One-step Diffusion with Distribution Matching Distillation

2
🧠
Sign in to get full access
Overview
- Diffusion models can generate high-quality images, but they require dozens of forward passes.
- The researchers introduce Distribution Matching Distillation (DMD), a technique to transform a diffusion model into a one-step image generator with minimal impact on image quality.
- DMD matches the one-step generator to the diffusion model at the distribution level, minimizing an approximate KL divergence.
- The method outperforms other few-step diffusion approaches and is comparable to Stable Diffusion, but orders of magnitude faster.
Plain English Explanation
Diffusion models are a type of machine learning model that can generate high-quality images. However, one downside of diffusion models is that they require many individual steps, or "forward passes," to generate a single image. This can make them slow and computationally expensive.
The researchers developed a new technique called Distribution Matching Distillation (DMD) to address this issue. DMD allows them to transform a diffusion model into a simpler, one-step image generator, with minimal impact on the quality of the generated images.
The key idea behind DMD is to ensure that the one-step generator matches the diffusion model at the distribution level. In other words, the images produced by the one-step generator should have a similar overall "shape" or statistical distribution as the images produced by the original diffusion model. The researchers do this by minimizing a measure of the difference, or "divergence," between the two distributions.
Compared to other approaches for speeding up diffusion models, the DMD method performs better and is much faster, generating images at 20 frames per second on modern hardware. This makes it a promising technique for real-world applications that require fast image generation, like interactive design tools or animation.
Technical Explanation
Diffusion models are a type of generative model that can produce high-quality, realistic images. However, they typically require a large number of forward passes, or iterative refinement steps, to generate a single image, which can be computationally expensive.
To address this issue, the researchers introduce Distribution Matching Distillation (DMD), a method to transform a diffusion model into a faster, one-step image generator. The key idea is to enforce the one-step generator to match the diffusion model at the distribution level, by minimizing an approximate Kullback-Leibler (KL) divergence between the two distributions.
The approximate KL divergence is expressed as the difference between two "score functions," which are parameterized as separate diffusion models trained on the target distribution (from the original diffusion model) and the synthetic distribution being produced by the one-step generator, respectively. By minimizing this divergence, the one-step generator is encouraged to match the distribution of the original diffusion model.
In addition to this distribution matching loss, the researchers also use a simple regression loss to help the one-step generator match the large-scale structure of the multi-step diffusion outputs. This combination of losses allows the one-step generator to achieve image quality comparable to the original diffusion model, while being orders of magnitude faster.
The researchers evaluate their DMD approach on the ImageNet and COCO-30k datasets, and show that it outperforms other published few-step diffusion approaches. With FP16 inference, their one-step generator can generate images at 20 frames per second on modern hardware, making it a promising technique for real-time applications.
Critical Analysis
The Distribution Matching Distillation (DMD) approach presented in the paper is a clever and effective solution for speeding up diffusion models without significantly sacrificing image quality. By distilling the knowledge of the original diffusion model into a simpler, one-step generator, the researchers have developed a method that is both fast and high-performing.
One potential limitation of the approach is that it relies on training separate diffusion models to parameterize the score functions used in the approximate KL divergence. This could be computationally expensive and may limit the scalability of the method, especially for larger or more complex datasets.
Additionally, the paper does not extensively explore the potential limitations or failure modes of the DMD approach. It would be helpful to see more discussion of the types of images or datasets where the one-step generator may struggle to match the quality of the original diffusion model, as well as any potential biases or artifacts that could be introduced by the distillation process.
Despite these minor concerns, the DMD method represents a significant advancement in the field of diffusion models, demonstrating that it is possible to achieve both speed and high-quality image generation. As the authors note, this could have important implications for a wide range of real-world applications that require fast, on-the-fly image synthesis.
Conclusion
The Distribution Matching Distillation (DMD) technique introduced in this paper offers a promising solution for transforming slow, multi-step diffusion models into fast, one-step image generators with minimal impact on image quality. By enforcing the one-step generator to match the distribution of the original diffusion model, the researchers have developed a method that outperforms other few-step diffusion approaches and is comparable to state-of-the-art models like Stable Diffusion, but with orders of magnitude faster inference speed.
