Online,Target-Free LiDAR-Camera Extrinsic Calibration via Cross-Modal Mask Matching
2404.18083
0
0
⛏️
Abstract
LiDAR-camera extrinsic calibration (LCEC) is crucial for data fusion in intelligent vehicles. Offline, target-based approaches have long been the preferred choice in this field. However, they often demonstrate poor adaptability to real-world environments. This is largely because extrinsic parameters may change significantly due to moderate shocks or during extended operations in environments with vibrations. In contrast, online, target-free approaches provide greater adaptability yet typically lack robustness, primarily due to the challenges in cross-modal feature matching. Therefore, in this article, we unleash the full potential of large vision models (LVMs), which are emerging as a significant trend in the fields of computer vision and robotics, especially for embodied artificial intelligence, to achieve robust and accurate online, target-free LCEC across a variety of challenging scenarios. Our main contributions are threefold: we introduce a novel framework known as MIAS-LCEC, provide an open-source versatile calibration toolbox with an interactive visualization interface, and publish three real-world datasets captured from various indoor and outdoor environments. The cornerstone of our framework and toolbox is the cross-modal mask matching (C3M) algorithm, developed based on a state-of-the-art (SoTA) LVM and capable of generating sufficient and reliable matches. Extensive experiments conducted on these real-world datasets demonstrate the robustness of our approach and its superior performance compared to SoTA methods, particularly for the solid-state LiDARs with super-wide fields of view.
Create account to get full access
Overview
- Extrinsic calibration between LiDAR and cameras is crucial for data fusion in intelligent vehicles
- Offline, target-based approaches are common but lack adaptability to real-world environments
- Online, target-free approaches are more adaptable but often lack robustness
- This paper introduces a novel framework, MIAS-LCEC, that leverages large vision models (LVMs) to achieve robust and accurate online, target-free LiDAR-camera extrinsic calibration (LCEC)
Plain English Explanation
The paper discusses the importance of accurately aligning data from LiDAR (Light Detection and Ranging) sensors and cameras in intelligent vehicles, a process known as LiDAR-camera extrinsic calibration (LCEC). This is crucial for fusing the information from these two types of sensors to create a comprehensive understanding of the vehicle's surroundings.
Traditionally, the preferred approach has been to use offline, target-based methods, where the vehicle is calibrated using specific calibration targets. However, these methods often struggle to adapt to real-world environments, where factors like moderate shocks or vibrations can significantly change the extrinsic parameters (the relative position and orientation between the LiDAR and camera).
