OLMo: Accelerating the Science of Language Models
2402.00838
0
0
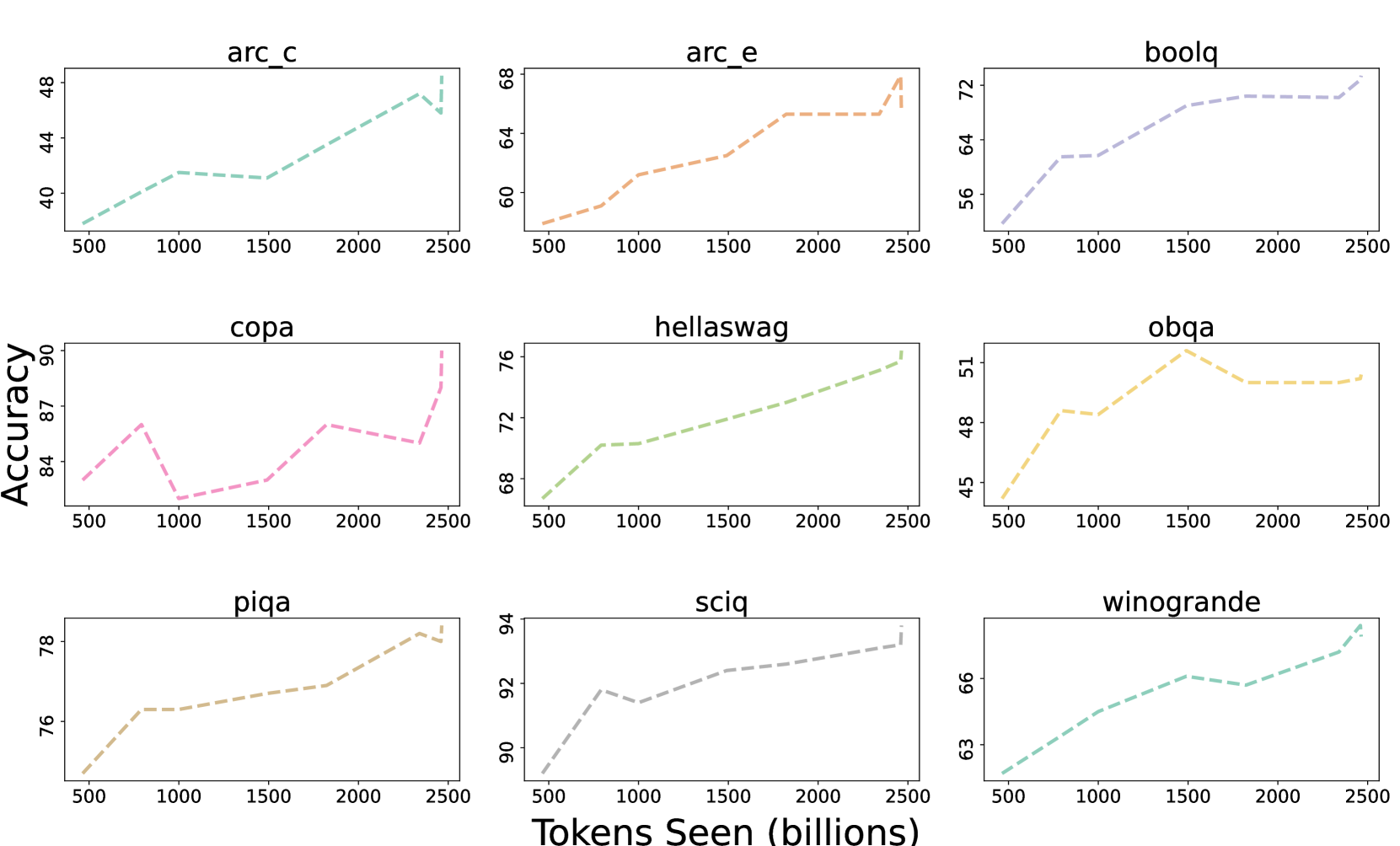
Abstract
Language models (LMs) have become ubiquitous in both NLP research and in commercial product offerings. As their commercial importance has surged, the most powerful models have become closed off, gated behind proprietary interfaces, with important details of their training data, architectures, and development undisclosed. Given the importance of these details in scientifically studying these models, including their biases and potential risks, we believe it is essential for the research community to have access to powerful, truly open LMs. To this end, we have built OLMo, a competitive, truly Open Language Model, to enable the scientific study of language models. Unlike most prior efforts that have only released model weights and inference code, we release OLMo alongside open training data and training and evaluation code. We hope this release will empower the open research community and inspire a new wave of innovation.
