OneGen: Efficient One-Pass Unified Generation and Retrieval for LLMs

0
🛸
Sign in to get full access
Overview
- Large Language Models (LLMs) have made significant advancements in generative capabilities for various NLP tasks.
- However, LLMs still face limitations in directly handling retrieval tasks.
- Many practical applications require the seamless integration of both retrieval and generation.
Plain English Explanation
The paper introduces a novel framework called OneGen that aims to improve LLMs' performance on tasks that require both generation and retrieval.
Traditionally, generation and retrieval have been approached separately, but OneGen bridges this gap by incorporating retrieval tokens generated autoregressively. This allows a single LLM to handle both tasks simultaneously in a unified forward pass, without the need for separate training approaches.
The researchers validate OneGen's effectiveness and efficiency by testing it on two distinct types of composite tasks: RAG and Entity Linking. The results show that integrating generation and retrieval within the same context preserves the generative capabilities of LLMs while improving retrieval performance.
Technical Explanation
The OneGen framework is designed to enable LLMs to conduct vector retrieval during the generation process. This is achieved by incorporating retrieval tokens generated autoregressively, which allows a single LLM to handle both generation and retrieval tasks simultaneously in a unified forward pass.
The researchers conduct experiments on two distinct types of composite tasks: RAG and Entity Linking. The results demonstrate OneGen's pluggability, effectiveness, and efficiency in both training and inference. The key insight is that integrating generation and retrieval within the same context preserves the generative capabilities of LLMs while improving retrieval performance.
Critical Analysis
The paper acknowledges that while OneGen provides a promising approach to unifying generation and retrieval tasks, there may be limitations or challenges that were not addressed. For example, the performance of OneGen on a wider range of composite tasks or its scalability to larger-scale datasets could be further explored.
Additionally, the paper does not delve into the potential trade-offs or challenges that may arise from integrating generation and retrieval within the same context. Researchers may want to investigate any potential drawbacks or unexpected behaviors that could emerge from this unified approach.
Conclusion
The OneGen framework represents a significant step towards bridging the gap between generation and retrieval tasks in LLMs. By enabling a single LLM to handle both tasks simultaneously, OneGen has the potential to improve the performance and efficiency of various practical applications that require the seamless integration of these capabilities.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🛸
0
OneGen: Efficient One-Pass Unified Generation and Retrieval for LLMs
Jintian Zhang, Cheng Peng, Mengshu Sun, Xiang Chen, Lei Liang, Zhiqiang Zhang, Jun Zhou, Huajun Chen, Ningyu Zhang
Despite the recent advancements in Large Language Models (LLMs), which have significantly enhanced the generative capabilities for various NLP tasks, LLMs still face limitations in directly handling retrieval tasks. However, many practical applications demand the seamless integration of both retrieval and generation. This paper introduces a novel and efficient One-pass Generation and retrieval framework (OneGen), designed to improve LLMs' performance on tasks that require both generation and retrieval. The proposed framework bridges the traditionally separate training approaches for generation and retrieval by incorporating retrieval tokens generated autoregressively. This enables a single LLM to handle both tasks simultaneously in a unified forward pass. We conduct experiments on two distinct types of composite tasks, RAG and Entity Linking, to validate the pluggability, effectiveness, and efficiency of OneGen in training and inference. Furthermore, our results show that integrating generation and retrieval within the same context preserves the generative capabilities of LLMs while improving retrieval performance. To the best of our knowledge, OneGen is the first to enable LLMs to conduct vector retrieval during the generation.
Read more9/10/2024
0
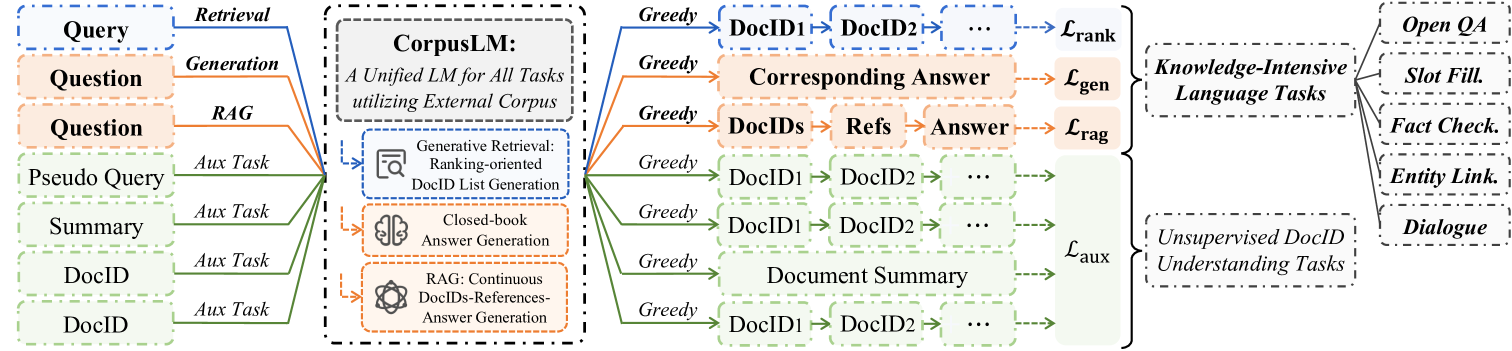
CorpusLM: Towards a Unified Language Model on Corpus for Knowledge-Intensive Tasks
Xiaoxi Li, Zhicheng Dou, Yujia Zhou, Fangchao Liu
Large language models (LLMs) have gained significant attention in various fields but prone to hallucination, especially in knowledge-intensive (KI) tasks. To address this, retrieval-augmented generation (RAG) has emerged as a popular solution to enhance factual accuracy. However, traditional retrieval modules often rely on large document index and disconnect with generative tasks. With the advent of generative retrieval (GR), language models can retrieve by directly generating document identifiers (DocIDs), offering superior performance in retrieval tasks. However, the potential relationship between GR and downstream tasks remains unexplored. In this paper, we propose textbf{CorpusLM}, a unified language model that leverages external corpus to tackle various knowledge-intensive tasks by integrating generative retrieval, closed-book generation, and RAG through a unified greedy decoding process. We design the following mechanisms to facilitate effective retrieval and generation, and improve the end-to-end effectiveness of KI tasks: (1) We develop a ranking-oriented DocID list generation strategy, which refines GR by directly learning from a DocID ranking list, to improve retrieval quality. (2) We design a continuous DocIDs-References-Answer generation strategy, which facilitates effective and efficient RAG. (3) We employ well-designed unsupervised DocID understanding tasks, to comprehend DocID semantics and their relevance to downstream tasks. We evaluate our approach on the widely used KILT benchmark with two variants of backbone models, i.e., T5 and Llama2. Experimental results demonstrate the superior performance of our models in both retrieval and downstream tasks.
Read more4/23/2024

