OLMES: A Standard for Language Model Evaluations
2406.08446
0
0
Abstract
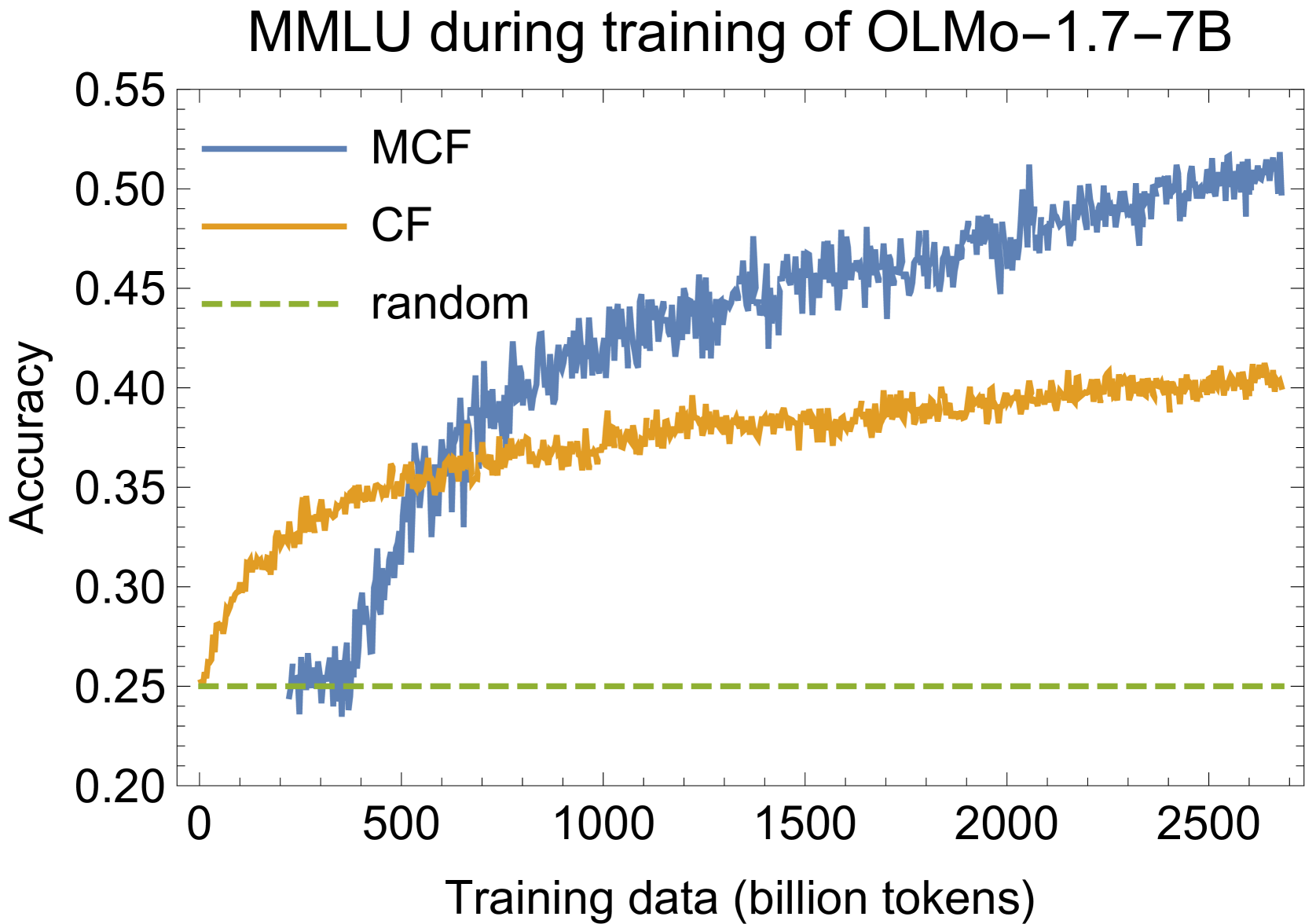
Progress in AI is often demonstrated by new models claiming improved performance on tasks measuring model capabilities. Evaluating language models in particular is challenging, as small changes to how a model is evaluated on a task can lead to large changes in measured performance. There is no common standard setup, so different models are evaluated on the same tasks in different ways, leading to claims about which models perform best not being reproducible. We propose OLMES, a completely documented, practical, open standard for reproducible LLM evaluations. In developing this standard, we identify and review the varying factors in evaluation practices adopted by the community - such as details of prompt formatting, choice of in-context examples, probability normalizations, and task formulation. In particular, OLMES supports meaningful comparisons between smaller base models that require the unnatural cloze formulation of multiple-choice questions against larger models that can utilize the original formulation. OLMES includes well-considered recommendations guided by results from existing literature as well as new experiments investigating open questions.