Create account to get full access
Overview
- The paper introduces a new framework called OLMo (Open Language Model) that aims to accelerate the development and research of large language models.
- OLMo provides a modular and extensible architecture that allows for easy experimentation and comparison of different components and techniques.
- The framework enables researchers to rapidly prototype and test new ideas, accelerating the progress of language model science.
Plain English Explanation
OLMo: Accelerating the Science of Language Models is a research paper that presents a new framework called OLMo, which is designed to make it easier and faster to develop and experiment with large language models. Language models are AI systems that can understand and generate human-like text, and they are the foundation for many advanced language-based applications.
The key idea behind OLMo is to create a modular and flexible system that allows researchers to quickly try out new ideas and techniques for improving language models. Rather than having to build everything from scratch, OLMo provides a standardized set of components and tools that can be easily combined and tested.
This modular approach makes it possible to rapidly prototype and evaluate new model architectures, training methods, and other innovations. By accelerating the research and development process, OLMo aims to drive faster progress in the field of language modeling, leading to more capable and useful language models.
The paper also discusses how OLMo can help address some of the challenges and limitations of current language models, such as their high computational cost, lack of transparency, and potential for bias. By providing a more flexible and accessible framework, OLMo may pave the way for the development of more efficient, transparent, and capable language models that can be more widely adopted and integrated into a variety of applications.
Overall, the OLMo framework represents an important step forward in the quest to make large language models more accessible and impactful, and the paper offers a compelling vision for how to accelerate the science of language models.
Technical Explanation
OLMo: Accelerating the Science of Language Models introduces a new framework called OLMo (Open Language Model) that aims to facilitate the research and development of large language models.
The key features of the OLMo framework include:
-
Modular Architecture: OLMo is designed with a modular and extensible architecture, allowing researchers to easily experiment with different components and techniques. This includes the ability to quickly swap out and test various model architectures, training methods, and other modules.
-
Rapid Prototyping: The modular design of OLMo enables researchers to rapidly prototype and test new ideas, accelerating the pace of language model research and development. This can lead to faster progress in the field compared to traditional approaches.
-
Standardization and Benchmarking: OLMo provides a standardized set of tools and benchmarks, making it easier to compare the performance and capabilities of different language models. This can help drive more rigorous and objective evaluation of new techniques and innovations.
-
Transparency and Interpretability: The paper discusses how OLMo can be designed to improve the transparency and interpretability of language models, addressing some of the challenges with current black-box systems. This could lead to more trustworthy and accountable language models.
The paper also presents a detailed technical description of the OLMo architecture, including its key components, data and model management, and the overall workflow for training and evaluating language models within the framework.
Critical Analysis
The OLMo framework presented in the paper offers a promising approach to accelerating language model research, but it also raises some potential concerns and areas for further exploration:
Limitations and Caveats:
- The paper does not provide a comprehensive evaluation of the performance and capabilities of OLMo-based models compared to state-of-the-art language models. More empirical evidence is needed to assess the actual impact of the framework.
- The paper focuses on the technical aspects of OLMo, but it does not delve deeply into the practical challenges of deploying and maintaining such a complex system in real-world applications.
- The paper does not address potential issues around the ethical and social implications of rapidly developing more capable language models, such as concerns about bias, misinformation, and the displacement of human labor.
Further Research:
- Exploring ways to further improve the transparency and interpretability of OLMo-based models, beyond the high-level concepts discussed in the paper.
- Investigating how OLMo can be extended to support the development of multilingual and multimodal language models, which are becoming increasingly important for real-world applications.
- Analyzing the computational and energy efficiency of OLMo-based models, and how the framework can be optimized to reduce the environmental impact of large language model development and deployment.
Overall, the OLMo framework represents an important step forward in the field of language model research, but continued critical examination and incremental improvements will be necessary to realize its full potential and address the complex challenges involved in developing advanced AI systems.
