One-shot Training for Video Object Segmentation

0
🏋️
Sign in to get full access
Overview
- Video Object Segmentation (VOS) aims to track and segment objects across video frames
- Previous VOS methods required fully annotated training videos, which are time-consuming to obtain
- Self-supervised VOS approaches have limitations in complex scenarios and efficiency
- This paper proposes a novel one-shot training framework for VOS, requiring only a single labeled frame per video
Plain English Explanation
The goal of Video Object Segmentation (VOS) is to identify and track specific objects as they move through a video. Traditionally, VOS systems have been trained on videos where every frame has been manually labeled, which is a tedious and labor-intensive process.
Meanwhile, some researchers have explored self-supervised approaches to VOS, where the system learns to segment objects without needing extensive manual labeling. However, these methods still have issues - they struggle with complex scenarios, and the way they propagate labels frame-to-frame makes them inefficient.
To address these challenges, this paper introduces a new one-shot training framework for VOS. Instead of requiring fully labeled videos, this approach only needs a single annotated frame per training video. The key ideas are:
- Forward Inference: Using the initial labeled frame, the system infers the object masks in the subsequent frames.
- Backward Reconstruction: The system then tries to reconstruct the original labeled mask by looking at the inferred masks from the previous step.
By training the VOS network to both infer object masks moving forward and then reconstruct the original mask moving backward, the authors are able to achieve comparable performance to models trained on fully labeled datasets, but with far less manual annotation effort.
Technical Explanation
The core of this paper's contribution is a novel one-shot training framework for Video Object Segmentation (VOS) models. Unlike previous approaches that require fully annotated training videos, this method only needs a single labeled frame per video.
The key components of the training process are:
-
Forward Inference: Given the initial labeled frame, the system infers the object masks in the subsequent frames. This leverages the temporal continuity of the video to propagate the segmentation.
-
Backward Reconstruction: The system then attempts to reconstruct the original labeled mask by looking at the inferred masks from the previous step. This bidirectional training helps the model learn robust feature representations.
The authors show that this simple yet effective training strategy can be applied to a variety of existing state-of-the-art VOS architectures, including those that use reinforcement learning or leverage large-scale, long-term video datasets. Experiments on the YouTube-VOS and DAVIS datasets demonstrate that this one-shot approach can achieve comparable performance to fully supervised methods, while dramatically reducing the manual annotation effort required.
Critical Analysis
The one-shot training framework proposed in this paper is a clever and practical solution to the labeling bottleneck in Video Object Segmentation (VOS). By only requiring a single annotated frame per video, it significantly lowers the barrier to training high-performing VOS models.
That said, the paper does not extensively discuss the potential limitations of this approach. For example, it is unclear how well the method would generalize to videos with heavy occlusions, fast-moving objects, or drastic camera motion - scenarios where the assumption of temporal continuity may break down. Additionally, the one-shot training process may be more sensitive to the quality and representativeness of the single annotated frame compared to fully supervised approaches.
Further research could also explore ways to make the training process even more efficient, perhaps by incorporating techniques from self-supervised VOS or leveraging language-guided video segmentation. Combining this one-shot approach with methods that can learn from large-scale, long-term video data or global motion understanding may also lead to further performance improvements.
Conclusion
This paper presents a novel one-shot training framework for Video Object Segmentation (VOS) that significantly reduces the manual annotation effort required to train high-performing VOS models. By leveraging the temporal continuity of video through a bidirectional training process, the authors show that satisfactory VOS performance can be achieved with only a single labeled frame per training video.
This work has the potential to make VOS more accessible and practical for a wider range of applications, from autonomous driving to video editing and beyond. As the field continues to evolve, further research building on this one-shot approach could lead to even more efficient and robust video object segmentation systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🏋️
0
One-shot Training for Video Object Segmentation
Baiyu Chen, Sixian Chan, Xiaoqin Zhang
Video Object Segmentation (VOS) aims to track objects across frames in a video and segment them based on the initial annotated frame of the target objects. Previous VOS works typically rely on fully annotated videos for training. However, acquiring fully annotated training videos for VOS is labor-intensive and time-consuming. Meanwhile, self-supervised VOS methods have attempted to build VOS systems through correspondence learning and label propagation. Still, the absence of mask priors harms their robustness to complex scenarios, and the label propagation paradigm makes them impractical in terms of efficiency. To address these issues, we propose, for the first time, a general one-shot training framework for VOS, requiring only a single labeled frame per training video and applicable to a majority of state-of-the-art VOS networks. Specifically, our algorithm consists of: i) Inferring object masks time-forward based on the initial labeled frame. ii) Reconstructing the initial object mask time-backward using the masks from step i). Through this bi-directional training, a satisfactory VOS network can be obtained. Notably, our approach is extremely simple and can be employed end-to-end. Finally, our approach uses a single labeled frame of YouTube-VOS and DAVIS datasets to achieve comparable results to those trained on fully labeled datasets. The code will be released.
