ANCHOR: LLM-driven News Subject Conditioning for Text-to-Image Synthesis
2404.10141
0
0

Abstract
Text-to-Image (T2I) Synthesis has made tremendous strides in enhancing synthesized image quality, but current datasets evaluate model performance only on descriptive, instruction-based prompts. Real-world news image captions take a more pragmatic approach, providing high-level situational and Named-Entity (NE) information and limited physical object descriptions, making them abstractive. To evaluate the ability of T2I models to capture intended subjects from news captions, we introduce the Abstractive News Captions with High-level cOntext Representation (ANCHOR) dataset, containing 70K+ samples sourced from 5 different news media organizations. With Large Language Models (LLM) achieving success in language and commonsense reasoning tasks, we explore the ability of different LLMs to identify and understand key subjects from abstractive captions. Our proposed method Subject-Aware Finetuning (SAFE), selects and enhances the representation of key subjects in synthesized images by leveraging LLM-generated subject weights. It also adapts to the domain distribution of news images and captions through custom Domain Fine-tuning, outperforming current T2I baselines on ANCHOR. By launching the ANCHOR dataset, we hope to motivate research in furthering the Natural Language Understanding (NLU) capabilities of T2I models.
Create account to get full access
Overview
- This paper presents a novel approach for conditioning text-to-image synthesis on news subject matter using large language models (LLMs).
- The researchers developed a system that can generate images tailored to specific news topics by leveraging the semantic understanding of LLMs.
- The proposed method aims to improve the relevance and quality of text-to-image synthesis for news-related applications.
Plain English Explanation
The researchers in this paper have developed a new way to create images based on news stories using advanced language models. Typically, text-to-image systems can generate images from any text, but the researchers wanted to make the images specifically relevant to news topics.
To do this, they used a large language model - a type of AI system that can understand and generate human-like text. By training this language model on a lot of news articles, it learned to understand the meanings and topics covered in news stories.
The researchers then used this language model as part of their text-to-image system. When you give their system a news-related text prompt, the language model can recognize the specific news topic and subject matter. It then passes this information to the image generation part of the system, which can create an image that is tailored and relevant to that news topic.
This allows the text-to-image system to generate images that are much more closely tied to the news content, rather than just producing a generic image based on the text prompt. This could be very useful for applications like news websites, where the images need to accurately reflect the news stories being reported on.
Technical Explanation
The paper proposes a novel approach for text-to-image synthesis that conditions the image generation on the news subject matter using large language models (LLMs).
The key innovation is the integration of an LLM-based "news subject conditioning" module into the text-to-image synthesis pipeline. This module leverages the semantic understanding of LLMs trained on news corpora to embed the news subject information, which is then used to guide the image generation process.
Specifically, the researchers first fine-tune a pre-trained LLM (e.g., GPT-3) on a large news dataset. This fine-tuned LLM can then encode news-related text prompts into subject-aware embeddings. These embeddings are then concatenated with the text embeddings and fed into the image generation model, allowing the system to produce images that are tailored to the news topics.
The researchers evaluate their approach on several news-oriented text-to-image benchmarks and demonstrate significant improvements in image relevance and quality compared to baselines that do not leverage news subject conditioning. The EAMA and Anchor models are among the state-of-the-art techniques used for comparison.
Critical Analysis
The paper presents a compelling approach to improving text-to-image synthesis for news-related applications. The key strength is the integration of LLM-based news subject conditioning, which allows the system to generate images that are more closely aligned with the specific topics and content of news stories.
However, the paper does not address some potential limitations or areas for further research. For example, the performance of the system may be dependent on the quality and breadth of the news dataset used for fine-tuning the LLM. Additionally, the paper does not explore the generalizability of the approach to domains beyond news, such as other specialized text-to-image tasks.
Further research could also investigate the robustness of the system to noisy or adversarial text prompts, as well as the potential for cost-efficient dataset curation to support the training of such news-oriented text-to-image models.
Conclusion
This paper presents a novel approach for conditioning text-to-image synthesis on news subject matter using large language models. By integrating an LLM-based news subject conditioning module, the researchers have developed a system that can generate images that are more closely aligned with the content and topics of news stories.