Conclusion
The OLMo: Accelerating the Science of Language Models paper presents a novel framework that aims to drive faster progress in the development and research of large language models. By providing a modular and extensible architecture, OLMo enables researchers to quickly prototype and test new ideas, leading to more rapid innovation in the field.
The key innovation of OLMo is its ability to facilitate the exploration of different model components, training techniques, and other advancements, making it easier to compare and evaluate the performance and capabilities of various approaches. This could ultimately lead to the creation of more efficient, transparent, and capable language models that can be more widely adopted and integrated into a variety of real-world applications.
While the OLMo framework shows promising potential, the paper also highlights the need for continued critical analysis and further research to address potential limitations and ensure the responsible development of these powerful AI systems. By fostering a more collaborative and open approach to language model research, OLMo can play a key role in accelerating the science of language models and unlocking their transformative potential for the benefit of society.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
💬
OpenELM: An Efficient Language Model Family with Open-source Training and Inference Framework
Sachin Mehta, Mohammad Hossein Sekhavat, Qingqing Cao, Maxwell Horton, Yanzi Jin, Chenfan Sun, Iman Mirzadeh, Mahyar Najibi, Dmitry Belenko, Peter Zatloukal, Mohammad Rastegari
0
0
The reproducibility and transparency of large language models are crucial for advancing open research, ensuring the trustworthiness of results, and enabling investigations into data and model biases, as well as potential risks. To this end, we release OpenELM, a state-of-the-art open language model. OpenELM uses a layer-wise scaling strategy to efficiently allocate parameters within each layer of the transformer model, leading to enhanced accuracy. For example, with a parameter budget of approximately one billion parameters, OpenELM exhibits a 2.36% improvement in accuracy compared to OLMo while requiring $2times$ fewer pre-training tokens. Diverging from prior practices that only provide model