In contrast, online, target-free approaches are more adaptable, as they don't rely on pre-defined calibration targets. But these methods typically lack robustness, primarily due to the challenges in accurately matching features between the LiDAR point cloud and the camera image.
To address these challenges, the researchers in this paper have developed a novel framework called MIAS-LCEC, which leverages the power of large vision models (LVMs), a rapidly growing trend in computer vision and robotics. These powerful AI models, trained on vast amounts of data, can help overcome the feature matching issues that have plagued previous target-free LCEC methods.
Technical Explanation
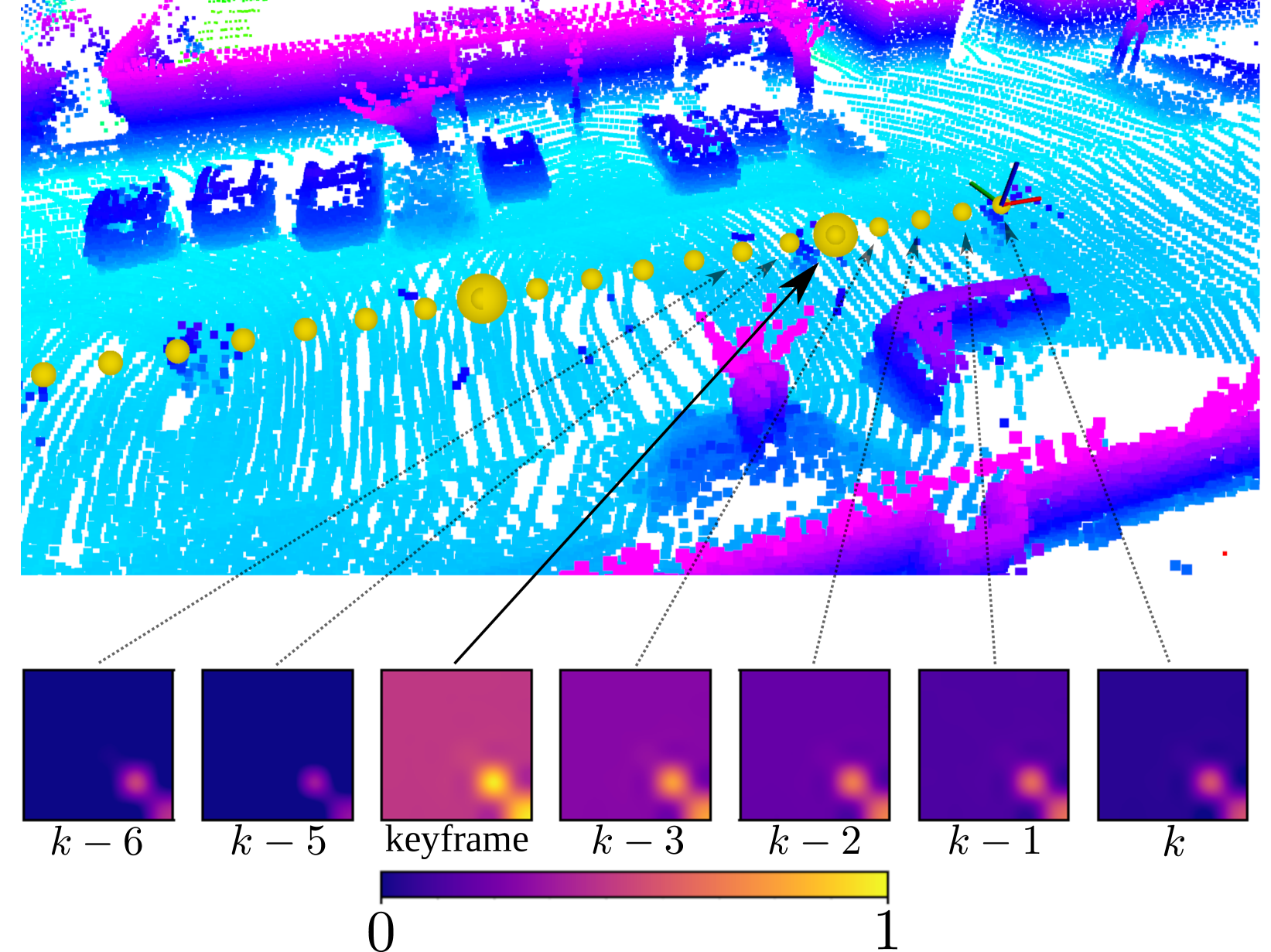
The cornerstone of the MIAS-LCEC framework is the Cross-Modal Mask Matching (C3M) algorithm, which uses a state-of-the-art LVM to generate reliable feature matches between the LiDAR point cloud and the camera image. This allows the system to perform accurate LCEC without the need for calibration targets.
The researchers also provide an open-source calibration toolbox with an interactive visualization interface, making it easier for researchers and practitioners to work with their system. Additionally, they have published three real-world datasets captured in various indoor and outdoor environments, which can be used to evaluate LCEC methods.
Through extensive experiments on these real-world datasets, the researchers demonstrate the robustness and superior performance of their MIAS-LCEC approach, particularly when dealing with solid-state LiDARs that have super-wide fields of view. This is a significant advancement over previous state-of-the-art LCEC methods that struggled in such challenging scenarios.
Critical Analysis
The paper acknowledges that while the MIAS-LCEC framework provides a robust and accurate solution for online, target-free LCEC, there are still some limitations and areas for further research. For example, the authors mention that the performance of the C3M algorithm may degrade in scenarios with significant occlusions or when the LiDAR and camera have vastly different fields of view.
Additionally, the reliance on large vision models, while providing powerful capabilities, also introduces some potential concerns. These models can be computationally intensive, requiring significant resources to deploy, and their inner workings can be opaque, making it difficult to understand and troubleshoot any issues that may arise.
Further research could explore ways to improve the generalization and robustness of the C3M algorithm, perhaps by incorporating additional contextual information or developing more efficient neural network architectures. Investigating the use of zero-shot detection techniques to enhance the LCEC process may also be a promising avenue for exploration.
