Pre-training Cross-lingual Open Domain Question Answering with Large-scale Synthetic Supervision
2402.16508
0
0
Abstract
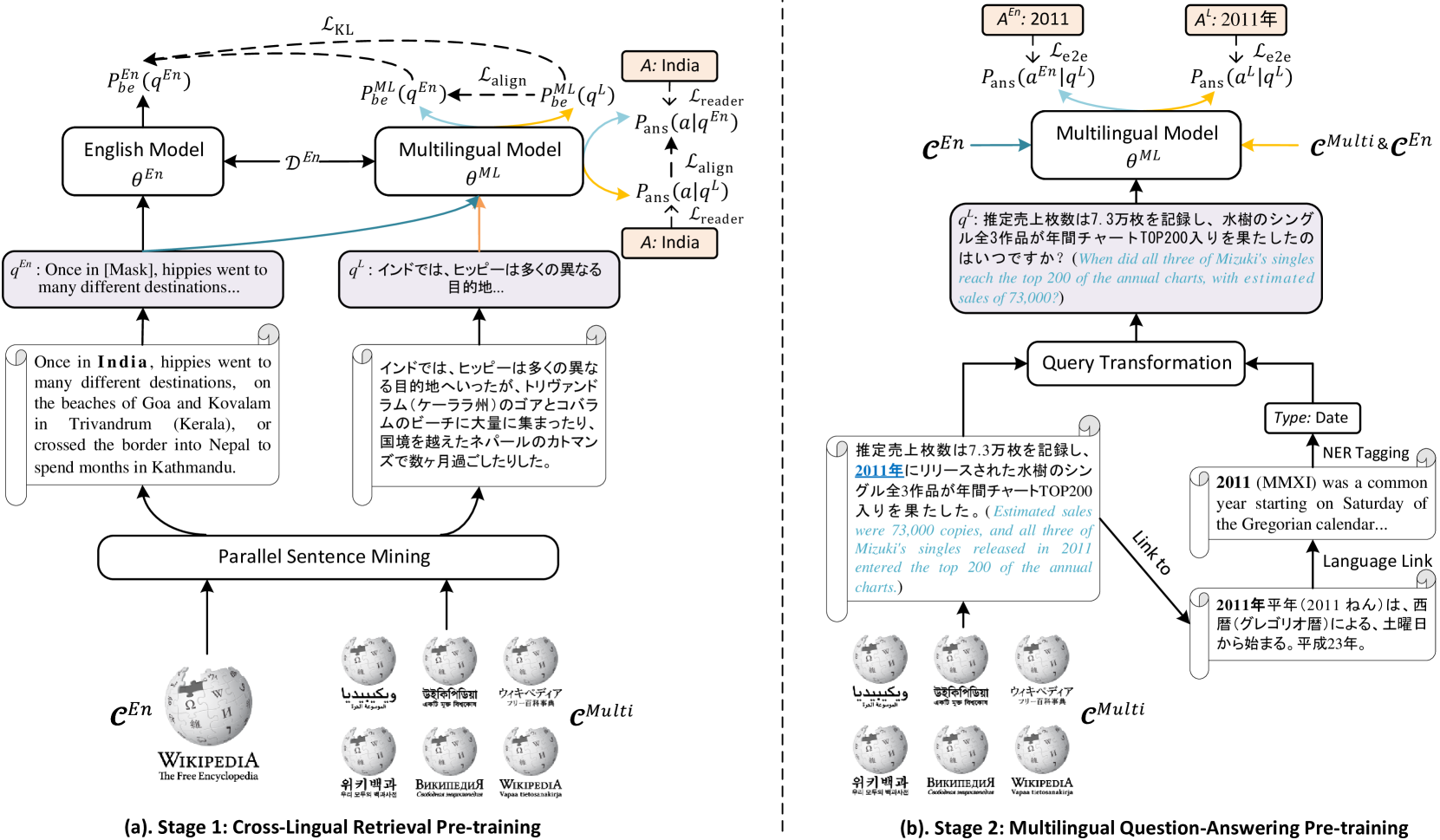
Cross-lingual open domain question answering (CLQA) is a complex problem, comprising cross-lingual retrieval from a multilingual knowledge base, followed by answer generation in the query language. Both steps are usually tackled by separate models, requiring substantial annotated datasets, and typically auxiliary resources, like machine translation systems to bridge between languages. In this paper, we show that CLQA can be addressed using a single encoder-decoder model. To effectively train this model, we propose a self-supervised method based on exploiting the cross-lingual link structure within Wikipedia. We demonstrate how linked Wikipedia pages can be used to synthesise supervisory signals for cross-lingual retrieval, through a form of cloze query, and generate more natural questions to supervise answer generation. Together, we show our approach, texttt{CLASS}, outperforms comparable methods on both supervised and zero-shot language adaptation settings, including those using machine translation.
