Online Learning and Information Exponents: On The Importance of Batch size, and Time/Complexity Tradeoffs

0

Sign in to get full access
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Online Learning and Information Exponents: On The Importance of Batch size, and Time/Complexity Tradeoffs
Luca Arnaboldi, Yatin Dandi, Florent Krzakala, Bruno Loureiro, Luca Pesce, Ludovic Stephan
We study the impact of the batch size $n_b$ on the iteration time $T$ of training two-layer neural networks with one-pass stochastic gradient descent (SGD) on multi-index target functions of isotropic covariates. We characterize the optimal batch size minimizing the iteration time as a function of the hardness of the target, as characterized by the information exponents. We show that performing gradient updates with large batches $n_b lesssim d^{frac{ell}{2}}$ minimizes the training time without changing the total sample complexity, where $ell$ is the information exponent of the target to be learned citep{arous2021online} and $d$ is the input dimension. However, larger batch sizes than $n_b gg d^{frac{ell}{2}}$ are detrimental for improving the time complexity of SGD. We provably overcome this fundamental limitation via a different training protocol, textit{Correlation loss SGD}, which suppresses the auto-correlation terms in the loss function. We show that one can track the training progress by a system of low-dimensional ordinary differential equations (ODEs). Finally, we validate our theoretical results with numerical experiments.
Read more6/5/2024

