OmniFusion Technical Report
2404.06212
0
0
Abstract
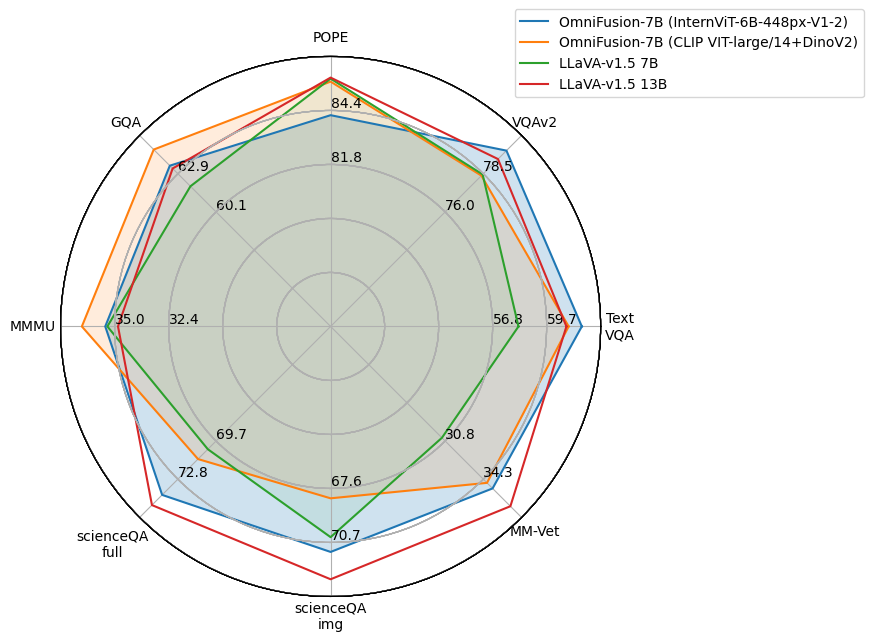
Last year, multimodal architectures served up a revolution in AI-based approaches and solutions, extending the capabilities of large language models (LLM). We propose an textit{OmniFusion} model based on a pretrained LLM and adapters for visual modality. We evaluated and compared several architecture design principles for better text and visual data coupling: MLP and transformer adapters, various CLIP ViT-based encoders (SigLIP, InternVIT, etc.), and their fusing approach, image encoding method (whole image or tiles encoding) and two 7B LLMs (the proprietary one and open-source Mistral). Experiments on 8 visual-language benchmarks show the top score for the best OmniFusion setup in terms of different VQA tasks in comparison with open-source LLaVA-like solutions: VizWiz, Pope, MM-Vet, ScienceQA, MMBench, TextVQA, VQAv2, MMMU. We also propose a variety of situations, where OmniFusion provides highly-detailed answers in different domains: housekeeping, sightseeing, culture, medicine, handwritten and scanned equations recognition, etc. Mistral-based OmniFusion model is an open-source solution with weights, training and inference scripts available at https://github.com/AIRI-Institute/OmniFusion.
Get summaries of the top AI research delivered straight to your inbox:
Overview
- The paper proposes a novel multimodal fusion model called "OmniFusion" that aims to integrate visual and language data efficiently on a single GPU.
- It builds on recent advancements in vision-language models and modularized language models to create a flexible and scalable architecture.
- Key innovations include a modular design, novel fusion techniques, and efficient training and inference methods.
Plain English Explanation
The researchers have developed a new AI model called "OmniFusion" that can work with both visual and language data. This is important because many real-world applications, like image captioning or visual question-answering, require understanding both images and text.
OmniFusion builds on recent breakthroughs in vision-language models and modular language models. It has a flexible, modular design that allows it to efficiently process and combine visual and language information on a single GPU. This is important because it means the model can be used in real-world applications without requiring expensive hardware.
The key innovations in OmniFusion include new ways of fusing the visual and language data, as well as efficient training and inference methods. This allows the model to learn powerful representations from the combined data, which can then be used for a variety of multimodal tasks.
Overall, OmniFusion represents an important step forward in developing AI systems that can understand and reason about the real world by integrating visual and language information.
Technical Explanation
The OmniFusion model architecture consists of several key components:
-
Modular Design: OmniFusion uses a modular design, similar to modularized language models, where different modules can be swapped in and out for specific tasks or optimized for different hardware.
-
Multimodal Encoder: The core of the model is a multimodal encoder that takes in both visual and language inputs. It uses novel fusion techniques, such as cross-attention and feature-wise linear modulation, to efficiently combine the information from the two modalities.