Create account to get full access
Overview
- This paper presents a pre-training approach for cross-lingual open-domain question answering (QA) using large-scale synthetic supervision.
- The key idea is to leverage machine translation and data augmentation techniques to generate a massive amount of synthetic QA data across multiple languages, which can then be used to pre-train a multilingual QA model.
- The authors demonstrate that this pre-training approach significantly improves the performance of the QA model on various benchmark datasets, including GemQuAD, PersianKWECOQA, and Retrieval-Augmented Generation for Domain-Specific Question Answering.
Plain English Explanation
The paper tackles the problem of cross-lingual open-domain question answering, which means answering questions in different languages using a single model. The researchers used a clever approach to solve this problem:
- They created a large amount of artificial or "synthetic" question-answer pairs in multiple languages by translating existing English QA data into other languages and then generating additional questions based on this translated data.
- They then used this massive synthetic dataset to pre-train a multilingual QA model, which means the model learned general patterns and skills for answering questions across languages before being fine-tuned on specific datasets.
The key advantage of this approach is that it allows the QA model to gain a strong understanding of question-answering across languages, without requiring the time and effort to manually create large labeled datasets in multiple languages. The researchers showed that this pre-training method significantly boosts the model's performance on various benchmark QA tasks in different languages, including GemQuAD, PersianKWECOQA, and Retrieval-Augmented Generation for Domain-Specific Question Answering.
Technical Explanation
The paper focuses on the task of cross-lingual open-domain question answering, where the goal is to build a single model that can answer questions in multiple languages. The authors propose a pre-training approach that leverages large-scale synthetic supervision to improve the performance of the QA model.
The key steps of their approach are:
- Data Augmentation: The authors use machine translation to translate existing English QA datasets, such as SQuAD, into other target languages. They then generate additional synthetic questions based on the translated data using techniques like back-translation and paraphrasing.
- Pre-training: The authors use the large-scale synthetic QA dataset, which covers multiple languages, to pre-train a multilingual QA model. This allows the model to learn general patterns and skills for question answering across languages.
- Fine-tuning: The pre-trained model is then fine-tuned on specific QA datasets in target languages, such as GemQuAD, PersianKWECOQA, and Retrieval-Augmented Generation for Domain-Specific Question Answering.
The authors evaluate their approach on several cross-lingual QA benchmarks and show that the pre-training step significantly boosts the performance of the QA model compared to baselines that do not use synthetic supervision.
Critical Analysis
The paper presents a promising approach for improving cross-lingual open-domain question answering by leveraging large-scale synthetic supervision. However, there are a few potential limitations and areas for further research:
- Dependence on Machine Translation: The quality of the synthetic QA data generated by the authors relies heavily on the accuracy of the machine translation models used. If the translation quality is poor, it could negatively impact the pre-training effectiveness.
- Potential Biases in Synthetic Data: The synthetic data generated by the authors may not fully capture the nuances and biases present in natural language data. This could lead to the model learning biases or making incorrect generalizations.
- Generalization to Low-Resource Languages: The authors focus on high-resource languages in their experiments. It would be valuable to explore the performance of their approach on low-resource languages, where the availability of labeled QA data is more limited.
- Calibration of Multilingual QA Models: As discussed in the Calibration of Multilingual Question Answering LLMs paper, there are challenges in ensuring the reliability and well-calibrated outputs of multilingual QA models, which could be an area for further research.
Overall, the paper presents a promising approach for improving cross-lingual open-domain question answering, but additional research is needed to address the potential limitations and further explore the capabilities of this method.
Conclusion
The paper introduces a novel pre-training approach for cross-lingual open-domain question answering that leverages large-scale synthetic supervision. By using machine translation and data augmentation techniques to generate a massive multilingual QA dataset, the authors are able to pre-train a strong multilingual QA model that significantly outperforms baselines on various benchmark tasks.
