OmniCorpus: An Unified Multimodal Corpus of 10 Billion-Level Images Interleaved with Text
2406.08418
0
0
🤖
Abstract
Image-text interleaved data, consisting of multiple images and texts arranged in a natural document format, aligns with the presentation paradigm of internet data and closely resembles human reading habits. Recent studies have shown that such data aids multimodal in-context learning and maintains the capabilities of large language models during multimodal fine-tuning. However, the limited scale and diversity of current image-text interleaved data restrict the development of multimodal large language models. In this paper, we introduce OmniCorpus, a 10 billion-scale image-text interleaved dataset. Using an efficient data engine, we filter and extract large-scale high-quality documents, which contain 8.6 billion images and 1,696 billion text tokens. Compared to counterparts (e.g., MMC4, OBELICS), our dataset 1) has 15 times larger scales while maintaining good data quality; 2) features more diverse sources, including both English and non-English websites as well as video-centric websites; 3) is more flexible, easily degradable from an image-text interleaved format to pure text corpus and image-text pairs. Through comprehensive analysis and experiments, we validate the quality, usability, and effectiveness of the proposed dataset. We hope this could provide a solid data foundation for future multimodal model research. Code and data are released at https://github.com/OpenGVLab/OmniCorpus.
Create account to get full access
Overview
- This paper presents a technical report on the Omnifusion model, which aims to develop a unified framework for multimodal language modeling that can effectively leverage both text and visual data.
- The paper also discusses the CapsFusion model, which rethinks the way image-text data is scaled and processed for large-scale multimodal language models.
- Additionally, the paper introduces the TRINS model, which explores ways to build multimodal language models that can understand and generate both text and visual content.
- Finally, the paper examines a vision model pre-training approach that interleaves image and text data to improve the model's ability to reason about visual and linguistic information simultaneously.
Plain English Explanation
The researchers in this paper are working on developing more advanced AI systems that can understand and process both text and visual information, like images or videos. The key idea is to create a single, unified framework that can effectively use both types of data to improve the AI's overall language understanding and generation capabilities.
One of the models they present, called Omnifusion, tries to bring together text and visual data in a smart way so the AI can learn more from them together than it could from each one separately. Another model, CapsFusion, rethinks how we can efficiently scale up the amount of image-text data that these large language models are trained on.
The TRINS model explores new ways to build AI systems that can not only understand both text and visuals, but also generate them - for example, being able to describe an image in words or create an image based on text.
Finally, the researchers look at a technique called vision model pre-training, which trains the AI on a mix of text and visual data to help it learn to reason about the connections between language and the visual world. This could lead to AIs that have a deeper, more holistic understanding of the information they're working with.
Overall, these papers are tackling the challenge of building AI systems that can truly understand and work with the rich, multimodal information that humans naturally process, which could unlock new capabilities for language AI.
Technical Explanation
The Omnifusion technical report presents a unified framework for multimodal language modeling that aims to effectively leverage both text and visual data. The core idea is to develop a single model that can learn from and reason about information across multiple modalities, rather than treating text and vision as separate tasks.
The CapsFusion paper introduces a new approach to scaling image-text data for large-scale multimodal language models. Rather than relying on traditional image captioning datasets, the authors propose a "rethinking" of how this data is collected and processed to better capture the nuances of real-world language use.
The TRINS model explores ways to build multimodal language models that can not only understand both text and visual content, but also generate them. This involves developing techniques to allow the model to seamlessly transition between text, image, and even other modalities like video.
Finally, the vision model pre-training paper examines an approach that interleaves image and text data during the pre-training phase. This is hypothesized to help the model better learn the connections between linguistic and visual information, leading to improved reasoning and generation capabilities.
Critical Analysis
The papers present promising directions for advancing multimodal language modeling, but also acknowledge several caveats and areas for further research. For example, the Omnifusion technical report notes that effectively fusing text and vision remains a significant challenge, and more work is needed to understand the optimal ways to represent and integrate these modalities.
The CapsFusion paper raises valid concerns about the limitations of existing image captioning datasets and the need for more nuanced, real-world data to train large-scale multimodal models. However, the feasibility and scalability of their proposed data collection approach may warrant further investigation.
While the TRINS model demonstrates promising results in understanding and generating text and visual content, the paper acknowledges the challenge of maintaining coherence and consistency across modalities, which could be an area for future research.