Read more5/24/2024
🧪
0
Point-VOS: Pointing Up Video Object Segmentation
Idil Esen Zulfikar, Sabarinath Mahadevan, Paul Voigtlaender, Bastian Leibe
Current state-of-the-art Video Object Segmentation (VOS) methods rely on dense per-object mask annotations both during training and testing. This requires time-consuming and costly video annotation mechanisms. We propose a novel Point-VOS task with a spatio-temporally sparse point-wise annotation scheme that substantially reduces the annotation effort. We apply our annotation scheme to two large-scale video datasets with text descriptions and annotate over 19M points across 133K objects in 32K videos. Based on our annotations, we propose a new Point-VOS benchmark, and a corresponding point-based training mechanism, which we use to establish strong baseline results. We show that existing VOS methods can easily be adapted to leverage our point annotations during training, and can achieve results close to the fully-supervised performance when trained on pseudo-masks generated from these points. In addition, we show that our data can be used to improve models that connect vision and language, by evaluating it on the Video Narrative Grounding (VNG) task. We will make our code and annotations available at https://pointvos.github.io.
Read more6/11/2024

0
Betrayed by Attention: A Simple yet Effective Approach for Self-supervised Video Object Segmentation
Shuangrui Ding, Rui Qian, Haohang Xu, Dahua Lin, Hongkai Xiong
In this paper, we propose a simple yet effective approach for self-supervised video object segmentation (VOS). Our key insight is that the inherent structural dependencies present in DINO-pretrained Transformers can be leveraged to establish robust spatio-temporal correspondences in videos. Furthermore, simple clustering on this correspondence cue is sufficient to yield competitive segmentation results. Previous self-supervised VOS techniques majorly resort to auxiliary modalities or utilize iterative slot attention to assist in object discovery, which restricts their general applicability and imposes higher computational requirements. To deal with these challenges, we develop a simplified architecture that capitalizes on the emerging objectness from DINO-pretrained Transformers, bypassing the need for additional modalities or slot attention. Specifically, we first introduce a single spatio-temporal Transformer block to process the frame-wise DINO features and establish spatio-temporal dependencies in the form of self-attention. Subsequently, utilizing these attention maps, we implement hierarchical clustering to generate object segmentation masks. To train the spatio-temporal block in a fully self-supervised manner, we employ semantic and dynamic motion consistency coupled with entropy normalization. Our method demonstrates state-of-the-art performance across multiple unsupervised VOS benchmarks and particularly excels in complex real-world multi-object video segmentation tasks such as DAVIS-17-Unsupervised and YouTube-VIS-19. The code and model checkpoints will be released at https://github.com/shvdiwnkozbw/SSL-UVOS.
Read more7/9/2024
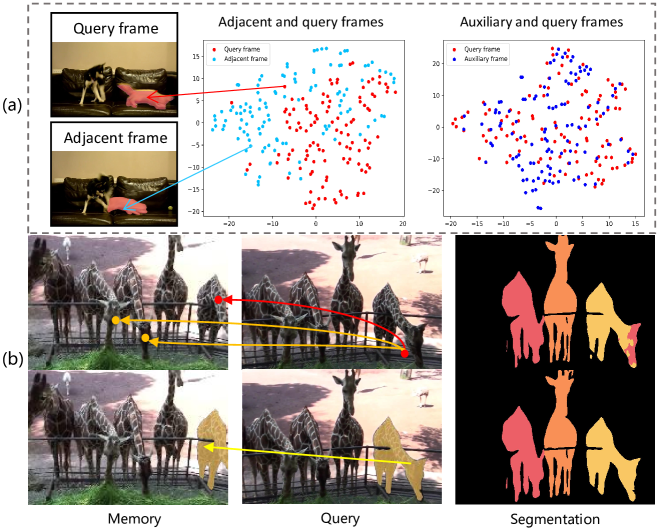
0
Space-time Reinforcement Network for Video Object Segmentation
Yadang Chen, Wentao Zhu, Zhi-Xin Yang, Enhua Wu
Recently, video object segmentation (VOS) networks typically use memory-based methods: for each query frame, the mask is predicted by space-time matching to memory frames. Despite these methods having superior performance, they suffer from two issues: 1) Challenging data can destroy the space-time coherence between adjacent video frames. 2) Pixel-level matching will lead to undesired mismatching caused by the noises or distractors. To address the aforementioned issues, we first propose to generate an auxiliary frame between adjacent frames, serving as an implicit short-temporal reference for the query one. Next, we learn a prototype for each video object and prototype-level matching can be implemented between the query and memory. The experiment demonstrated that our network outperforms the state-of-the-art method on the DAVIS 2017, achieving a J&F score of 86.4%, and attains a competitive result 85.0% on YouTube VOS 2018. In addition, our network exhibits a high inference speed of 32+ FPS.
Read more5/8/2024