Online Anchor-based Training for Image Classification Tasks

0

Sign in to get full access
Overview
- This paper proposes an online anchor-based training approach for image classification tasks.
- The key idea is to use anchor points, which represent prototypes of different classes, to guide the training process and improve the model's performance.
- The authors demonstrate the effectiveness of this approach on several image classification benchmarks, showing improvements over traditional training methods.
Plain English Explanation
The paper presents a new way to train image classification models. Instead of the usual training process, the researchers use "anchor points" to help guide the model during learning. Anchor points are like representative examples of each class that the model can refer to.
The model tries to move its internal representations closer to the relevant anchor points for each image it sees. This helps the model learn more effectively and accurately classify new images. The authors show that this "anchor-based" training approach outperforms standard training methods on several popular image classification datasets.
The key advantage of this technique is that it provides the model with extra guidance during training, similar to how a human learner might benefit from examples or prototypes of different categories. By anchoring the model's representations to these class-specific reference points, the training process becomes more efficient and the final model performs better on the target task.
Technical Explanation
The paper introduces an online anchor-based training approach for image classification tasks. The core idea is to leverage a set of anchor points, which represent prototypes or exemplars of the different classes, to guide the training of the classification model.
During training, the model not only tries to minimize the classification loss on the input images, but also tries to align its internal representations with the relevant anchor points. This is achieved by adding an anchor-based regularization term to the overall loss function.
The anchor points are initialized randomly and then updated in an online fashion as the training progresses. This allows the anchor points to adapt and become better representations of the underlying classes, further improving the model's performance.
The authors evaluate their approach on several image classification benchmarks, including CIFAR-10, CIFAR-100, and ImageNet. The results demonstrate that the anchor-based training consistently outperforms standard training methods, achieving higher classification accuracy.
Critical Analysis
The paper presents a novel and promising approach for training image classification models. The use of anchor points as a form of guidance during training is an interesting idea that leverages insights from how humans learn.
One potential limitation is the computational overhead of maintaining and updating the anchor points during training. The authors address this by proposing an efficient online update procedure, but the additional computational cost may be a concern, especially for large-scale datasets.
Another area for further investigation is the sensitivity of the approach to the initialization and update mechanism of the anchor points. The authors briefly explore different strategies, but a more comprehensive analysis of the impact of these design choices could provide valuable insights.
Additionally, the paper focuses on standard image classification tasks, but it would be interesting to see how the anchor-based training approach performs in more challenging or specialized computer vision scenarios, such as news subject conditioning or active learning for imbalanced datasets.
Overall, the paper presents a solid contribution to the field of image classification, offering a novel training technique that demonstrates promising results. Further exploration and refinement of the anchor-based approach could lead to valuable advancements in the development of robust and efficient vision models.
Conclusion
The proposed online anchor-based training method offers a new perspective on training image classification models. By leveraging anchor points as prototypical examples of different classes, the training process becomes more guided and effective, leading to improved classification performance.
The key significance of this work is its potential to enhance the efficiency and accuracy of vision models, which are crucial components in a wide range of real-world applications, from autonomous vehicles to medical imaging. The anchor-based approach provides a framework for incorporating additional structural knowledge into the training process, paving the way for more robust and generalizable models.
As the field of computer vision continues to evolve, techniques like the one presented in this paper will likely play an important role in advancing the state of the art and pushing the boundaries of what is possible with image classification and related tasks.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Online Anchor-based Training for Image Classification Tasks
Maria Tzelepi, Vasileios Mezaris
In this paper, we aim to improve the performance of a deep learning model towards image classification tasks, proposing a novel anchor-based training methodology, named textit{Online Anchor-based Training} (OAT). The OAT method, guided by the insights provided in the anchor-based object detection methodologies, instead of learning directly the class labels, proposes to train a model to learn percentage changes of the class labels with respect to defined anchors. We define as anchors the batch centers at the output of the model. Then, during the test phase, the predictions are converted back to the original class label space, and the performance is evaluated. The effectiveness of the OAT method is validated on four datasets.
Read more6/19/2024

0
On the Use of Anchoring for Training Vision Models
Vivek Narayanaswamy, Kowshik Thopalli, Rushil Anirudh, Yamen Mubarka, Wesam Sakla, Jayaraman J. Thiagarajan
Anchoring is a recent, architecture-agnostic principle for training deep neural networks that has been shown to significantly improve uncertainty estimation, calibration, and extrapolation capabilities. In this paper, we systematically explore anchoring as a general protocol for training vision models, providing fundamental insights into its training and inference processes and their implications for generalization and safety. Despite its promise, we identify a critical problem in anchored training that can lead to an increased risk of learning undesirable shortcuts, thereby limiting its generalization capabilities. To address this, we introduce a new anchored training protocol that employs a simple regularizer to mitigate this issue and significantly enhances generalization. We empirically evaluate our proposed approach across datasets and architectures of varying scales and complexities, demonstrating substantial performance gains in generalization and safety metrics compared to the standard training protocol.
Read more6/4/2024

