One-Index Vector Quantization Based Adversarial Attack on Image Classification

0
🖼️
Sign in to get full access
Overview
- Images are commonly compressed to improve storage and transmission.
- Vector quantization (VQ) is a popular compression method that achieves high compression ratios.
- Existing adversarial attack methods on image classification primarily work in the pixel domain, limiting their real-world applicability.
- This paper proposes a novel one-index attack method in the VQ domain to generate adversarial images using a differential evolution algorithm.
Plain English Explanation
[object Object] is a technique used to compress images. It works by representing the image data with a smaller set of "code vectors," which are like representative values. This allows the image to be stored and transmitted using less data, improving efficiency.
However, [object Object] on image classification models typically operate directly on the raw pixel data, rather than the compressed VQ representation. This makes them less applicable in real-world scenarios where images are often stored and transmitted in a compressed format.
To address this, the researchers propose a new one-index attack method that generates adversarial images by modifying a single VQ index in the compressed data stream. This means the attacker only needs to change a single value in the compressed image to make the model misclassify it. The method uses a [object Object] to efficiently find the optimal index to modify.
The key advantage of this approach is that it works directly on the compressed image data, making it more practical for real-world scenarios where images are typically stored and transmitted in a compressed format like VQ.
Technical Explanation
The paper proposes a novel one-index attack method in the VQ domain to generate adversarial images. The method uses a [object Object] to efficiently modify a single VQ index in the compressed data stream, causing the decompressed image to be misclassified by the victim model.
The researchers apply their one-index attack method to three popular image classification models: [object Object], [object Object], and [object Object]. On average, they are able to successfully attack 55.9% of the images in the CIFAR-10 dataset and 77.4% of the images in the Fashion MNIST dataset, with a high level of misclassification confidence and a low level of image perturbation.
Critical Analysis
The one-index attack method proposed in this paper represents a significant advancement in adversarial attacks on image classification models. By operating directly on the compressed VQ representation of the image data, the method is more applicable to real-world scenarios where images are typically stored and transmitted in a compressed format.
However, the paper does not address the potential for the proposed attack method to be detected or defended against. It would be valuable to explore techniques for [object Object] or making the compressed image data more robust to these types of targeted modifications.
Additionally, the paper focuses on attacking only three specific image classification models. It would be useful to see the method's performance and generalizability when applied to a wider range of models and datasets.
Conclusion
This paper presents a novel one-index attack method in the VQ domain that can generate adversarial images by modifying a single index in the compressed data stream. The method is more practical for real-world scenarios compared to existing adversarial attack approaches that operate in the pixel domain.
The high success rates reported on the CIFAR-10 and Fashion MNIST datasets demonstrate the effectiveness of this approach. However, further research is needed to explore defense mechanisms and the method's broader applicability across a diverse range of image classification models and datasets.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🖼️
0
One-Index Vector Quantization Based Adversarial Attack on Image Classification
Haiju Fan, Xiaona Qin, Shuang Chen, Hubert P. H. Shum, Ming Li
To improve storage and transmission, images are generally compressed. Vector quantization (VQ) is a popular compression method as it has a high compression ratio that suppresses other compression techniques. Despite this, existing adversarial attack methods on image classification are mostly performed in the pixel domain with few exceptions in the compressed domain, making them less applicable in real-world scenarios. In this paper, we propose a novel one-index attack method in the VQ domain to generate adversarial images by a differential evolution algorithm, successfully resulting in image misclassification in victim models. The one-index attack method modifies a single index in the compressed data stream so that the decompressed image is misclassified. It only needs to modify a single VQ index to realize an attack, which limits the number of perturbed indexes. The proposed method belongs to a semi-black-box attack, which is more in line with the actual attack scenario. We apply our method to attack three popular image classification models, i.e., Resnet, NIN, and VGG16. On average, 55.9% and 77.4% of the images in CIFAR-10 and Fashion MNIST, respectively, are successfully attacked, with a high level of misclassification confidence and a low level of image perturbation.
Read more9/4/2024
✨
0
VQUNet: Vector Quantization U-Net for Defending Adversarial Atacks by Regularizing Unwanted Noise
Zhixun He, Mukesh Singhal
Deep Neural Networks (DNN) have become a promising paradigm when developing Artificial Intelligence (AI) and Machine Learning (ML) applications. However, DNN applications are vulnerable to fake data that are crafted with adversarial attack algorithms. Under adversarial attacks, the prediction accuracy of DNN applications suffers, making them unreliable. In order to defend against adversarial attacks, we introduce a novel noise-reduction procedure, Vector Quantization U-Net (VQUNet), to reduce adversarial noise and reconstruct data with high fidelity. VQUNet features a discrete latent representation learning through a multi-scale hierarchical structure for both noise reduction and data reconstruction. The empirical experiments show that the proposed VQUNet provides better robustness to the target DNN models, and it outperforms other state-of-the-art noise-reduction-based defense methods under various adversarial attacks for both Fashion-MNIST and CIFAR10 datasets. When there is no adversarial attack, the defense method has less than 1% accuracy degradation for both datasets.