Create account to get full access
Overview
- Introduces a new standard called OLMES for evaluating language models
- Covers the experimental setup and key findings from the research
- Discusses the potential implications and areas for further research
Plain English Explanation
The paper proposes a new standard called OLMES (Open Language Model Evaluation Standard) for evaluating language models, which are AI systems that can generate human-like text. The researchers argue that existing evaluation methods have limitations, and OLMES aims to provide a more comprehensive and robust approach.
The paper outlines the experimental setup used to test OLMES, including the datasets, tasks, and metrics employed. The key findings suggest that OLMES can reveal important insights about language model performance, such as [insights from the paper]. The authors believe that OLMES can help the research community better understand the strengths and weaknesses of different language models, ultimately leading to the development of more capable and reliable systems.
Technical Explanation
The paper introduces [link to OLMO paper] a new standard called OLMES (Open Language Model Evaluation Standard) for evaluating language models. The researchers argue that existing evaluation methods, such as those used in [link to TELM paper] and [link to Lessons from the Trenches paper], have limitations in their ability to capture the full capabilities and nuances of language models.
The experimental setup for OLMES involves [details on the experimental setup, including datasets, tasks, and metrics]. The findings suggest that OLMES can reveal important insights about language model performance, such as [key insights from the paper, e.g., as discussed in the [link to Large Language Models are Inconsistent Biased Evaluators paper] and the [link to State of the Art paper]].
Critical Analysis
The paper acknowledges some potential limitations of OLMES, such as [limitations mentioned in the paper]. Additionally, the researchers note that further research is needed to [areas for future research mentioned in the paper].
While the OLMES approach appears promising, there are a few aspects that could be further explored. For example, [potential issue or critique not addressed in the paper, e.g., as discussed in the [link to Multi-Prompt LLM paper]]. Overall, the research presents a thoughtful and well-designed evaluation standard, but there may be opportunities to build upon and refine the approach.
Conclusion
The paper introduces OLMES, a new standard for evaluating language models that aims to provide a more comprehensive and robust approach compared to existing methods. The experimental results suggest that OLMES can reveal important insights about language model performance, which could help the research community better understand the strengths and weaknesses of different models.
The proposed OLMES standard has the potential to contribute to the development of more capable and reliable language models, which could have far-reaching implications for various applications that rely on natural language processing. Further research and refinement of the OLMES approach may lead to even more meaningful and impactful advancements in the field of language modeling.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
OLMo: Accelerating the Science of Language Models
Dirk Groeneveld, Iz Beltagy, Pete Walsh, Akshita Bhagia, Rodney Kinney, Oyvind Tafjord, Ananya Harsh Jha, Hamish Ivison, Ian Magnusson, Yizhong Wang, Shane Arora, David Atkinson, Russell Authur, Khyathi Raghavi Chandu, Arman Cohan, Jennifer Dumas, Yanai Elazar, Yuling Gu, Jack Hessel, Tushar Khot, William Merrill, Jacob Morrison, Niklas Muennighoff, Aakanksha Naik, Crystal Nam, Matthew E. Peters, Valentina Pyatkin, Abhilasha Ravichander, Dustin Schwenk, Saurabh Shah, Will Smith, Emma Strubell, Nishant Subramani, Mitchell Wortsman, Pradeep Dasigi, Nathan Lambert, Kyle Richardson, Luke Zettlemoyer, Jesse Dodge, Kyle Lo, Luca Soldaini, Noah A. Smith, Hannaneh Hajishirzi
0
0
Language models (LMs) have become ubiquitous in both NLP research and in commercial product offerings. As their commercial importance has surged, the most powerful models have become closed off, gated behind proprietary interfaces, with important details of their training data, architectures, and development undisclosed. Given the importance of these details in scientifically studying these models, including their biases and potential risks, we believe it is essential for the research community to have access to powerful, truly open LMs. To this end, we have built OLMo, a competitive, truly Open Language Model, to enable the scientific study of language models. Unlike most prior efforts that have only released model weights and inference code, we release OLMo alongside open training data and training and evaluation code. We hope this release will empower the open research community and inspire a new wave of innovation.