This work highlights the potential of synthetic data generation to overcome the data scarcity challenge in building high-performing multilingual NLP models. The authors' approach could have broader implications for other cross-lingual tasks beyond question answering, and the insights from this research could inspire further advancements in efficient and effective open-domain QA systems, especially for low-resource languages.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

GeMQuAD : Generating Multilingual Question Answering Datasets from Large Language Models using Few Shot Learning
Amani Namboori, Shivam Mangale, Andy Rosenbaum, Saleh Soltan
0
0
The emergence of Large Language Models (LLMs) with capabilities like In-Context Learning (ICL) has ushered in new possibilities for data generation across various domains while minimizing the need for extensive data collection and modeling techniques. Researchers have explored ways to use this generated synthetic data to optimize smaller student models for reduced deployment costs and lower latency in downstream tasks. However, ICL-generated data often suffers from low quality as the task specificity is limited with few examples used in ICL. In this paper, we propose GeMQuAD - a semi-supervised learning approach, extending the WeakDAP framework, applied to a dataset generated through ICL with just one example in the target language using AlexaTM 20B Seq2Seq LLM. Through our approach, we iteratively identify high-quality data to enhance model performance, especially for low-resource multilingual setting in the context of Extractive Question Answering task. Our framework outperforms the machine translation-augmented model by 0.22/1.68 F1/EM (Exact Match) points for Hindi and 0.82/1.37 F1/EM points for Spanish on the MLQA dataset, and it surpasses the performance of model trained on an English-only dataset by 5.05/6.50 F1/EM points for Hindi and 3.81/3.69 points F1/EM for Spanish on the same dataset. Notably, our approach uses a pre-trained LLM for generation with no fine-tuning (FT), utilizing just a single annotated example in ICL to generate data, providing a cost-effective development process.
4/16/2024
🛸
Retrieval Augmented Generation for Domain-specific Question Answering
Sanat Sharma, David Seunghyun Yoon, Franck Dernoncourt, Dewang Sultania, Karishma Bagga, Mengjiao Zhang, Trung Bui, Varun Kotte
0
0
Question answering (QA) has become an important application in the advanced development of large language models. General pre-trained large language models for question-answering are not trained to properly understand the knowledge or terminology for a specific domain, such as finance, healthcare, education, and customer service for a product. To better cater to domain-specific understanding, we build an in-house question-answering system for Adobe products. We propose a novel framework to compile a large question-answer database and develop the approach for retrieval-aware finetuning of a Large Language model. We showcase that fine-tuning the retriever leads to major improvements in the final generation. Our overall approach reduces hallucinations during generation while keeping in context the latest retrieval information for contextual grounding.
5/30/2024
🔮
On the Calibration of Multilingual Question Answering LLMs
Yahan Yang, Soham Dan, Dan Roth, Insup Lee
0
0
Multilingual pre-trained Large Language Models (LLMs) are incredibly effective at Question Answering (QA), a core task in Natural Language Understanding, achieving high accuracies on several multilingual benchmarks. However, little is known about how well their confidences are calibrated. In this paper, we comprehensively benchmark the calibration of several multilingual LLMs (MLLMs) on a variety of QA tasks. We perform extensive experiments, spanning encoder-only, encoder-decoder, and decoder-only QA models (size varying from 110M to 7B parameters) and diverse languages, including both high- and low-resource ones. We study different dimensions of calibration in in-distribution, out-of-distribution, and cross-lingual transfer settings, and investigate strategies to improve it, including post-hoc methods and regularized fine-tuning. For decoder-only LLMs such as LlaMa2, we additionally find that in-context learning improves confidence calibration on multilingual data. We also conduct several ablation experiments to study the effect of language distances, language corpus size, and model size on calibration, and how multilingual models compare with their monolingual counterparts for diverse tasks and languages. Our experiments suggest that the multilingual QA models are poorly calibrated for languages other than English and incorporating a small set of cheaply translated multilingual samples during fine-tuning/calibration effectively enhances the calibration performance.
4/16/2024
⛏️
PerkwE_COQA: enhance Persian Conversational Question Answering by combining contextual keyword extraction with Large Language Models
Pardis Moradbeiki, Nasser Ghadiri
0
0
Smart cities need the involvement of their residents to enhance quality of life. Conversational query-answering is an emerging approach for user engagement. There is an increasing demand of an advanced conversational question-answering that goes beyond classic systems. Existing approaches have shown that LLMs offer promising capabilities for CQA, but may struggle to capture the nuances of conversational contexts. The new approach involves understanding the content and engaging in a multi-step conversation with the user to fulfill their needs. This paper presents a novel method to elevate the performance of Persian Conversational question-answering (CQA) systems. It combines the strengths of Large Language Models (LLMs) with contextual keyword extraction. Our method extracts keywords specific to the conversational flow, providing the LLM with additional context to understand the user's intent and generate more relevant and coherent responses. We evaluated the effectiveness of this combined approach through various metrics, demonstrating significant improvements in CQA performance compared to an LLM-only baseline. The proposed method effectively handles implicit questions, delivers contextually relevant answers, and tackles complex questions that rely heavily on conversational context. The findings indicate that our method outperformed the evaluation benchmarks up to 8% higher than existing methods and the LLM-only baseline.
4/16/2024