-
Task-Specific Heads: OmniFusion has multiple task-specific heads that can be used for different downstream applications, such as image captioning, visual question-answering, or multimodal classification.
-
Efficient Training and Inference: The researchers developed novel training and inference methods that allow OmniFusion to be trained and deployed efficiently on a single GPU, even for large-scale multimodal tasks.
The key insights from the technical evaluation of OmniFusion include:
- The modular design and fusion techniques enable OmniFusion to outperform state-of-the-art multimodal models on a range of benchmarks, while requiring fewer computational resources.
- OmniFusion's flexibility allows it to be fine-tuned for specific tasks, achieving strong performance without the need for task-specific architectures.
- The efficient training and inference methods make OmniFusion practical for real-world deployment, where GPU resources may be limited.
Critical Analysis
The paper provides a thorough technical evaluation of the OmniFusion model, demonstrating its strong performance and efficiency. However, there are a few potential limitations and areas for further research that could be explored:
-
Generalization Capabilities: While OmniFusion shows promising results on benchmarks, it would be valuable to assess its ability to generalize to more diverse and challenging real-world multimodal scenarios, which may involve noisy, incomplete, or out-of-distribution data.
-
Interpretability and Explainability: As with many complex deep learning models, understanding the internal workings and decision-making process of OmniFusion may be challenging. Investigating techniques to improve the interpretability and explainability of the model could enhance trust and facilitate further improvements.
-
Ethical Considerations: As multimodal AI systems become more powerful and ubiquitous, it is important to consider potential ethical implications, such as bias, privacy, and fairness. The paper could have delved deeper into these important issues and their mitigation strategies.
-
Scalability and Efficiency Tradeoffs: While the paper highlights the efficiency of OmniFusion, there may be tradeoffs between model size, computational requirements, and performance that warrant further exploration. Investigating ways to balance these factors could lead to even more practical and accessible multimodal AI solutions.
Overall, the OmniFusion paper presents a compelling and innovative approach to multimodal fusion, with promising results and practical implications. Addressing the above considerations could further strengthen the research and its real-world impact.
Conclusion
The OmniFusion paper introduces a novel multimodal fusion model that integrates visual and language data efficiently on a single GPU. Its modular design, novel fusion techniques, and efficient training and inference methods enable strong performance on a range of multimodal tasks while requiring fewer computational resources than previous approaches.
By building on recent advancements in vision-language models and modularized language models, OmniFusion represents an important step forward in developing practical and scalable multimodal AI systems. These systems have the potential to power a wide range of applications, from image captioning and visual question-answering to multimodal classification and beyond.
While the paper highlights several key strengths of OmniFusion, there are also opportunities for further research to address potential limitations around generalization, interpretability, ethics, and efficiency tradeoffs. Continued advancements in this area could lead to even more powerful and accessible multimodal AI solutions that can better understand and interact with the world around us.
Related Papers

A Review of Multi-Modal Large Language and Vision Models
Kilian Carolan, Laura Fennelly, Alan F. Smeaton
0
0
Large Language Models (LLMs) have recently emerged as a focal point of research and application, driven by their unprecedented ability to understand and generate text with human-like quality. Even more recently, LLMs have been extended into multi-modal large language models (MM-LLMs) which extends their capabilities to deal with image, video and audio information, in addition to text. This opens up applications like text-to-video generation, image captioning, text-to-speech, and more and is achieved either by retro-fitting an LLM with multi-modal capabilities, or building a MM-LLM from scratch. This paper provides an extensive review of the current state of those LLMs with multi-modal capabilities as well as the very recent MM-LLMs. It covers the historical development of LLMs especially the advances enabled by transformer-based architectures like OpenAI's GPT series and Google's BERT, as well as the role of attention mechanisms in enhancing model performance. The paper includes coverage of the major and most important of the LLMs and MM-LLMs and also covers the techniques of model tuning, including fine-tuning and prompt engineering, which tailor pre-trained models to specific tasks or domains. Ethical considerations and challenges, such as data bias and model misuse, are also analysed to underscore the importance of responsible AI development and deployment. Finally, we discuss the implications of open-source versus proprietary models in AI research. Through this review, we provide insights into the transformative potential of MM-LLMs in various applications.