This work has important implications for a wide range of applications that require real-time image synthesis, such as interactive design tools, animation, and augmented reality. The ability to generate high-quality images at 20 frames per second opens up new possibilities for how we create and interact with visual content. As the field of generative AI continues to advance, techniques like DMD will likely play a crucial role in making these models more practical and accessible for real-world use.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🧠
2
New!One-step Diffusion with Distribution Matching Distillation
Tianwei Yin, Michael Gharbi, Richard Zhang, Eli Shechtman, Fredo Durand, William T. Freeman, Taesung Park
Diffusion models generate high-quality images but require dozens of forward passes. We introduce Distribution Matching Distillation (DMD), a procedure to transform a diffusion model into a one-step image generator with minimal impact on image quality. We enforce the one-step image generator match the diffusion model at distribution level, by minimizing an approximate KL divergence whose gradient can be expressed as the difference between 2 score functions, one of the target distribution and the other of the synthetic distribution being produced by our one-step generator. The score functions are parameterized as two diffusion models trained separately on each distribution. Combined with a simple regression loss matching the large-scale structure of the multi-step diffusion outputs, our method outperforms all published few-step diffusion approaches, reaching 2.62 FID on ImageNet 64x64 and 11.49 FID on zero-shot COCO-30k, comparable to Stable Diffusion but orders of magnitude faster. Utilizing FP16 inference, our model generates images at 20 FPS on modern hardware.
Read more10/8/2024
🖼️
0
Improved Distribution Matching Distillation for Fast Image Synthesis
Tianwei Yin, Michael Gharbi, Taesung Park, Richard Zhang, Eli Shechtman, Fredo Durand, William T. Freeman
Recent approaches have shown promises distilling diffusion models into efficient one-step generators. Among them, Distribution Matching Distillation (DMD) produces one-step generators that match their teacher in distribution, without enforcing a one-to-one correspondence with the sampling trajectories of their teachers. However, to ensure stable training, DMD requires an additional regression loss computed using a large set of noise-image pairs generated by the teacher with many steps of a deterministic sampler. This is costly for large-scale text-to-image synthesis and limits the student's quality, tying it too closely to the teacher's original sampling paths. We introduce DMD2, a set of techniques that lift this limitation and improve DMD training. First, we eliminate the regression loss and the need for expensive dataset construction. We show that the resulting instability is due to the fake critic not estimating the distribution of generated samples accurately and propose a two time-scale update rule as a remedy. Second, we integrate a GAN loss into the distillation procedure, discriminating between generated samples and real images. This lets us train the student model on real data, mitigating the imperfect real score estimation from the teacher model, and enhancing quality. Lastly, we modify the training procedure to enable multi-step sampling. We identify and address the training-inference input mismatch problem in this setting, by simulating inference-time generator samples during training time. Taken together, our improvements set new benchmarks in one-step image generation, with FID scores of 1.28 on ImageNet-64x64 and 8.35 on zero-shot COCO 2014, surpassing the original teacher despite a 500X reduction in inference cost. Further, we show our approach can generate megapixel images by distilling SDXL, demonstrating exceptional visual quality among few-step methods.
Read more5/27/2024

0
Regularized Distribution Matching Distillation for One-step Unpaired Image-to-Image Translation
Denis Rakitin, Ivan Shchekotov, Dmitry Vetrov
Diffusion distillation methods aim to compress the diffusion models into efficient one-step generators while trying to preserve quality. Among them, Distribution Matching Distillation (DMD) offers a suitable framework for training general-form one-step generators, applicable beyond unconditional generation. In this work, we introduce its modification, called Regularized Distribution Matching Distillation, applicable to unpaired image-to-image (I2I) problems. We demonstrate its empirical performance in application to several translation tasks, including 2D examples and I2I between different image datasets, where it performs on par or better than multi-step diffusion baselines.