The proposed method has the potential to significantly improve the relevance and quality of text-to-image synthesis for news-related applications, which could be valuable for media outlets, journalism, and other domains where accurate visual representation of news content is important. Further research exploring the limitations and generalizability of this approach could lead to even more advanced text-to-image systems tailored for specialized domains.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
Synth$^2$: Boosting Visual-Language Models with Synthetic Captions and Image Embeddings
Sahand Sharifzadeh, Christos Kaplanis, Shreya Pathak, Dharshan Kumaran, Anastasija Ilic, Jovana Mitrovic, Charles Blundell, Andrea Banino
0
0
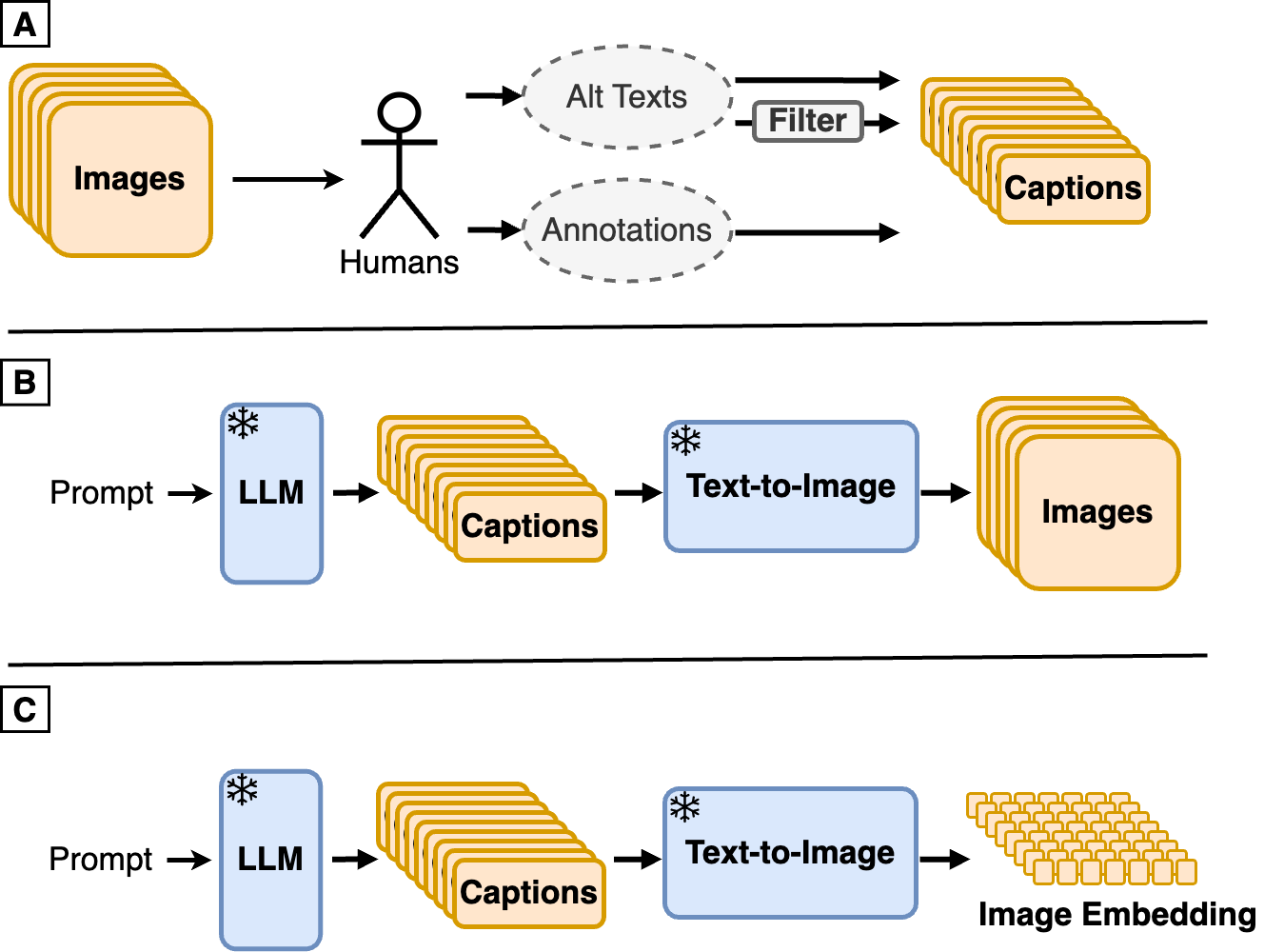
The creation of high-quality human-labeled image-caption datasets presents a significant bottleneck in the development of Visual-Language Models (VLMs). In this work, we investigate an approach that leverages the strengths of Large Language Models (LLMs) and image generation models to create synthetic image-text pairs for efficient and effective VLM training. Our method employs a pretrained text-to-image model to synthesize image embeddings from captions generated by an LLM. Despite the text-to-image model and VLM initially being trained on the same data, our approach leverages the image generator's ability to create novel compositions, resulting in synthetic image embeddings that expand beyond the limitations of the original dataset. Extensive experiments demonstrate that our VLM, finetuned on synthetic data achieves comparable performance to models trained solely on human-annotated data, while requiring significantly less data. Furthermore, we perform a set of analyses on captions which reveals that semantic diversity and balance are key aspects for better downstream performance. Finally, we show that synthesizing images in the image embedding space is 25% faster than in the pixel space. We believe our work not only addresses a significant challenge in VLM training but also opens up promising avenues for the development of self-improving multi-modal models.