weights and inference code, and pre-train on private datasets, our release includes the complete framework for training and evaluation of the language model on publicly available datasets, including training logs, multiple checkpoints, and pre-training configurations. We also release code to convert models to MLX library for inference and fine-tuning on Apple devices. This comprehensive release aims to empower and strengthen the open research community, paving the way for future open research endeavors. Our source code along with pre-trained model weights and training recipes is available at url{https://github.com/apple/corenet}. Additionally, model models can be found on HuggingFace at: url{https://huggingface.co/apple/OpenELM}.
5/3/2024
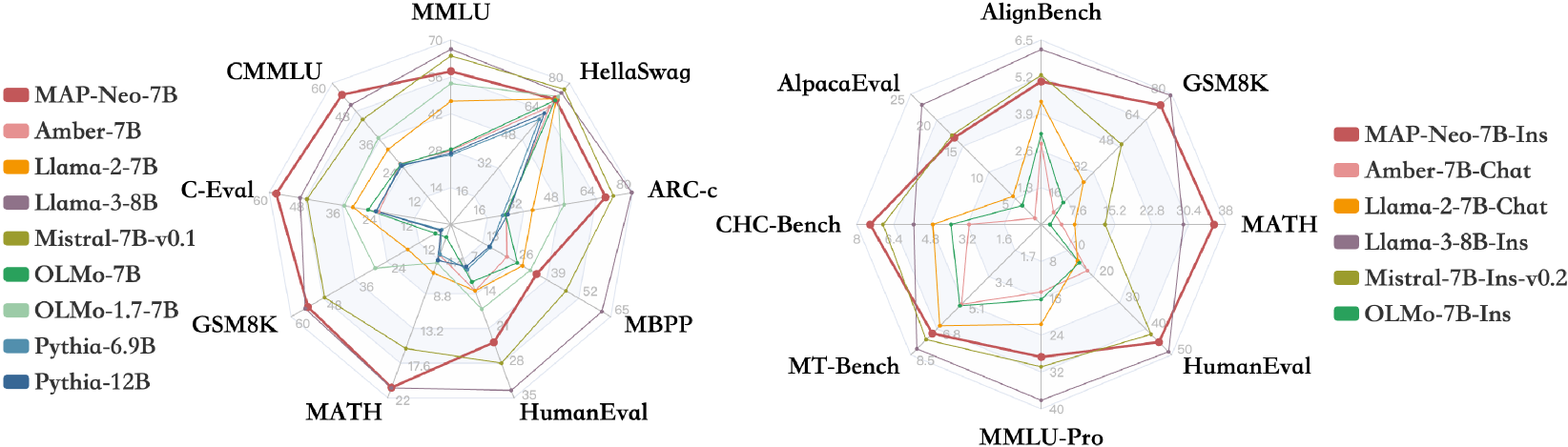
MAP-Neo: Highly Capable and Transparent Bilingual Large Language Model Series
Ge Zhang, Scott Qu, Jiaheng Liu, Chenchen Zhang, Chenghua Lin, Chou Leuang Yu, Danny Pan, Esther Cheng, Jie Liu, Qunshu Lin, Raven Yuan, Tuney Zheng, Wei Pang, Xinrun Du, Yiming Liang, Yinghao Ma, Yizhi Li, Ziyang Ma, Bill Lin, Emmanouil Benetos, Huan Yang, Junting Zhou, Kaijing Ma, Minghao Liu, Morry Niu, Noah Wang, Quehry Que, Ruibo Liu, Sine Liu, Shawn Guo, Soren Gao, Wangchunshu Zhou, Xinyue Zhang, Yizhi Zhou, Yubo Wang, Yuelin Bai, Yuhan Zhang, Yuxiang Zhang, Zenith Wang, Zhenzhu Yang, Zijian Zhao, Jiajun Zhang, Wanli Ouyang, Wenhao Huang, Wenhu Chen
0
0
Large Language Models (LLMs) have made great strides in recent years to achieve unprecedented performance across different tasks. However, due to commercial interest, the most competitive models like GPT, Gemini, and Claude have been gated behind proprietary interfaces without disclosing the training details. Recently, many institutions have open-sourced several strong LLMs like LLaMA-3, comparable to existing closed-source LLMs. However, only the model's weights are provided with most details (e.g., intermediate checkpoints, pre-training corpus, and training code, etc.) being undisclosed. To improve the transparency of LLMs, the research community has formed to open-source truly open LLMs (e.g., Pythia, Amber, OLMo), where more details (e.g., pre-training corpus and training code) are being provided. These models have greatly advanced the scientific