Optimizing Cox Models with Stochastic Gradient Descent: Theoretical Foundations and Practical Guidances

0
Sign in to get full access
Overview
- Examines the use of stochastic gradient descent (SGD) to optimize Cox proportional hazards models, which are commonly used in survival analysis.
- Provides a theoretical foundation for understanding the convergence properties of SGD for Cox models.
- Offers practical guidance on hyperparameter tuning and other implementation details to improve the performance of SGD for Cox model optimization.
Plain English Explanation
Survival analysis is a field of statistics that studies how long it takes for certain events to occur, such as the time until a patient's disease progresses or they pass away. One of the most widely used models in survival analysis is the Cox proportional hazards model, which allows researchers to understand how different factors influence the risk of an event occurring.
To fit a Cox model, researchers typically use a optimization technique called stochastic gradient descent (SGD). SGD is a powerful algorithm that can efficiently find the best set of model parameters, even for very large datasets. However, applying SGD to Cox models presents some unique challenges.
This paper provides a detailed theoretical analysis of how SGD behaves when optimizing Cox models. The authors establish important convergence guarantees, showing that SGD can reliably find the optimal model parameters under certain conditions.
The paper also offers practical guidance on how to effectively use SGD for Cox model optimization in real-world applications. This includes recommendations on how to tune hyperparameters like the learning rate and batch size to achieve the best performance.
Overall, this work provides a solid foundation for understanding the theoretical properties of SGD for Cox models, as well as actionable insights to help practitioners get the most out of this powerful optimization technique.
Technical Explanation
The primary focus of this paper is to analyze the convergence properties of stochastic gradient descent (SGD) when used to optimize the Cox proportional hazards model, a widely used tool in survival analysis.
The authors begin by formulating the Cox model optimization problem and highlighting the unique challenges it poses for SGD, such as the non-convex and non-smooth nature of the objective function. They then provide a detailed theoretical analysis of SGD's behavior in this setting, establishing convergence guarantees and characterizing the impact of various algorithmic choices.
Specifically, the paper shows that SGD can reliably converge to the optimal model parameters under certain conditions, such as the existence of a unique minimizer and appropriate selection of the learning rate and batch size. The authors also derive bounds on the convergence rate and discuss the tradeoffs between different algorithmic configurations.
In addition to the theoretical contributions, the paper provides practical guidance on how to effectively use SGD for Cox model optimization. This includes recommendations on hyperparameter tuning, initialization strategies, and other implementation details that can help practitioners achieve the best possible performance on real-world survival analysis tasks.
Critical Analysis
The paper provides a strong theoretical foundation for understanding the convergence properties of SGD when applied to Cox proportional hazards models. The authors' analysis is rigorous and their results are well-supported, offering valuable insights for researchers and practitioners working in the field of survival analysis.
One potential limitation of the work is that the theoretical analysis is based on certain assumptions, such as the existence of a unique minimizer and the availability of unbiased stochastic gradients. While these assumptions are reasonable in many practical settings, it would be interesting to see how the results generalize to more relaxed conditions, such as when the objective function has multiple local minima or the stochastic gradients are noisy.
Additionally, the paper focuses primarily on the optimization aspect of Cox model fitting and does not delve deeply into the statistical properties of the resulting models. It would be valuable to see a more comprehensive evaluation of the models' predictive performance, calibration, and interpretability, as these are crucial considerations in many real-world applications.
Overall, this paper makes a significant contribution to the understanding of SGD for Cox model optimization and provides a solid foundation for further research in this area. The practical guidance offered can also be highly useful for data scientists and statisticians looking to apply these techniques in their own work.
Conclusion
This paper provides a rigorous analysis of using stochastic gradient descent (SGD) to optimize Cox proportional hazards models, which are widely used in survival analysis. The authors establish important theoretical guarantees on the convergence of SGD for Cox model optimization and offer practical guidance to help practitioners effectively apply this technique in real-world settings.