0
Unified Text-to-Image Generation and Retrieval
Leigang Qu, Haochuan Li, Tan Wang, Wenjie Wang, Yongqi Li, Liqiang Nie, Tat-Seng Chua
How humans can efficiently and effectively acquire images has always been a perennial question. A typical solution is text-to-image retrieval from an existing database given the text query; however, the limited database typically lacks creativity. By contrast, recent breakthroughs in text-to-image generation have made it possible to produce fancy and diverse visual content, but it faces challenges in synthesizing knowledge-intensive images. In this work, we rethink the relationship between text-to-image generation and retrieval and propose a unified framework in the context of Multimodal Large Language Models (MLLMs). Specifically, we first explore the intrinsic discriminative abilities of MLLMs and introduce a generative retrieval method to perform retrieval in a training-free manner. Subsequently, we unify generation and retrieval in an autoregressive generation way and propose an autonomous decision module to choose the best-matched one between generated and retrieved images as the response to the text query. Additionally, we construct a benchmark called TIGeR-Bench, including creative and knowledge-intensive domains, to standardize the evaluation of unified text-to-image generation and retrieval. Extensive experimental results on TIGeR-Bench and two retrieval benchmarks, i.e., Flickr30K and MS-COCO, demonstrate the superiority and effectiveness of our proposed method.
Read more6/11/2024

0
UniGen: A Unified Framework for Textual Dataset Generation Using Large Language Models
Siyuan Wu, Yue Huang, Chujie Gao, Dongping Chen, Qihui Zhang, Yao Wan, Tianyi Zhou, Xiangliang Zhang, Jianfeng Gao, Chaowei Xiao, Lichao Sun
Large Language Models (LLMs) such as GPT-4 and Llama3 have significantly impacted various fields by enabling high-quality synthetic data generation and reducing dependence on expensive human-generated datasets. Despite this, challenges remain in the areas of generalization, controllability, diversity, and truthfulness within the existing generative frameworks. To address these challenges, this paper presents UniGen, a comprehensive LLM-powered framework designed to produce diverse, accurate, and highly controllable datasets. UniGen is adaptable, supporting all types of text datasets and enhancing the generative process through innovative mechanisms. To augment data diversity, UniGen incorporates an attribute-guided generation module and a group checking feature. For accuracy, it employs a code-based mathematical assessment for label verification alongside a retrieval-augmented generation technique for factual validation. The framework also allows for user-specified constraints, enabling customization of the data generation process to suit particular requirements. Extensive experiments demonstrate the superior quality of data generated by UniGen, and each module within UniGen plays a critical role in this enhancement. Additionally, UniGen is applied in two practical scenarios: benchmarking LLMs and data augmentation. The results indicate that UniGen effectively supports dynamic and evolving benchmarking, and that data augmentation improves LLM capabilities in various domains, including agent-oriented abilities and reasoning skills.
Read more8/26/2024