0
The Benefits of Reusing Batches for Gradient Descent in Two-Layer Networks: Breaking the Curse of Information and Leap Exponents
Yatin Dandi, Emanuele Troiani, Luca Arnaboldi, Luca Pesce, Lenka Zdeborov'a, Florent Krzakala
We investigate the training dynamics of two-layer neural networks when learning multi-index target functions. We focus on multi-pass gradient descent (GD) that reuses the batches multiple times and show that it significantly changes the conclusion about which functions are learnable compared to single-pass gradient descent. In particular, multi-pass GD with finite stepsize is found to overcome the limitations of gradient flow and single-pass GD given by the information exponent (Ben Arous et al., 2021) and leap exponent (Abbe et al., 2023) of the target function. We show that upon re-using batches, the network achieves in just two time steps an overlap with the target subspace even for functions not satisfying the staircase property (Abbe et al., 2021). We characterize the (broad) class of functions efficiently learned in finite time. The proof of our results is based on the analysis of the Dynamical Mean-Field Theory (DMFT). We further provide a closed-form description of the dynamical process of the low-dimensional projections of the weights, and numerical experiments illustrating the theory.
Read more7/2/2024
0
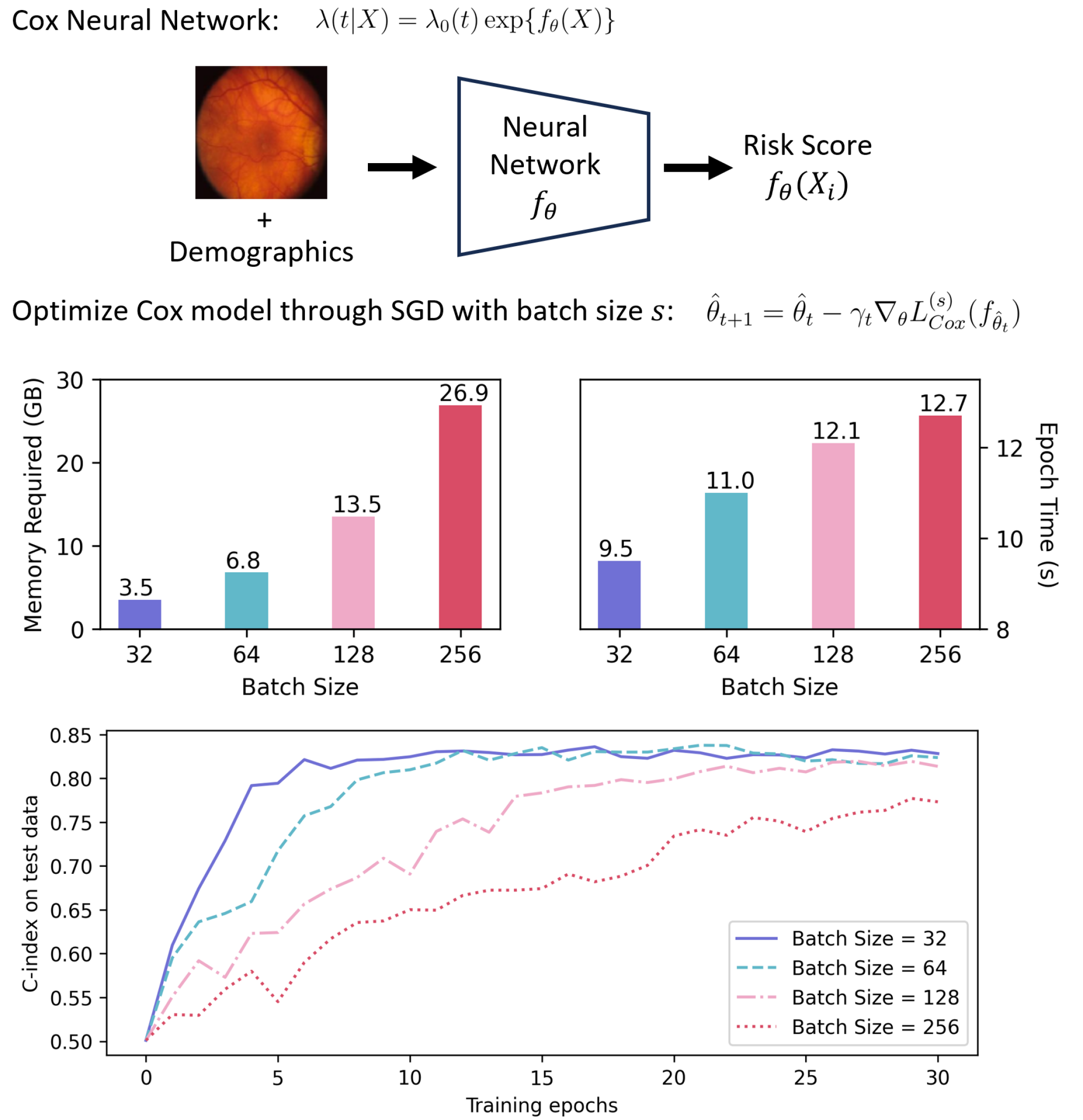
Optimizing Cox Models with Stochastic Gradient Descent: Theoretical Foundations and Practical Guidances
Lang Zeng, Weijing Tang, Zhao Ren, Ying Ding
Optimizing Cox regression and its neural network variants poses substantial computational challenges in large-scale studies. Stochastic gradient descent (SGD), known for its scalability in model optimization, has recently been adapted to optimize Cox models. Unlike its conventional application, which typically targets a sum of independent individual loss, SGD for Cox models updates parameters based on the partial likelihood of a subset of data. Despite its empirical success, the theoretical foundation for optimizing Cox partial likelihood with SGD is largely underexplored. In this work, we demonstrate that the SGD estimator targets an objective function that is batch-size-dependent. We establish that the SGD estimator for the Cox neural network (Cox-NN) is consistent and achieves the optimal minimax convergence rate up to a polylogarithmic factor. For Cox regression, we further prove the $sqrt{n}$-consistency and asymptotic normality of the SGD estimator, with variance depending on the batch size. Furthermore, we quantify the impact of batch size on Cox-NN training and its effect on the SGD estimator's asymptotic efficiency in Cox regression. These findings are validated by extensive numerical experiments and provide guidance for selecting batch sizes in SGD applications. Finally, we demonstrate the effectiveness of SGD in a real-world application where GD is unfeasible due to the large scale of data.
Read more8/7/2024

0
Beyond Implicit Bias: The Insignificance of SGD Noise in Online Learning
Nikhil Vyas, Depen Morwani, Rosie Zhao, Gal Kaplun, Sham Kakade, Boaz Barak
The success of SGD in deep learning has been ascribed by prior works to the implicit bias induced by finite batch sizes (SGD noise). While prior works focused on offline learning (i.e., multiple-epoch training), we study the impact of SGD noise on online (i.e., single epoch) learning. Through an extensive empirical analysis of image and language data, we demonstrate that small batch sizes do not confer any implicit bias advantages in online learning. In contrast to offline learning, the benefits of SGD noise in online learning are strictly computational, facilitating more cost-effective gradient steps. This suggests that SGD in the online regime can be construed as taking noisy steps along the golden path of the noiseless gradient descent algorithm. We study this hypothesis and provide supporting evidence in loss and function space. Our findings challenge the prevailing understanding of SGD and offer novel insights into its role in online learning.
Read more6/10/2024