By bridging the gap between the theoretical foundations and practical considerations, this work advances the state of the art in survival analysis and helps researchers and data scientists better understand how to leverage the power of SGD for their modeling needs. The insights and recommendations provided in this paper can have a significant impact on the field, enabling more accurate and efficient analysis of time-to-event data.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Optimizing Cox Models with Stochastic Gradient Descent: Theoretical Foundations and Practical Guidances
Lang Zeng, Weijing Tang, Zhao Ren, Ying Ding
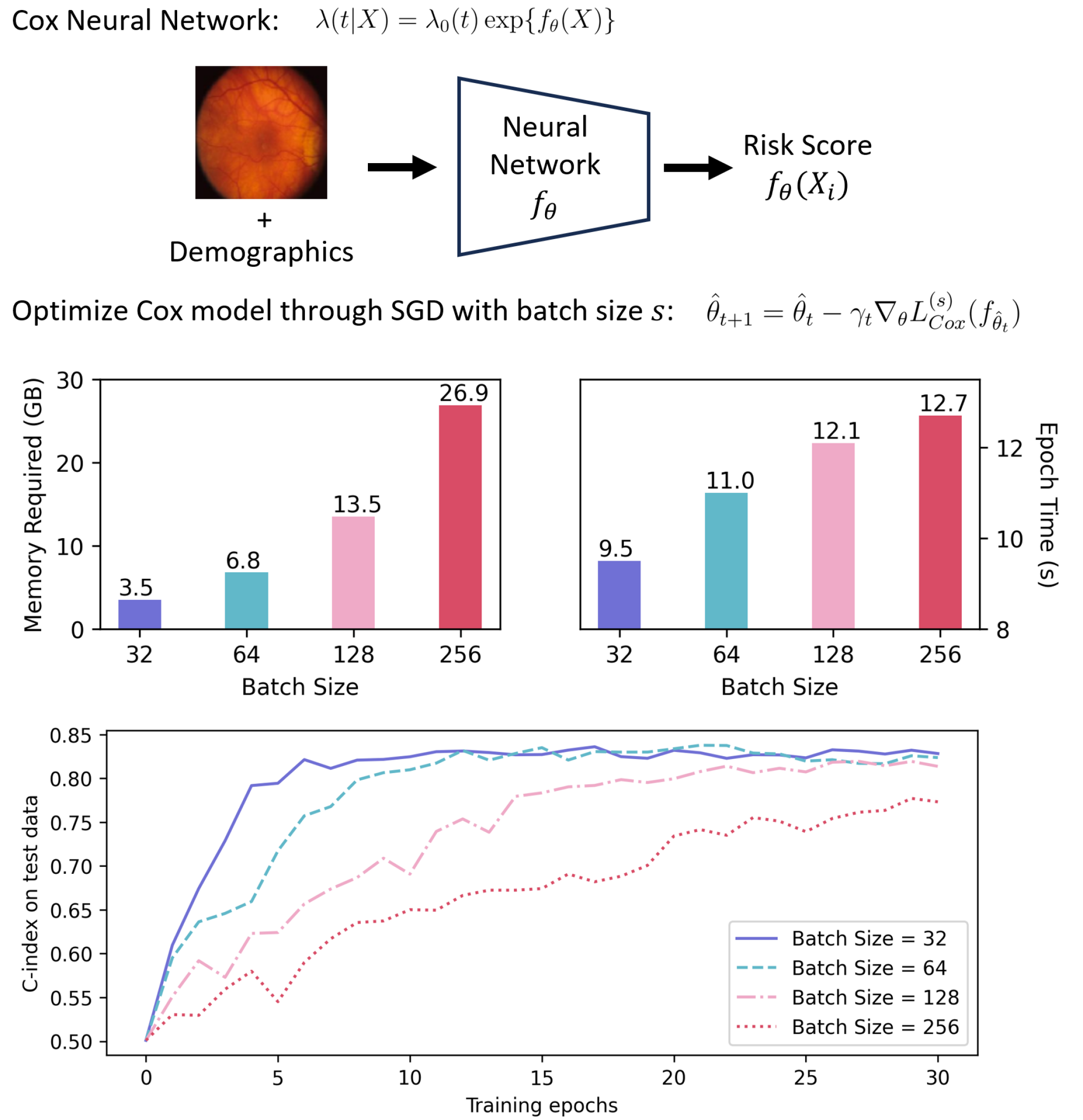
Optimizing Cox regression and its neural network variants poses substantial computational challenges in large-scale studies. Stochastic gradient descent (SGD), known for its scalability in model optimization, has recently been adapted to optimize Cox models. Unlike its conventional application, which typically targets a sum of independent individual loss, SGD for Cox models updates parameters based on the partial likelihood of a subset of data. Despite its empirical success, the theoretical foundation for optimizing Cox partial likelihood with SGD is largely underexplored. In this work, we demonstrate that the SGD estimator targets an objective function that is batch-size-dependent. We establish that the SGD estimator for the Cox neural network (Cox-NN) is consistent and achieves the optimal minimax convergence rate up to a polylogarithmic factor. For Cox regression, we further prove the $sqrt{n}$-consistency and asymptotic normality of the SGD estimator, with variance depending on the batch size. Furthermore, we quantify the impact of batch size on Cox-NN training and its effect on the SGD estimator's asymptotic efficiency in Cox regression. These findings are validated by extensive numerical experiments and provide guidance for selecting batch sizes in SGD applications. Finally, we demonstrate the effectiveness of SGD in a real-world application where GD is unfeasible due to the large scale of data.