4/3/2024
🌀
Data-Efficient Multimodal Fusion on a Single GPU
Noel Vouitsis, Zhaoyan Liu, Satya Krishna Gorti, Valentin Villecroze, Jesse C. Cresswell, Guangwei Yu, Gabriel Loaiza-Ganem, Maksims Volkovs
0
0
The goal of multimodal alignment is to learn a single latent space that is shared between multimodal inputs. The most powerful models in this space have been trained using massive datasets of paired inputs and large-scale computational resources, making them prohibitively expensive to train in many practical scenarios. We surmise that existing unimodal encoders pre-trained on large amounts of unimodal data should provide an effective bootstrap to create multimodal models from unimodal ones at much lower costs. We therefore propose FuseMix, a multimodal augmentation scheme that operates on the latent spaces of arbitrary pre-trained unimodal encoders. Using FuseMix for multimodal alignment, we achieve competitive performance -- and in certain cases outperform state-of-the art methods -- in both image-text and audio-text retrieval, with orders of magnitude less compute and data: for example, we outperform CLIP on the Flickr30K text-to-image retrieval task with $sim ! 600times$ fewer GPU days and $sim ! 80times$ fewer image-text pairs. Additionally, we show how our method can be applied to convert pre-trained text-to-image generative models into audio-to-image ones. Code is available at: https://github.com/layer6ai-labs/fusemix.
4/11/2024
📊
CapsFusion: Rethinking Image-Text Data at Scale
Qiying Yu, Quan Sun, Xiaosong Zhang, Yufeng Cui, Fan Zhang, Yue Cao, Xinlong Wang, Jingjing Liu
0
0
Large multimodal models demonstrate remarkable generalist ability to perform diverse multimodal tasks in a zero-shot manner. Large-scale web-based image-text pairs contribute fundamentally to this success, but suffer from excessive noise. Recent studies use alternative captions synthesized by captioning models and have achieved notable benchmark performance. However, our experiments reveal significant Scalability Deficiency and World Knowledge Loss issues in models trained with synthetic captions, which have been largely obscured by their initial benchmark success. Upon closer examination, we identify the root cause as the overly-simplified language structure and lack of knowledge details in existing synthetic captions. To provide higher-quality and more scalable multimodal pretraining data, we propose CapsFusion, an advanced framework that leverages large language models to consolidate and refine information from both web-based image-text pairs and synthetic captions. Extensive experiments show that CapsFusion captions exhibit remarkable all-round superiority over existing captions in terms of model performance (e.g., 18.8 and 18.3 improvements in CIDEr score on COCO and NoCaps), sample efficiency (requiring 11-16 times less computation than baselines), world knowledge depth, and scalability. These effectiveness, efficiency and scalability advantages position CapsFusion as a promising candidate for future scaling of LMM training.
4/8/2024
🤔
MM1: Methods, Analysis & Insights from Multimodal LLM Pre-training
Brandon McKinzie, Zhe Gan, Jean-Philippe Fauconnier, Sam Dodge, Bowen Zhang, Philipp Dufter, Dhruti Shah, Xianzhi Du, Futang Peng, Floris Weers, Anton Belyi, Haotian Zhang, Karanjeet Singh, Doug Kang, Ankur Jain, Hongyu H`e, Max Schwarzer, Tom Gunter, Xiang Kong, Aonan Zhang, Jianyu Wang, Chong Wang, Nan Du, Tao Lei, Sam Wiseman, Guoli Yin, Mark Lee, Zirui Wang, Ruoming Pang, Peter Grasch, Alexander Toshev, Yinfei Yang
0
0
In this work, we discuss building performant Multimodal Large Language Models (MLLMs). In particular, we study the importance of various architecture components and data choices. Through careful and comprehensive ablations of the image encoder, the vision language connector, and various pre-training data choices, we identified several crucial design lessons. For example, we demonstrate that for large-scale multimodal pre-training using a careful mix of image-caption, interleaved image-text, and text-only data is crucial for achieving state-of-the-art (SOTA) few-shot results across multiple benchmarks, compared to other published pre-training results. Further, we show that the image encoder together with image resolution and the image token count has substantial impact, while the vision-language connector design is of comparatively negligible importance. By scaling up the presented recipe, we build MM1, a family of multimodal models up to 30B parameters, including both dense models and mixture-of-experts (MoE) variants, that are SOTA in pre-training metrics and achieve competitive performance after supervised fine-tuning on a range of established multimodal benchmarks. Thanks to large-scale pre-training, MM1 enjoys appealing properties such as enhanced in-context learning, and multi-image reasoning, enabling few-shot chain-of-thought prompting.
4/22/2024