study of these large models including their strengths, weaknesses, biases and risks. However, we observe that the existing truly open LLMs on reasoning, knowledge, and coding tasks are still inferior to existing state-of-the-art LLMs with similar model sizes. To this end, we open-source MAP-Neo, a highly capable and transparent bilingual language model with 7B parameters trained from scratch on 4.5T high-quality tokens. Our MAP-Neo is the first fully open-sourced bilingual LLM with comparable performance compared to existing state-of-the-art LLMs. Moreover, we open-source all details to reproduce our MAP-Neo, where the cleaned pre-training corpus, data cleaning pipeline, checkpoints, and well-optimized training/evaluation framework are provided. Finally, we hope our MAP-Neo will enhance and strengthen the open research community and inspire more innovations and creativities to facilitate the further improvements of LLMs.
6/4/2024
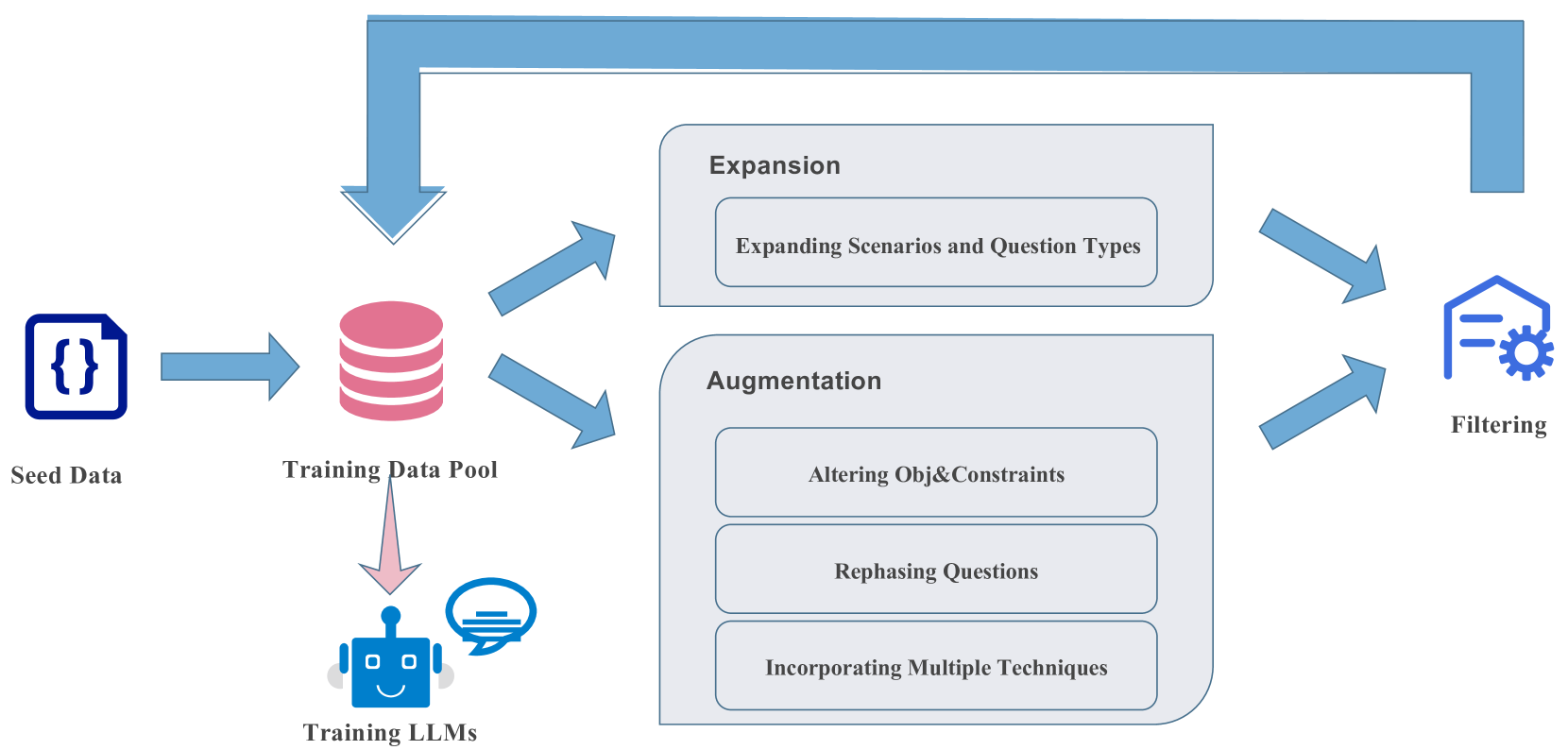
ORLM: Training Large Language Models for Optimization Modeling
Zhengyang Tang, Chenyu Huang, Xin Zheng, Shixi Hu, Zizhuo Wang, Dongdong Ge, Benyou Wang
0
0
Large Language Models (LLMs) have emerged as powerful tools for tackling complex Operations Research (OR) problem by providing the capacity in automating optimization modeling. However, current methodologies heavily rely on prompt engineering (e.g., multi-agent cooperation) with proprietary LLMs, raising data privacy concerns that could be prohibitive in industry applications. To tackle this issue, we propose training open-source LLMs for optimization modeling. We identify four critical requirements for the training dataset of OR LLMs, design and implement OR-Instruct, a semi-automated process for creating synthetic data tailored to specific requirements. We also introduce the IndustryOR benchmark, the first industrial benchmark for testing LLMs on solving real-world OR problems. We apply the data from OR-Instruct to various open-source LLMs of 7b size (termed as ORLMs), resulting in a significantly improved capability for optimization modeling. Our best-performing ORLM achieves state-of-the-art performance on the NL4OPT, MAMO, and IndustryOR benchmarks. Our code and data are available at url{https://github.com/Cardinal-Operations/ORLM}.