The vision model pre-training paper presents a compelling approach, but the long-term impacts of this interleaved pre-training strategy on the model's performance and robustness across diverse tasks and datasets remain to be explored.
Overall, these papers make valuable contributions to the field of multimodal language modeling, but also highlight the need for continued research to address the complex challenges in fully realizing the potential of AI systems that can seamlessly understand and generate content across multiple modalities.
Conclusion
The papers presented in this technical report showcase innovative approaches to developing more advanced multimodal language models. By focusing on ways to effectively fuse text and visual data, scale image-text datasets, enable cross-modal understanding and generation, and leverage interleaved pre-training, the researchers are pushing the boundaries of what's possible in the field of multimodal AI.
These advancements could have far-reaching implications, from improving the natural language understanding and generation capabilities of AI assistants to enhancing the way humans and machines interact with and interpret information across different modalities. As the field of multimodal language modeling continues to evolve, these papers provide valuable insights and set the stage for future breakthroughs in this rapidly advancing area of AI research.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

CoMM: A Coherent Interleaved Image-Text Dataset for Multimodal Understanding and Generation
Wei Chen, Lin Li, Yongqi Yang, Bin Wen, Fan Yang, Tingting Gao, Yu Wu, Long Chen
0
0
Interleaved image-text generation has emerged as a crucial multimodal task, aiming at creating sequences of interleaved visual and textual content given a query. Despite notable advancements in recent multimodal large language models (MLLMs), generating integrated image-text sequences that exhibit narrative coherence and entity and style consistency remains challenging due to poor training data quality. To address this gap, we introduce CoMM, a high-quality Coherent interleaved image-text MultiModal dataset designed to enhance the coherence, consistency, and alignment of generated multimodal content. Initially, CoMM harnesses raw data from diverse sources, focusing on instructional content and visual storytelling, establishing a foundation for coherent and consistent content. To further refine the data quality, we devise a multi-perspective filter strategy that leverages advanced pre-trained models to ensure the development of sentences, consistency of inserted images, and semantic alignment between them. Various quality evaluation metrics are designed to prove the high quality of the filtered dataset. Meanwhile, extensive few-shot experiments on various downstream tasks demonstrate CoMM's effectiveness in significantly enhancing the in-context learning capabilities of MLLMs. Moreover, we propose four new tasks to evaluate MLLMs' interleaved generation abilities, supported by a comprehensive evaluation framework. We believe CoMM opens a new avenue for advanced MLLMs with superior multimodal in-context learning and understanding ability.
6/18/2024

mOSCAR: A Large-scale Multilingual and Multimodal Document-level Corpus
Matthieu Futeral, Armel Zebaze, Pedro Ortiz Suarez, Julien Abadji, R'emi Lacroix, Cordelia Schmid, Rachel Bawden, Beno^it Sagot
0
0
Multimodal Large Language Models (mLLMs) are trained on a large amount of text-image data. While most mLLMs are trained on caption-like data only, Alayrac et al. [2022] showed that additionally training them on interleaved sequences of text and images can lead to the emergence of in-context learning capabilities. However, the dataset they used, M3W, is not public and is only in English. There have been attempts to reproduce their results but the released datasets are English-only. In contrast, current multilingual and multimodal datasets are either composed of caption-like only or medium-scale or fully private data. This limits mLLM research for the 7,000 other languages spoken in the world. We therefore introduce mOSCAR, to the best of our knowledge the first large-scale multilingual and multimodal document corpus crawled from the web. It covers 163 languages, 315M documents, 214B tokens and 1.2B images. We carefully conduct a set of filtering and evaluation steps to make sure mOSCAR is sufficiently safe, diverse and of good quality. We additionally train two types of multilingual model to prove the benefits of mOSCAR: (1) a model trained on a subset of mOSCAR and captioning data and (2) a model train on captioning data only. The model additionally trained on mOSCAR shows a strong boost in few-shot learning performance across various multilingual image-text tasks and benchmarks, confirming previous findings for English-only mLLMs.