Read more6/24/2024
0
Diffusion Models Are Innate One-Step Generators
Bowen Zheng, Tianming Yang
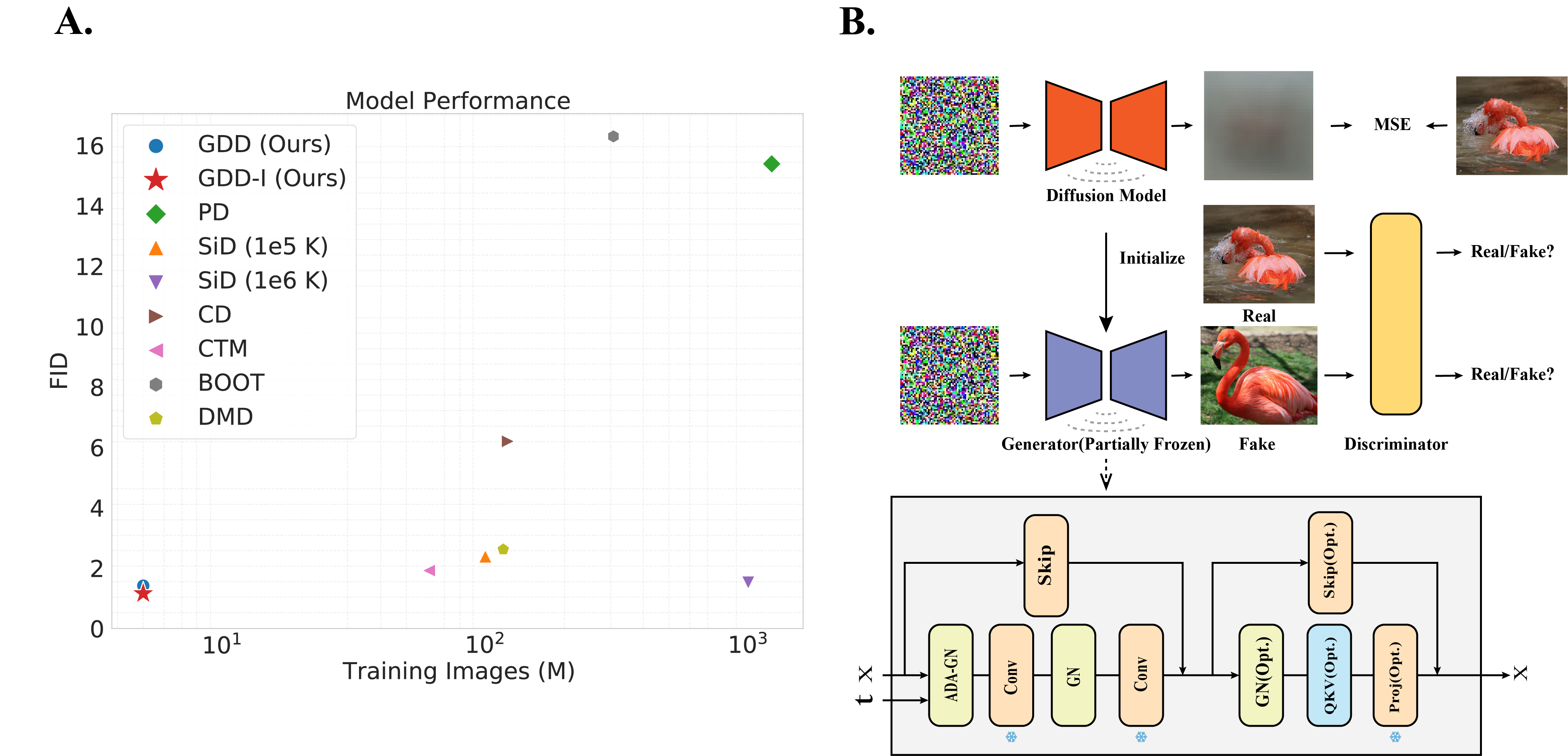
Diffusion Models (DMs) have achieved great success in image generation and other fields. By fine sampling through the trajectory defined by the SDE/ODE solver based on a well-trained score model, DMs can generate remarkable high-quality results. However, this precise sampling often requires multiple steps and is computationally demanding. To address this problem, instance-based distillation methods have been proposed to distill a one-step generator from a DM by having a simpler student model mimic a more complex teacher model. Yet, our research reveals an inherent limitations in these methods: the teacher model, with more steps and more parameters, occupies different local minima compared to the student model, leading to suboptimal performance when the student model attempts to replicate the teacher. To avoid this problem, we introduce a novel distributional distillation method, which uses an exclusive distributional loss. This method exceeds state-of-the-art (SOTA) results while requiring significantly fewer training images. Additionally, we show that DMs' layers are differentially activated at different time steps, leading to an inherent capability to generate images in a single step. Freezing most of the convolutional layers in a DM during distributional distillation enables this innate capability and leads to further performance improvements. Our method achieves the SOTA results on CIFAR-10 (FID 1.54), AFHQv2 64x64 (FID 1.23), FFHQ 64x64 (FID 0.85) and ImageNet 64x64 (FID 1.16) with great efficiency. Most of those results are obtained with only 5 million training images within 6 hours on 8 A100 GPUs.
Read more6/10/2024