Read more6/6/2024
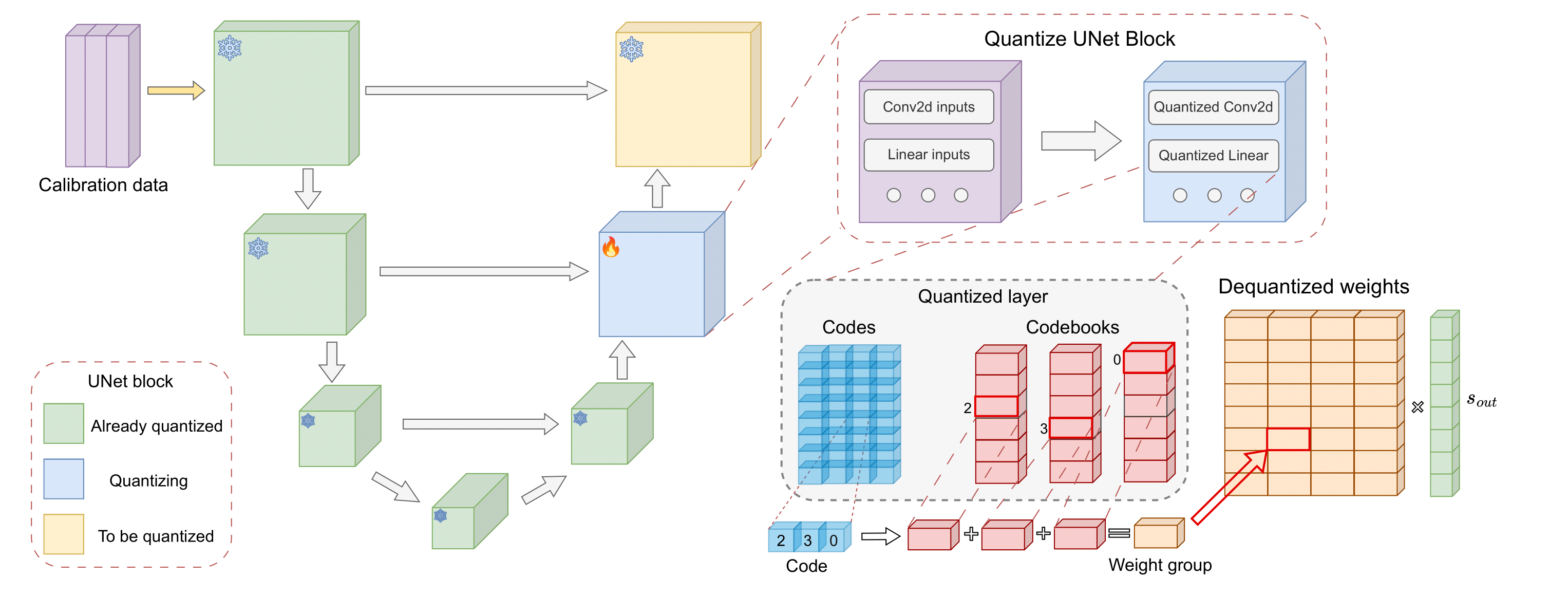
0
Accurate Compression of Text-to-Image Diffusion Models via Vector Quantization
Vage Egiazarian, Denis Kuznedelev, Anton Voronov, Ruslan Svirschevski, Michael Goin, Daniil Pavlov, Dan Alistarh, Dmitry Baranchuk
Text-to-image diffusion models have emerged as a powerful framework for high-quality image generation given textual prompts. Their success has driven the rapid development of production-grade diffusion models that consistently increase in size and already contain billions of parameters. As a result, state-of-the-art text-to-image models are becoming less accessible in practice, especially in resource-limited environments. Post-training quantization (PTQ) tackles this issue by compressing the pretrained model weights into lower-bit representations. Recent diffusion quantization techniques primarily rely on uniform scalar quantization, providing decent performance for the models compressed to 4 bits. This work demonstrates that more versatile vector quantization (VQ) may achieve higher compression rates for large-scale text-to-image diffusion models. Specifically, we tailor vector-based PTQ methods to recent billion-scale text-to-image models (SDXL and SDXL-Turbo), and show that the diffusion models of 2B+ parameters compressed to around 3 bits using VQ exhibit the similar image quality and textual alignment as previous 4-bit compression techniques.
Read more9/4/2024

0
Query-Efficient Hard-Label Black-Box Attack against Vision Transformers
Chao Zhou, Xiaowen Shi, Yuan-Gen Wang
Recent studies have revealed that vision transformers (ViTs) face similar security risks from adversarial attacks as deep convolutional neural networks (CNNs). However, directly applying attack methodology on CNNs to ViTs has been demonstrated to be ineffective since the ViTs typically work on patch-wise encoding. This article explores the vulnerability of ViTs against adversarial attacks under a black-box scenario, and proposes a novel query-efficient hard-label adversarial attack method called AdvViT. Specifically, considering that ViTs are highly sensitive to patch modification, we propose to optimize the adversarial perturbation on the individual patches. To reduce the dimension of perturbation search space, we modify only a handful of low-frequency components of each patch. Moreover, we design a weight mask matrix for all patches to further optimize the perturbation on different regions of a whole image. We test six mainstream ViT backbones on the ImageNet-1k dataset. Experimental results show that compared with the state-of-the-art attacks on CNNs, our AdvViT achieves much lower $L_2$-norm distortion under the same query budget, sufficiently validating the vulnerability of ViTs against adversarial attacks.
Read more7/2/2024