Conclusion
This paper presents a significant advancement in the field of LiDAR-camera extrinsic calibration, introducing the MIAS-LCEC framework that leverages the power of large vision models to achieve robust and accurate online, target-free calibration. By overcoming the limitations of previous approaches, this work paves the way for more reliable and adaptable data fusion in intelligent vehicles, ultimately contributing to the development of safer and more capable autonomous systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Automatic Target-Less Camera-LiDAR Calibration From Motion and Deep Point Correspondences
Kursat Petek, Niclas Vodisch, Johannes Meyer, Daniele Cattaneo, Abhinav Valada, Wolfram Burgard
0
0
Sensor setups of robotic platforms commonly include both camera and LiDAR as they provide complementary information. However, fusing these two modalities typically requires a highly accurate calibration between them. In this paper, we propose MDPCalib which is a novel method for camera-LiDAR calibration that requires neither human supervision nor any specific target objects. Instead, we utilize sensor motion estimates from visual and LiDAR odometry as well as deep learning-based 2D-pixel-to-3D-point correspondences that are obtained without in-domain retraining. We represent the camera-LiDAR calibration as a graph optimization problem and minimize the costs induced by constraints from sensor motion and point correspondences. In extensive experiments, we demonstrate that our approach yields highly accurate extrinsic calibration parameters and is robust to random initialization. Additionally, our approach generalizes to a wide range of sensor setups, which we demonstrate by employing it on various robotic platforms including a self-driving perception car, a quadruped robot, and a UAV. To make our calibration method publicly accessible, we release the code on our project website at http://calibration.cs.uni-freiburg.de.
4/29/2024

MULi-Ev: Maintaining Unperturbed LiDAR-Event Calibration
Mathieu Cocheteux, Julien Moreau, Franck Davoine
0
0
Despite the increasing interest in enhancing perception systems for autonomous vehicles, the online calibration between event cameras and LiDAR - two sensors pivotal in capturing comprehensive environmental information - remains unexplored. We introduce MULi-Ev, the first online, deep learning-based framework tailored for the extrinsic calibration of event cameras with LiDAR. This advancement is instrumental for the seamless integration of LiDAR and event cameras, enabling dynamic, real-time calibration adjustments that are essential for maintaining optimal sensor alignment amidst varying operational conditions. Rigorously evaluated against the real-world scenarios presented in the DSEC dataset, MULi-Ev not only achieves substantial improvements in calibration accuracy but also sets a new standard for integrating LiDAR with event cameras in mobile platforms. Our findings reveal the potential of MULi-Ev to bolster the safety, reliability, and overall performance of event-based perception systems in autonomous driving, marking a significant step forward in their real-world deployment and effectiveness.
5/29/2024

Multi-Modal Data-Efficient 3D Scene Understanding for Autonomous Driving
Lingdong Kong, Xiang Xu, Jiawei Ren, Wenwei Zhang, Liang Pan, Kai Chen, Wei Tsang Ooi, Ziwei Liu
0
0
Efficient data utilization is crucial for advancing 3D scene understanding in autonomous driving, where reliance on heavily human-annotated LiDAR point clouds challenges fully supervised methods. Addressing this, our study extends into semi-supervised learning for LiDAR semantic segmentation, leveraging the intrinsic spatial priors of driving scenes and multi-sensor complements to augment the efficacy of unlabeled datasets. We introduce LaserMix++, an evolved framework that integrates laser beam manipulations from disparate LiDAR scans and incorporates LiDAR-camera correspondences to further assist data-efficient learning. Our framework is tailored to enhance 3D scene consistency regularization by incorporating multi-modality, including 1) multi-modal LaserMix operation for fine-grained cross-sensor interactions; 2) camera-to-LiDAR feature distillation that enhances LiDAR feature learning; and 3) language-driven knowledge guidance generating auxiliary supervisions using open-vocabulary models. The versatility of LaserMix++ enables applications across LiDAR representations, establishing it as a universally applicable solution. Our framework is rigorously validated through theoretical analysis and extensive experiments on popular driving perception datasets. Results demonstrate that LaserMix++ markedly outperforms fully supervised alternatives, achieving comparable accuracy with five times fewer annotations and significantly improving the supervised-only baselines. This substantial advancement underscores the potential of semi-supervised approaches in reducing the reliance on extensive labeled data in LiDAR-based 3D scene understanding systems.
5/9/2024
MAD-ICP: It Is All About Matching Data -- Robust and Informed LiDAR Odometry
Simone Ferrari, Luca Di Giammarino, Leonardo Brizi, Giorgio Grisetti
0
0
LiDAR odometry is the task of estimating the ego-motion of the sensor from sequential laser scans. This problem has been addressed by the community for more than two decades, and many effective solutions are available nowadays. Most of these systems implicitly rely on assumptions about the operating environment, the sensor used, and motion pattern. When these assumptions are violated, several well-known systems tend to perform poorly. This paper presents a LiDAR odometry system that can overcome these limitations and operate well under different operating conditions while achieving performance comparable with domain-specific methods. Our algorithm follows the well-known ICP paradigm that leverages a PCA-based kd-tree implementation that is used to extract structural information about the clouds being registered and to compute the minimization metric for the alignment. The drift is bound by managing the local map based on the estimated uncertainty of the tracked pose. To benefit the community, we release an open-source C++ anytime real-time implementation.
5/10/2024