6/10/2024
EAMA : Entity-Aware Multimodal Alignment Based Approach for News Image Captioning
Junzhe Zhang, Huixuan Zhang, Xunjian Yin, Xiaojun Wan
0
0
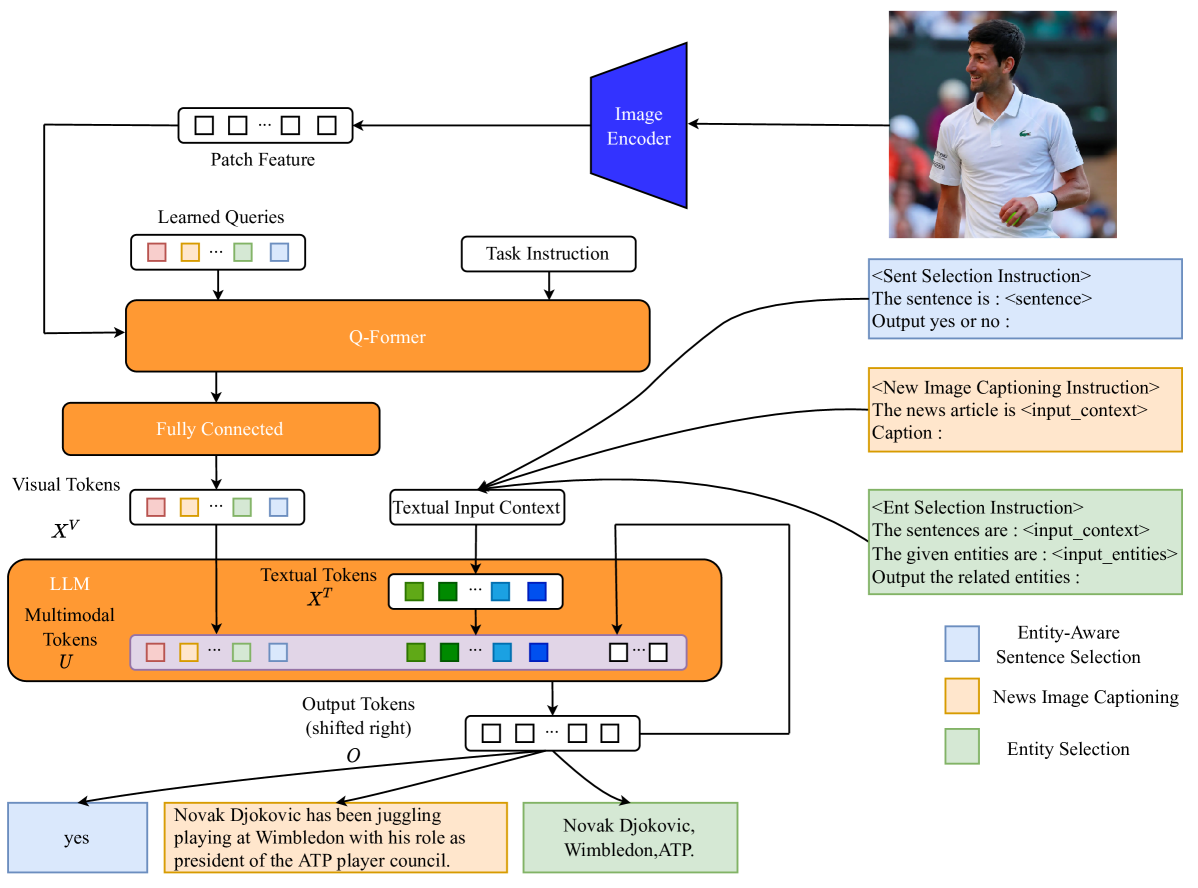
News image captioning requires model to generate an informative caption rich in entities, with the news image and the associated news article. Though Multimodal Large Language Models (MLLMs) have demonstrated remarkable capabilities in addressing various vision-language tasks, our research finds that current MLLMs still bear limitations in handling entity information on news image captioning task. Besides, while MLLMs have the ability to process long inputs, generating high-quality news image captions still requires a trade-off between sufficiency and conciseness of textual input information. To explore the potential of MLLMs and address problems we discovered, we propose : an Entity-Aware Multimodal Alignment based approach for news image captioning. Our approach first aligns the MLLM through Balance Training Strategy with two extra alignment tasks: Entity-Aware Sentence Selection task and Entity Selection task, together with News Image Captioning task, to enhance its capability in handling multimodal entity information. The aligned MLLM will utilizes the additional entity-related information it explicitly extracts to supplement its textual input while generating news image captions. Our approach achieves better results than all previous models in CIDEr score on GoodNews dataset (72.33 -> 88.39) and NYTimes800k dataset (70.83 -> 85.61).
5/7/2024
💬
Anchor-based Large Language Models
Jianhui Pang, Fanghua Ye, Derek Fai Wong, Xin He, Wanshun Chen, Longyue Wang
0
0
Large language models (LLMs) predominantly employ decoder-only transformer architectures, necessitating the retention of keys/values information for historical tokens to provide contextual information and avoid redundant computation. However, the substantial size and parameter volume of these LLMs require massive GPU memory. This memory demand increases with the length of the input text, leading to an urgent need for more efficient methods of information storage and processing. This study introduces Anchor-based LLMs (AnLLMs), which utilize an innovative anchor-based self-attention network (AnSAN) and also an anchor-based inference strategy. This