UniGen: A Unified Framework for Textual Dataset Generation Using Large Language Models

0

Sign in to get full access
Overview
• This paper introduces UniGen, a unified framework for generating diverse textual datasets using large language models (LLMs).
• UniGen aims to address the challenge of data scarcity in natural language processing tasks by leveraging the generative capabilities of LLMs to create high-quality synthetic data.
• The framework supports various textual generation tasks, including text generation, data manipulation, and domain generalization, enabling efficient and flexible data creation for a wide range of applications.
Plain English Explanation
The core idea behind UniGen is to use powerful language models, which have been trained on vast amounts of text data, to generate new text that can be used to create datasets for various natural language processing tasks. This is helpful because real-world data can be scarce or difficult to obtain, especially for specialized domains or languages.
UniGen provides a standardized way to leverage these language models to generate diverse and high-quality synthetic text data. This can be useful for tasks like text generation, where you want to create new text that sounds natural, or domain generalization, where you want to train machine learning models that can perform well across a variety of domains.
The key advantage of UniGen is that it allows researchers and practitioners to easily create custom datasets tailored to their specific needs, without having to manually collect and curate data. This can save a lot of time and effort, and help advance the development of natural language processing systems.
Technical Explanation
UniGen is a flexible framework that can be used for a variety of textual dataset generation tasks. The core components of UniGen include:
-
Task-Specific Prompting: UniGen uses task-specific prompting strategies to guide the language model in generating relevant and coherent text for the target task, such as text generation, data manipulation, or domain generalization.
-
Diverse Data Generation: UniGen employs techniques like temperature scaling and top-k sampling to encourage the language model to produce diverse and high-quality text, rather than generating repetitive or low-quality outputs.
-
Quality Control: UniGen includes various quality control mechanisms, such as filtering out low-quality samples and fine-tuning the language model on high-quality data, to ensure the generated datasets meet the desired standards.
-
Unified Interface: UniGen provides a unified interface for users to specify their dataset generation requirements, allowing for easy customization and integration with downstream applications.
The paper presents several case studies demonstrating the effectiveness of UniGen in generating useful datasets for tasks like text generation, data manipulation, and domain generalization. The results show that the UniGen-generated datasets can help improve the performance of machine learning models on these tasks, compared to using only real-world data.
Critical Analysis
The UniGen framework represents a promising approach to addressing the data scarcity challenges faced in many natural language processing tasks. By leveraging the generative capabilities of large language models, UniGen can create diverse and high-quality synthetic data to supplement or even replace manually collected datasets.
However, the paper does acknowledge some limitations and caveats. For example, the quality of the generated data is still dependent on the quality and bias of the underlying language model. Additionally, the effectiveness of UniGen may be influenced by the specific task and domain, and further research is needed to understand its broader applicability.
Researchers and practitioners should also be mindful of potential ethical concerns around the use of synthetic data, such as the risk of perpetuating biases or generating harmful content. Careful monitoring and evaluation of the generated datasets are necessary to ensure their suitability and safety for real-world applications.
Furthermore, while UniGen provides a unified framework for textual dataset generation, the integration with downstream machine learning models and the evaluation of the generated data's impact on model performance could be an area for further exploration and refinement.
Conclusion
The UniGen framework represents a significant advancement in the use of large language models for textual dataset generation. By providing a unified and flexible approach, UniGen can help address the data scarcity challenges faced in many natural language processing tasks, enabling researchers and practitioners to create custom datasets tailored to their specific needs.
The successful case studies presented in the paper demonstrate the potential of UniGen to improve the performance of machine learning models and drive progress in a wide range of applications, from text generation to domain generalization.