Read more8/7/2024
🛠️
0
Using Stochastic Gradient Descent to Smooth Nonconvex Functions: Analysis of Implicit Graduated Optimization with Optimal Noise Scheduling
Naoki Sato, Hideaki Iiduka
The graduated optimization approach is a heuristic method for finding globally optimal solutions for nonconvex functions and has been theoretically analyzed in several studies. This paper defines a new family of nonconvex functions for graduated optimization, discusses their sufficient conditions, and provides a convergence analysis of the graduated optimization algorithm for them. It shows that stochastic gradient descent (SGD) with mini-batch stochastic gradients has the effect of smoothing the objective function, the degree of which is determined by the learning rate, batch size, and variance of the stochastic gradient. This finding provides theoretical insights on why large batch sizes fall into sharp local minima, why decaying learning rates and increasing batch sizes are superior to fixed learning rates and batch sizes, and what the optimal learning rate scheduling is. To the best of our knowledge, this is the first paper to provide a theoretical explanation for these aspects. In addition, we show that the degree of smoothing introduced is strongly correlated with the generalization performance of the model. Moreover, a new graduated optimization framework that uses a decaying learning rate and increasing batch size is analyzed and experimental results of image classification are reported that support our theoretical findings.
Read more7/16/2024

0
New!The Optimality of (Accelerated) SGD for High-Dimensional Quadratic Optimization
Haihan Zhang, Yuanshi Liu, Qianwen Chen, Cong Fang
Stochastic gradient descent (SGD) is a widely used algorithm in machine learning, particularly for neural network training. Recent studies on SGD for canonical quadratic optimization or linear regression show it attains well generalization under suitable high-dimensional settings. However, a fundamental question -- for what kinds of high-dimensional learning problems SGD and its accelerated variants can achieve optimality has yet to be well studied. This paper investigates SGD with two essential components in practice: exponentially decaying step size schedule and momentum. We establish the convergence upper bound for momentum accelerated SGD (ASGD) and propose concrete classes of learning problems under which SGD or ASGD achieves min-max optimal convergence rates. The characterization of the target function is based on standard power-law decays in (functional) linear regression. Our results unveil new insights for understanding the learning bias of SGD: (i) SGD is efficient in learning ``dense'' features where the corresponding weights are subject to an infinity norm constraint; (ii) SGD is efficient for easy problem without suffering from the saturation effect; (iii) momentum can accelerate the convergence rate by order when the learning problem is relatively hard. To our knowledge, this is the first work to clearly identify the optimal boundary of SGD versus ASGD for the problem under mild settings.
Read more9/17/2024
0
Derivatives of Stochastic Gradient Descent
Franck Iutzeler, Edouard Pauwels, Samuel Vaiter
We consider stochastic optimization problems where the objective depends on some parameter, as commonly found in hyperparameter optimization for instance. We investigate the behavior of the derivatives of the iterates of Stochastic Gradient Descent (SGD) with respect to that parameter and show that they are driven by an inexact SGD recursion on a different objective function, perturbed by the convergence of the original SGD. This enables us to establish that the derivatives of SGD converge to the derivative of the solution mapping in terms of mean squared error whenever the objective is strongly convex. Specifically, we demonstrate that with constant step-sizes, these derivatives stabilize within a noise ball centered at the solution derivative, and that with vanishing step-sizes they exhibit $O(log(k)^2 / k)$ convergence rates. Additionally, we prove exponential convergence in the interpolation regime. Our theoretical findings are illustrated by numerical experiments on synthetic tasks.
Read more5/28/2024