approach enables LLMs to compress sequence information into an anchor token, reducing the keys/values cache and enhancing inference efficiency. Experiments on question-answering benchmarks reveal that AnLLMs maintain similar accuracy levels while achieving up to 99% keys/values cache reduction and up to 3.5 times faster inference. Despite a minor compromise in accuracy, the substantial enhancements of AnLLMs employing the AnSAN technique in resource utilization and computational efficiency underscore their potential for practical LLM applications.
6/4/2024

Anchor-based Robust Finetuning of Vision-Language Models
Jinwei Han, Zhiwen Lin, Zhongyisun Sun, Yingguo Gao, Ke Yan, Shouhong Ding, Yuan Gao, Gui-Song Xia
0
0
We aim at finetuning a vision-language model without hurting its out-of-distribution (OOD) generalization. We address two types of OOD generalization, i.e., i) domain shift such as natural to sketch images, and ii) zero-shot capability to recognize the category that was not contained in the finetune data. Arguably, the diminished OOD generalization after finetuning stems from the excessively simplified finetuning target, which only provides the class information, such as ``a photo of a [CLASS]''. This is distinct from the process in that CLIP was pretrained, where there is abundant text supervision with rich semantic information. Therefore, we propose to compensate for the finetune process using auxiliary supervision with rich semantic information, which acts as anchors to preserve the OOD generalization. Specifically, two types of anchors are elaborated in our method, including i) text-compensated anchor which uses the images from the finetune set but enriches the text supervision from a pretrained captioner, ii) image-text-pair anchor which is retrieved from the dataset similar to pretraining data of CLIP according to the downstream task, associating with the original CLIP text with rich semantics. Those anchors are utilized as auxiliary semantic information to maintain the original feature space of CLIP, thereby preserving the OOD generalization capabilities. Comprehensive experiments demonstrate that our method achieves in-distribution performance akin to conventional finetuning while attaining new state-of-the-art results on domain shift and zero-shot learning benchmarks.
4/10/2024