As the field of natural language processing continues to evolve, frameworks like UniGen that leverage the power of large language models to generate high-quality synthetic data will likely play an increasingly important role in advancing the state of the art and enabling more robust and versatile language-based systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
UniGen: A Unified Framework for Textual Dataset Generation Using Large Language Models
Siyuan Wu, Yue Huang, Chujie Gao, Dongping Chen, Qihui Zhang, Yao Wan, Tianyi Zhou, Xiangliang Zhang, Jianfeng Gao, Chaowei Xiao, Lichao Sun
Large Language Models (LLMs) such as GPT-4 and Llama3 have significantly impacted various fields by enabling high-quality synthetic data generation and reducing dependence on expensive human-generated datasets. Despite this, challenges remain in the areas of generalization, controllability, diversity, and truthfulness within the existing generative frameworks. To address these challenges, this paper presents UniGen, a comprehensive LLM-powered framework designed to produce diverse, accurate, and highly controllable datasets. UniGen is adaptable, supporting all types of text datasets and enhancing the generative process through innovative mechanisms. To augment data diversity, UniGen incorporates an attribute-guided generation module and a group checking feature. For accuracy, it employs a code-based mathematical assessment for label verification alongside a retrieval-augmented generation technique for factual validation. The framework also allows for user-specified constraints, enabling customization of the data generation process to suit particular requirements. Extensive experiments demonstrate the superior quality of data generated by UniGen, and each module within UniGen plays a critical role in this enhancement. Additionally, UniGen is applied in two practical scenarios: benchmarking LLMs and data augmentation. The results indicate that UniGen effectively supports dynamic and evolving benchmarking, and that data augmentation improves LLM capabilities in various domains, including agent-oriented abilities and reasoning skills.
Read more8/26/2024
🛸
0
OneGen: Efficient One-Pass Unified Generation and Retrieval for LLMs
Jintian Zhang, Cheng Peng, Mengshu Sun, Xiang Chen, Lei Liang, Zhiqiang Zhang, Jun Zhou, Huajun Chen, Ningyu Zhang
Despite the recent advancements in Large Language Models (LLMs), which have significantly enhanced the generative capabilities for various NLP tasks, LLMs still face limitations in directly handling retrieval tasks. However, many practical applications demand the seamless integration of both retrieval and generation. This paper introduces a novel and efficient One-pass Generation and retrieval framework (OneGen), designed to improve LLMs' performance on tasks that require both generation and retrieval. The proposed framework bridges the traditionally separate training approaches for generation and retrieval by incorporating retrieval tokens generated autoregressively. This enables a single LLM to handle both tasks simultaneously in a unified forward pass. We conduct experiments on two distinct types of composite tasks, RAG and Entity Linking, to validate the pluggability, effectiveness, and efficiency of OneGen in training and inference. Furthermore, our results show that integrating generation and retrieval within the same context preserves the generative capabilities of LLMs while improving retrieval performance. To the best of our knowledge, OneGen is the first to enable LLMs to conduct vector retrieval during the generation.
Read more9/10/2024

0
Data Generation using Large Language Models for Text Classification: An Empirical Case Study
Yinheng Li, Rogerio Bonatti, Sara Abdali, Justin Wagle, Kazuhito Koishida
Using Large Language Models (LLMs) to generate synthetic data for model training has become increasingly popular in recent years. While LLMs are capable of producing realistic training data, the effectiveness of data generation is influenced by various factors, including the choice of prompt, task complexity, and the quality, quantity, and diversity of the generated data. In this work, we focus exclusively on using synthetic data for text classification tasks. Specifically, we use natural language understanding (NLU) models trained on synthetic data to assess the quality of synthetic data from different generation approaches. This work provides an empirical analysis of the impact of these factors and offers recommendations for better data generation practices.