6/14/2024

MINT-1T: Scaling Open-Source Multimodal Data by 10x: A Multimodal Dataset with One Trillion Tokens
Anas Awadalla, Le Xue, Oscar Lo, Manli Shu, Hannah Lee, Etash Kumar Guha, Matt Jordan, Sheng Shen, Mohamed Awadalla, Silvio Savarese, Caiming Xiong, Ran Xu, Yejin Choi, Ludwig Schmidt
0
0
Multimodal interleaved datasets featuring free-form interleaved sequences of images and text are crucial for training frontier large multimodal models (LMMs). Despite the rapid progression of open-source LMMs, there remains a pronounced scarcity of large-scale, diverse open-source multimodal interleaved datasets. In response, we introduce MINT-1T, the most extensive and diverse open-source Multimodal INTerleaved dataset to date. MINT-1T comprises one trillion text tokens and three billion images, a 10x scale-up from existing open-source datasets. Additionally, we include previously untapped sources such as PDFs and ArXiv papers. As scaling multimodal interleaved datasets requires substantial engineering effort, sharing the data curation process and releasing the dataset greatly benefits the community. Our experiments show that LMMs trained on MINT-1T rival the performance of models trained on the previous leading dataset, OBELICS. Our data and code will be released at https://github.com/mlfoundations/MINT-1T.
6/18/2024
OmniFusion Technical Report
Elizaveta Goncharova, Anton Razzhigaev, Matvey Mikhalchuk, Maxim Kurkin, Irina Abdullaeva, Matvey Skripkin, Ivan Oseledets, Denis Dimitrov, Andrey Kuznetsov
0
0
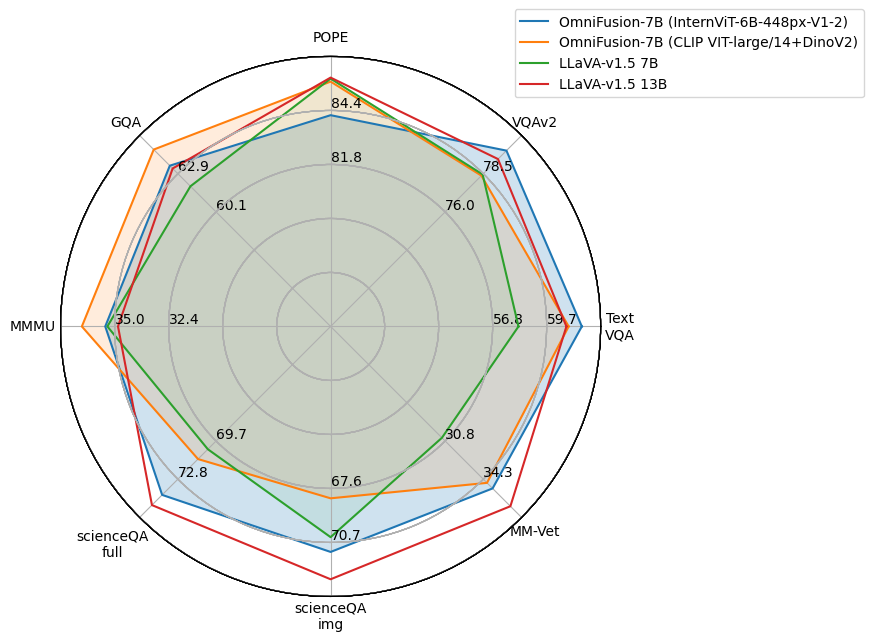
Last year, multimodal architectures served up a revolution in AI-based approaches and solutions, extending the capabilities of large language models (LLM). We propose an textit{OmniFusion} model based on a pretrained LLM and adapters for visual modality. We evaluated and compared several architecture design principles for better text and visual data coupling: MLP and transformer adapters, various CLIP ViT-based encoders (SigLIP, InternVIT, etc.), and their fusing approach, image encoding method (whole image or tiles encoding) and two 7B LLMs (the proprietary one and open-source Mistral). Experiments on 8 visual-language benchmarks show the top score for the best OmniFusion setup in terms of different VQA tasks in comparison with open-source LLaVA-like solutions: VizWiz, Pope, MM-Vet, ScienceQA, MMBench, TextVQA, VQAv2, MMMU. We also propose a variety of situations, where OmniFusion provides highly-detailed answers in different domains: housekeeping, sightseeing, culture, medicine, handwritten and scanned equations recognition, etc. Mistral-based OmniFusion model is an open-source solution with weights, training and inference scripts available at https://github.com/AIRI-Institute/OmniFusion.
4/10/2024