5/31/2024
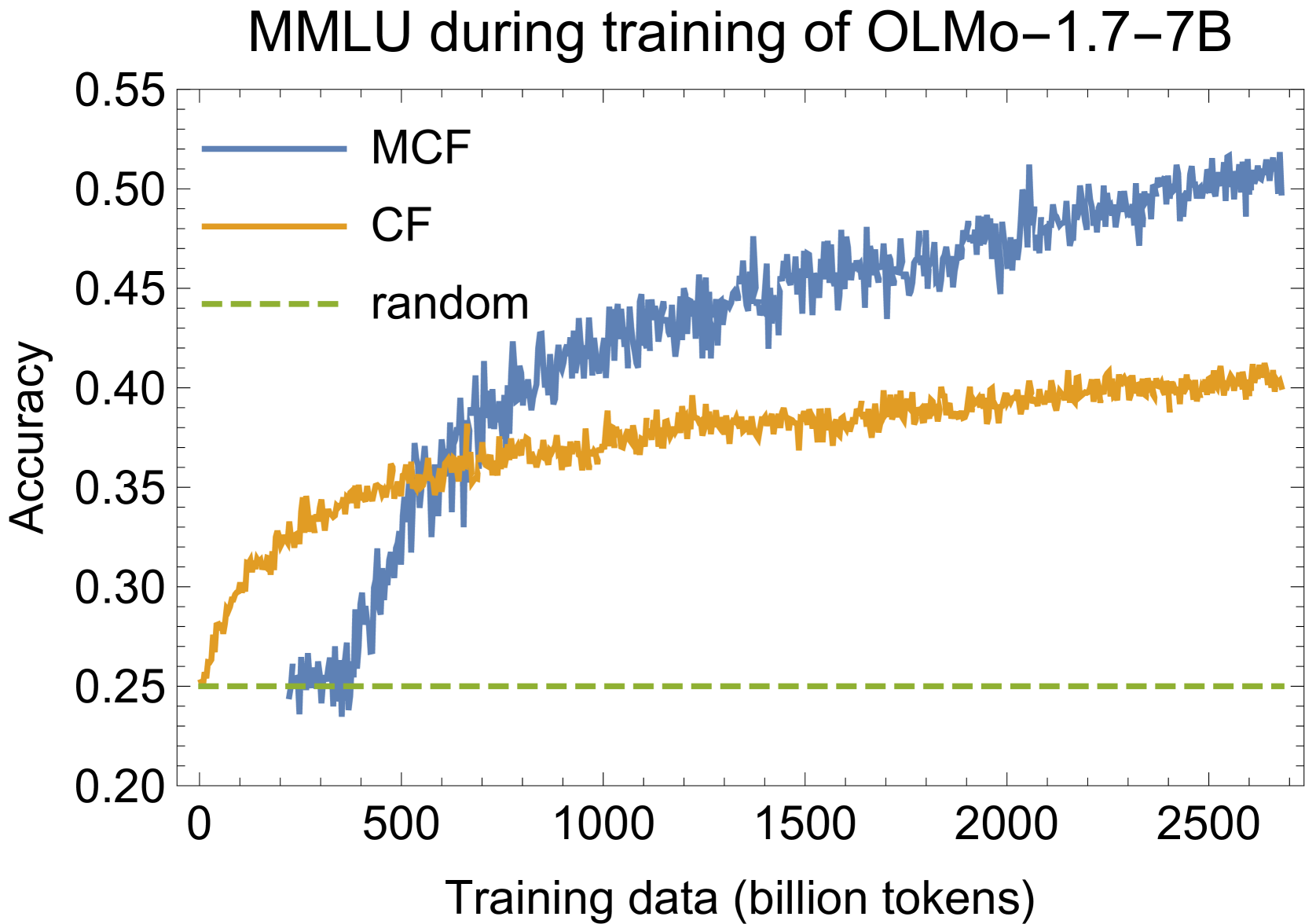
OLMES: A Standard for Language Model Evaluations
Yuling Gu, Oyvind Tafjord, Bailey Kuehl, Dany Haddad, Jesse Dodge, Hannaneh Hajishirzi
0
0
Progress in AI is often demonstrated by new models claiming improved performance on tasks measuring model capabilities. Evaluating language models in particular is challenging, as small changes to how a model is evaluated on a task can lead to large changes in measured performance. There is no common standard setup, so different models are evaluated on the same tasks in different ways, leading to claims about which models perform best not being reproducible. We propose OLMES, a completely documented, practical, open standard for reproducible LLM evaluations. In developing this standard, we identify and review the varying factors in evaluation practices adopted by the community - such as details of prompt formatting, choice of in-context examples, probability normalizations, and task formulation. In particular, OLMES supports meaningful comparisons between smaller base models that require the unnatural cloze formulation of multiple-choice questions against larger models that can utilize the original formulation. OLMES includes well-considered recommendations guided by results from existing literature as well as new experiments investigating open questions.
6/13/2024