One Stone, Four Birds: A Comprehensive Solution for QA System Using Supervised Contrastive Learning

0

Sign in to get full access
Overview
- This paper presents a comprehensive solution for a question-answering (QA) system using supervised contrastive learning.
- The proposed approach addresses key challenges in QA systems, including intent discovery, out-of-domain detection, and natural language processing.
- The system leverages supervised contrastive learning to improve the accuracy and robustness of the QA model across various domains.
Plain English Explanation
The paper introduces a new way to build question-answering (QA) systems that can handle a wide range of questions and topics. Traditional QA systems often struggle with understanding the true intent behind a user's question, or with answering questions that fall outside their trained domain.
To address these challenges, the researchers developed a QA system that uses a technique called "supervised contrastive learning." This involves training the system not just on the correct answers to questions, but also on how different questions are related to each other. By learning these relationships, the system can better understand the underlying meaning and intent behind new questions, even if they cover unfamiliar topics.
The key idea is to train the system to identify similarities and differences between questions, rather than just memorizing question-answer pairs. This allows the system to generalize its knowledge and apply it to a wider range of questions. For example, if the system understands that "What is the capital of France?" and "What is the largest city in Europe?" are related in certain ways, it can use that knowledge to better understand a new question like "What is the most populous city in the European Union?"
By incorporating this contrastive learning approach, the researchers were able to create a QA system that is more accurate, robust, and capable of handling a broader range of questions compared to traditional systems. This represents an important step forward in developing QA systems that can truly understand and engage with users in a more natural and helpful way.
Technical Explanation
The paper proposes a comprehensive solution for a question-answering (QA) system using supervised contrastive learning. The key innovations of the approach include:
-
Intent Discovery: The system leverages supervised contrastive learning to better understand the underlying intent behind user questions, even for out-of-domain queries. This is achieved by training the model to not only predict the correct answer, but also to identify similarities and differences between questions.
-
Out-of-Domain Detection: By learning the relationships between questions, the system can more accurately detect when a new question falls outside its trained domain. This allows the system to provide appropriate responses, such as acknowledging the limitation of its knowledge or redirecting the user to a more suitable resource.
-
Natural Language Processing: The contrastive learning approach enables the system to better capture the nuances and complexities of natural language, improving its overall language understanding capabilities. This leads to more accurate and contextually relevant responses.
The proposed architecture consists of a base encoder model that learns contextual representations of the questions, and a contrastive head that compares the representations of different questions to identify their relationships. The system is trained end-to-end using a combination of standard cross-entropy loss for answer prediction and a supervised contrastive loss to capture the similarity structure of the questions.
The authors evaluate the system's performance on several benchmark QA datasets, demonstrating significant improvements in accuracy, out-of-domain detection, and overall robustness compared to traditional QA models. The results highlight the effectiveness of the supervised contrastive learning approach in developing more comprehensive and adaptable QA systems.
Critical Analysis
The paper presents a compelling solution for addressing key challenges in question-answering systems. The use of supervised contrastive learning is a novel and promising approach that allows the system to better understand the underlying semantics and relationships between questions, rather than just memorizing question-answer pairs.
One potential limitation of the approach is the requirement for a large and diverse training dataset that captures the nuances and complexities of natural language. The authors acknowledge this challenge and suggest further research into few-shot and zero-shot learning techniques to improve the system's adaptability to new domains and question types.
Additionally, the paper does not provide a detailed analysis of the system's performance on real-world, open-ended questions that may involve ambiguity, context-dependence, or the need for commonsense reasoning. Further evaluation in more realistic and challenging scenarios would help validate the system's practical applicability.
Another area for future research could be the integration of the contrastive learning approach with other advanced natural language processing techniques, such as those used in Pre-training Cross-lingual Open-Domain Question Answering, Hybrid Cooperative Contrastive Learning for Cross-lingual, or TrustUQA: A Trustful Framework for Unified Structured Data Question Answering. Combining complementary techniques could further enhance the system's performance and robustness.
Conclusion
The paper presents a comprehensive solution for a question-answering system that addresses key challenges in intent discovery, out-of-domain detection, and natural language processing. By leveraging supervised contrastive learning, the proposed approach demonstrates significant improvements in accuracy, robustness, and adaptability compared to traditional QA models.
The novel contrastive learning technique allows the system to better understand the relationships between questions, rather than just memorizing question-answer pairs. This enables the system to generalize its knowledge and apply it to a wider range of questions, even those outside its trained domain.
