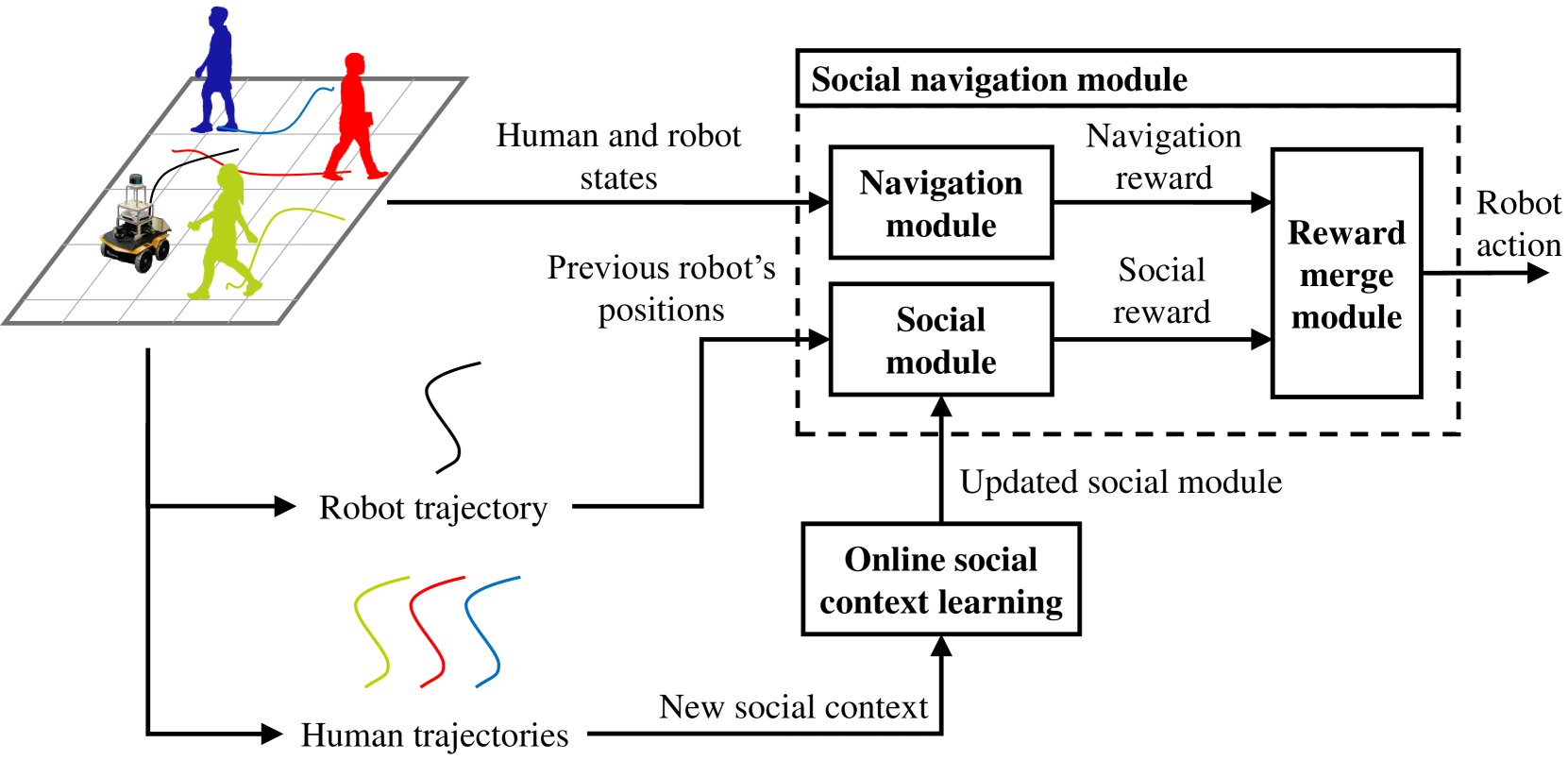
0
Online Context Learning for Socially-compliant Navigation
Iaroslav Okunevich, Alexandre Lombard, Tomas Krajnik, Yassine Ruichek, Zhi Yan
Robot social navigation needs to adapt to different human factors and environmental contexts. However, since these factors and contexts are difficult to predict and cannot be exhaustively enumerated, traditional learning-based methods have difficulty in ensuring the social attributes of robots in long-term and cross-environment deployments. This letter introduces an online context learning method that aims to empower robots to adapt to new social environments online. The proposed method adopts a two-layer structure. The bottom layer is built using a deep reinforcement learning-based method to ensure the output of basic robot navigation commands. The upper layer is implemented using an online robot learning-based method to socialize the control commands suggested by the bottom layer. Experiments using a community-wide simulator show that our method outperforms the state-of-the-art ones. Experimental results in the most challenging scenarios show that our method improves the performance of the state-of-the-art by 8%. The source code of the proposed method, the data used, and the tools for the per-training step will be publicly available at https://github.com/Nedzhaken/SOCSARL-OL.
Read more6/18/2024