0
Anchor-based Robust Finetuning of Vision-Language Models
Jinwei Han, Zhiwen Lin, Zhongyisun Sun, Yingguo Gao, Ke Yan, Shouhong Ding, Yuan Gao, Gui-Song Xia
We aim at finetuning a vision-language model without hurting its out-of-distribution (OOD) generalization. We address two types of OOD generalization, i.e., i) domain shift such as natural to sketch images, and ii) zero-shot capability to recognize the category that was not contained in the finetune data. Arguably, the diminished OOD generalization after finetuning stems from the excessively simplified finetuning target, which only provides the class information, such as ``a photo of a [CLASS]''. This is distinct from the process in that CLIP was pretrained, where there is abundant text supervision with rich semantic information. Therefore, we propose to compensate for the finetune process using auxiliary supervision with rich semantic information, which acts as anchors to preserve the OOD generalization. Specifically, two types of anchors are elaborated in our method, including i) text-compensated anchor which uses the images from the finetune set but enriches the text supervision from a pretrained captioner, ii) image-text-pair anchor which is retrieved from the dataset similar to pretraining data of CLIP according to the downstream task, associating with the original CLIP text with rich semantics. Those anchors are utilized as auxiliary semantic information to maintain the original feature space of CLIP, thereby preserving the OOD generalization capabilities. Comprehensive experiments demonstrate that our method achieves in-distribution performance akin to conventional finetuning while attaining new state-of-the-art results on domain shift and zero-shot learning benchmarks.
Read more4/10/2024
0
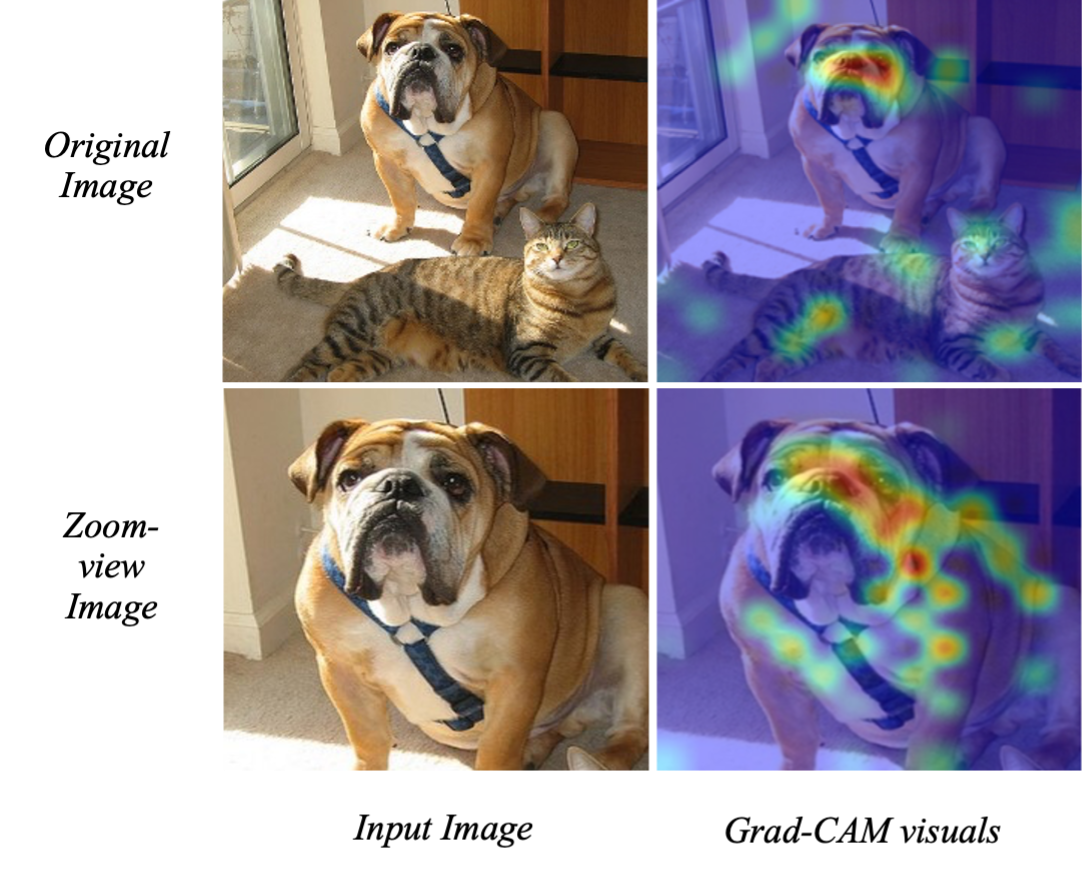
ATAC-Net: Zoomed view works better for Anomaly Detection
Shaurya Gupta, Neil Gautam, Anurag Malyala
The application of deep learning in visual anomaly detection has gained widespread popularity due to its potential use in quality control and manufacturing. Current standard methods are Unsupervised, where a clean dataset is utilised to detect deviations and flag anomalies during testing. However, incorporating a few samples when the type of anomalies is known beforehand can significantly enhance performance. Thus, we propose ATAC-Net, a framework that trains to detect anomalies from a minimal set of known prior anomalies. Furthermore, we introduce attention-guided cropping, which provides a closer view of suspect regions during the training phase. Our framework is a reliable and easy-to-understand system for detecting anomalies, and we substantiate its superiority to some of the current state-of-the-art techniques in a comparable setting.
Read more6/21/2024