The research represents an important step forward in developing more advanced and user-friendly QA systems that can truly engage with and assist users in a more natural and meaningful way. Further refinements and integrations with other cutting-edge NLP techniques, as well as evaluations in more realistic scenarios, could further enhance the system's capabilities and pave the way for more intelligent and comprehensive question-answering solutions.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
One Stone, Four Birds: A Comprehensive Solution for QA System Using Supervised Contrastive Learning
Bo Wang, Tsunenori Mine
This paper presents a novel and comprehensive solution to enhance both the robustness and efficiency of question answering (QA) systems through supervised contrastive learning (SCL). Training a high-performance QA system has become straightforward with pre-trained language models, requiring only a small amount of data and simple fine-tuning. However, despite recent advances, existing QA systems still exhibit significant deficiencies in functionality and training efficiency. We address the functionality issue by defining four key tasks: user input intent classification, out-of-domain input detection, new intent discovery, and continual learning. We then leverage a unified SCL-based representation learning method to efficiently build an intra-class compact and inter-class scattered feature space, facilitating both known intent classification and unknown intent detection and discovery. Consequently, with minimal additional tuning on downstream tasks, our approach significantly improves model efficiency and achieves new state-of-the-art performance across all tasks.
Read more7/15/2024
0
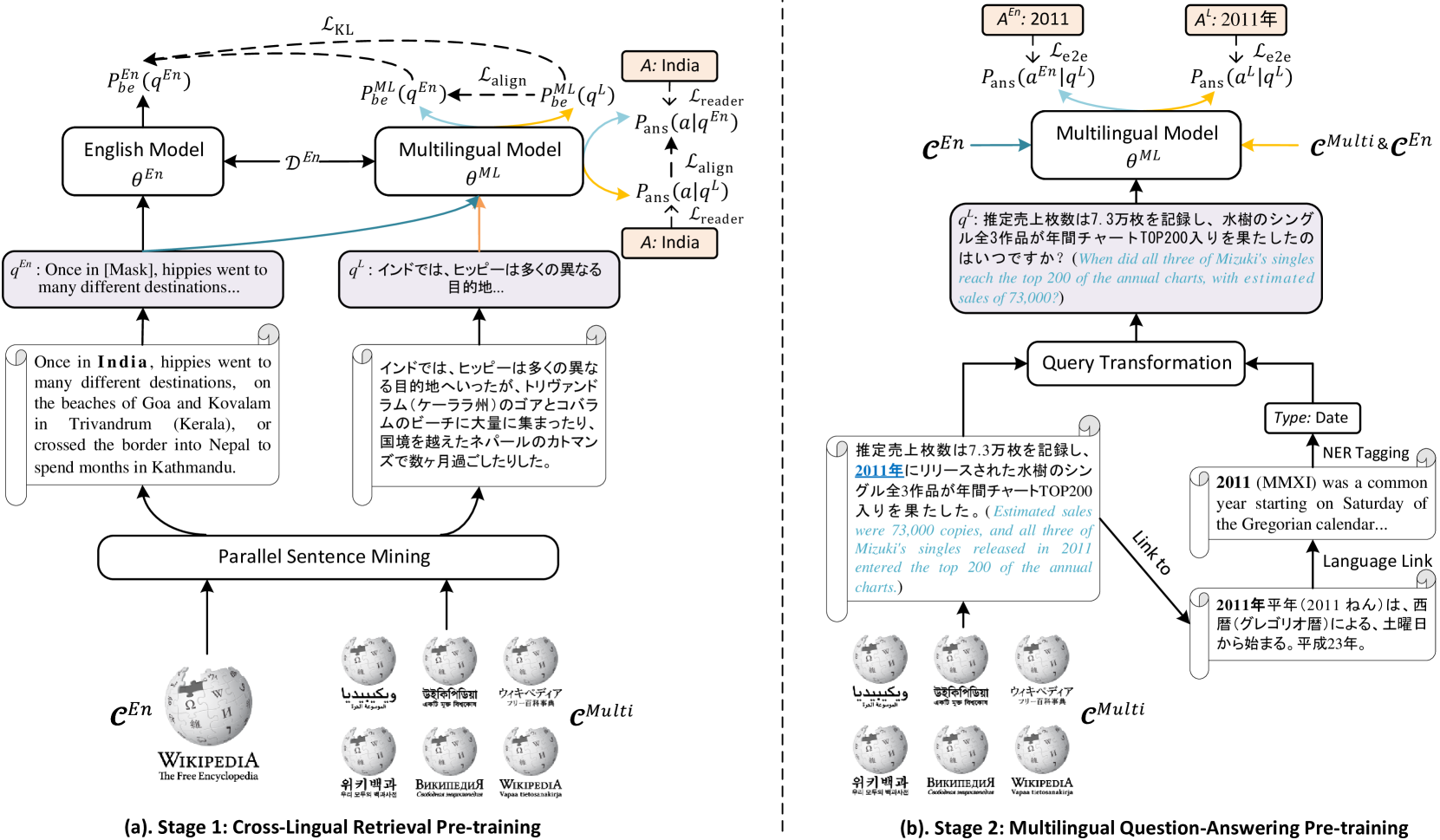
Pre-training Cross-lingual Open Domain Question Answering with Large-scale Synthetic Supervision
Fan Jiang, Tom Drummond, Trevor Cohn
Cross-lingual open domain question answering (CLQA) is a complex problem, comprising cross-lingual retrieval from a multilingual knowledge base, followed by answer generation in the query language. Both steps are usually tackled by separate models, requiring substantial annotated datasets, and typically auxiliary resources, like machine translation systems to bridge between languages. In this paper, we show that CLQA can be addressed using a single encoder-decoder model. To effectively train this model, we propose a self-supervised method based on exploiting the cross-lingual link structure within Wikipedia. We demonstrate how linked Wikipedia pages can be used to synthesise supervisory signals for cross-lingual retrieval, through a form of cloze query, and generate more natural questions to supervise answer generation. Together, we show our approach, texttt{CLASS}, outperforms comparable methods on both supervised and zero-shot language adaptation settings, including those using machine translation.
Read more6/18/2024

0
SQ-LLaVA: Self-Questioning for Large Vision-Language Assistant