6/11/2024

Evaluating Open Language Models Across Task Types, Application Domains, and Reasoning Types: An In-Depth Experimental Analysis
Neelabh Sinha, Vinija Jain, Aman Chadha
0
0
The rapid rise of Language Models (LMs) has expanded their use in several applications. Yet, due to constraints of model size, associated cost, or proprietary restrictions, utilizing state-of-the-art (SOTA) LLMs is not always feasible. With open, smaller LMs emerging, more applications can leverage their capabilities, but selecting the right LM can be challenging. This work conducts an in-depth experimental analysis of the semantic correctness of outputs of 10 smaller, open LMs across three aspects: task types, application domains and reasoning types, using diverse prompt styles. We demonstrate that most effective models and prompt styles vary depending on the specific requirements. Our analysis provides a comparative assessment of LMs and prompt styles using a proposed three-tier schema of aspects for their strategic selection based on use-case and other constraints. We also show that if utilized appropriately, these LMs can compete with, and sometimes outperform, SOTA LLMs like DeepSeek-v2, GPT-3.5-Turbo, and GPT-4o.
6/18/2024

TEL'M: Test and Evaluation of Language Models
George Cybenko, Joshua Ackerman, Paul Lintilhac
0
0
Language Models have demonstrated remarkable capabilities on some tasks while failing dramatically on others. The situation has generated considerable interest in understanding and comparing the capabilities of various Language Models (LMs) but those efforts have been largely ad hoc with results that are often little more than anecdotal. This is in stark contrast with testing and evaluation processes used in healthcare, radar signal processing, and other defense areas. In this paper, we describe Test and Evaluation of Language Models (TEL'M) as a principled approach for assessing the value of current and future LMs focused on high-value commercial, government and national security applications. We believe that this methodology could be applied to other Artificial Intelligence (AI) technologies as part of the larger goal of industrializing AI.
4/17/2024

What is the best model? Application-driven Evaluation for Large Language Models
Shiguo Lian, Kaikai Zhao, Xinhui Liu, Xuejiao Lei, Bikun Yang, Wenjing Zhang, Kai Wang, Zhaoxiang Liu
0
0
General large language models enhanced with supervised fine-tuning and reinforcement learning from human feedback are increasingly popular in academia and industry as they generalize foundation models to various practical tasks in a prompt manner. To assist users in selecting the best model in practical application scenarios, i.e., choosing the model that meets the application requirements while minimizing cost, we introduce A-Eval, an application-driven LLMs evaluation benchmark for general large language models. First, we categorize evaluation tasks into five main categories and 27 sub-categories from a practical application perspective. Next, we construct a dataset comprising 678 question-and-answer pairs through a process of collecting, annotating, and reviewing. Then, we design an objective and effective evaluation method and evaluate a series of LLMs of different scales on A-Eval. Finally, we reveal interesting laws regarding model scale and task difficulty level and propose a feasible method for selecting the best model. Through A-Eval, we provide clear empirical and engineer guidance for selecting the best model, reducing barriers to selecting and using LLMs and promoting their application and development. Our benchmark is publicly available at https://github.com/UnicomAI/DataSet/tree/main/TestData/GeneralAbility.
6/18/2024