Read more7/23/2024
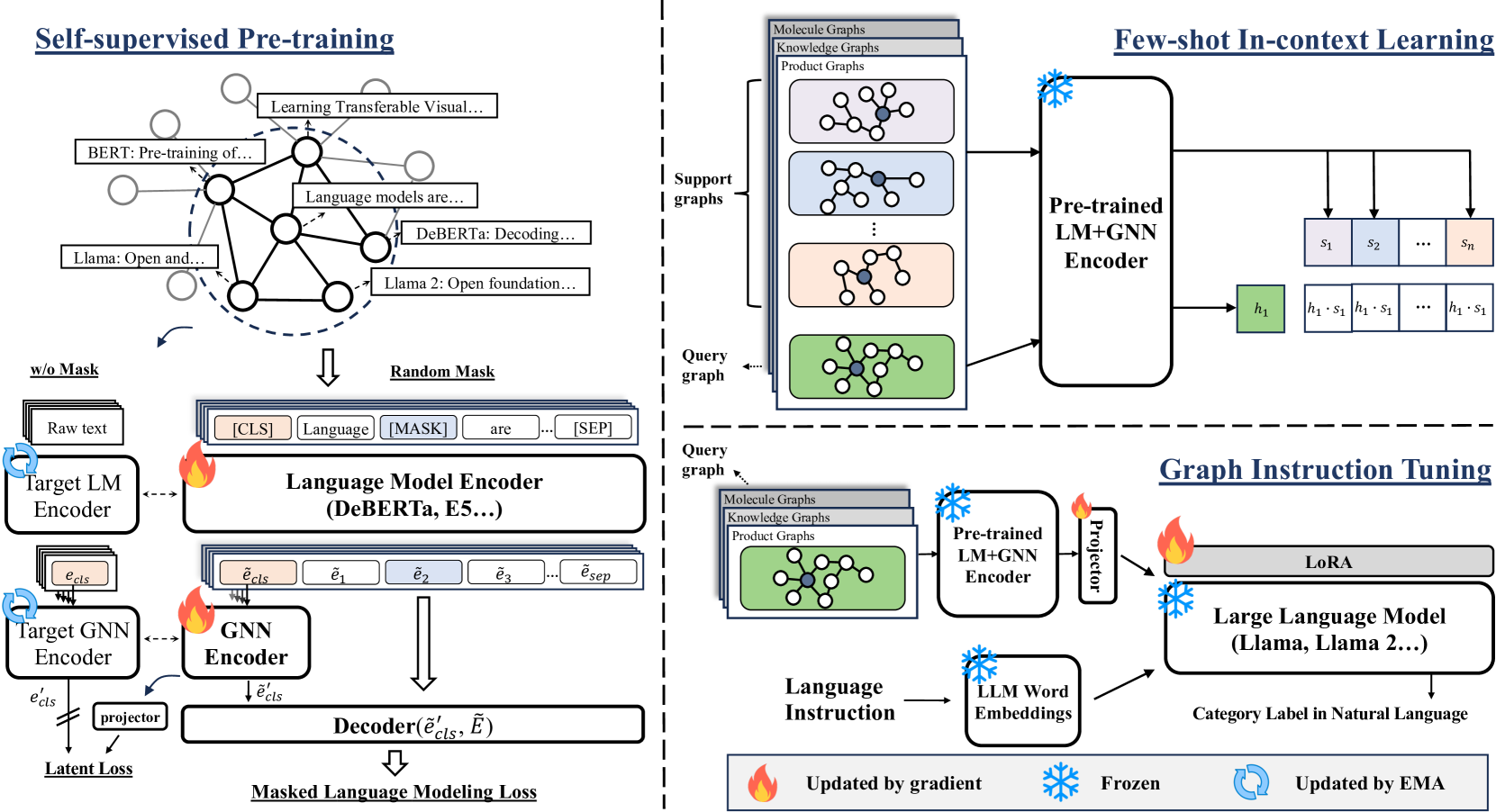
0
UniGraph: Learning a Unified Cross-Domain Foundation Model for Text-Attributed Graphs
Yufei He, Yuan Sui, Xiaoxin He, Bryan Hooi
Foundation models like ChatGPT and GPT-4 have revolutionized artificial intelligence, exhibiting remarkable abilities to generalize across a wide array of tasks and applications beyond their initial training objectives. However, graph learning has predominantly focused on single-graph models, tailored to specific tasks or datasets, lacking the ability to transfer learned knowledge to different domains. This limitation stems from the inherent complexity and diversity of graph structures, along with the different feature and label spaces specific to graph data. In this paper, we recognize text as an effective unifying medium and employ Text-Attributed Graphs (TAGs) to leverage this potential. We present our UniGraph framework, designed to learn a foundation model for TAGs, which is capable of generalizing to unseen graphs and tasks across diverse domains. Unlike single-graph models that use pre-computed node features of varying dimensions as input, our approach leverages textual features for unifying node representations, even for graphs such as molecular graphs that do not naturally have textual features. We propose a novel cascaded architecture of Language Models (LMs) and Graph Neural Networks (GNNs) as backbone networks. Additionally, we propose the first pre-training algorithm specifically designed for large-scale self-supervised learning on TAGs, based on Masked Graph Modeling. We introduce graph instruction tuning using Large Language Models (LLMs) to enable zero-shot prediction ability. Our comprehensive experiments across various graph learning tasks and domains demonstrate the model's effectiveness in self-supervised representation learning on unseen graphs, few-shot in-context transfer, and zero-shot transfer, even surpassing or matching the performance of GNNs that have undergone supervised training on target datasets.
Read more8/27/2024