Guohao Sun, Can Qin, Jiamian Wang, Zeyuan Chen, Ran Xu, Zhiqiang Tao
Recent advances in vision-language models have shown notable generalization in broad tasks through visual instruction tuning. However, bridging the gap between the pre-trained vision encoder and the large language models (LLMs) becomes the whole network's bottleneck. To improve cross-modality alignment, existing works usually consider more visual instruction data covering a broader range of vision tasks to fine-tune the model for question-answering, which, however, is costly to obtain and has not thoroughly explored the rich contextual information contained in images. This paper first attempts to harness the overlooked context within visual instruction data, training the model to self-supervised learning how to ask high-quality questions. In this way, we introduce a novel framework named SQ-LLaVA: Self-Questioning for Large Vision-Language Assistant. SQ-LLaVA exhibits proficiency in generating flexible and meaningful image-related questions while analyzing the visual clue and prior language knowledge, signifying an advanced level of generalized visual understanding. Moreover, fine-tuning SQ-LLaVA on higher-quality instruction data shows a performance improvement compared with traditional visual-instruction tuning methods. This improvement highlights the efficacy of self-questioning techniques in achieving a deeper and more nuanced comprehension of visual content across various contexts.
Read more7/16/2024
💬
0
HC$^2$L: Hybrid and Cooperative Contrastive Learning for Cross-lingual Spoken Language Understanding
Bowen Xing, Ivor W. Tsang
State-of-the-art model for zero-shot cross-lingual spoken language understanding performs cross-lingual unsupervised contrastive learning to achieve the label-agnostic semantic alignment between each utterance and its code-switched data. However, it ignores the precious intent/slot labels, whose label information is promising to help capture the label-aware semantics structure and then leverage supervised contrastive learning to improve both source and target languages' semantics. In this paper, we propose Hybrid and Cooperative Contrastive Learning to address this problem. Apart from cross-lingual unsupervised contrastive learning, we design a holistic approach that exploits source language supervised contrastive learning, cross-lingual supervised contrastive learning and multilingual supervised contrastive learning to perform label-aware semantics alignments in a comprehensive manner. Each kind of supervised contrastive learning mechanism includes both single-task and joint-task scenarios. In our model, one contrastive learning mechanism's input is enhanced by others. Thus the total four contrastive learning mechanisms are cooperative to learn more consistent and discriminative representations in the virtuous cycle during the training process. Experiments show that our model obtains consistent improvements over 9 languages, achieving new state-of-the-art performance.
Read more5/13/2024